 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Ink: Componentwise Backward Error Attacks on Deep Learning
Paper and Code
Jun 05, 2023
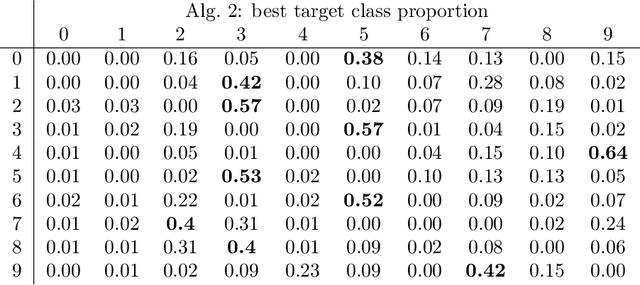
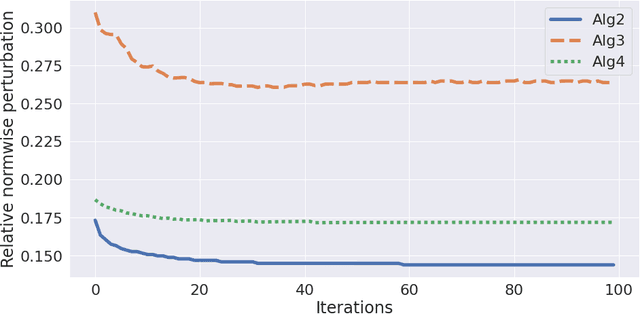
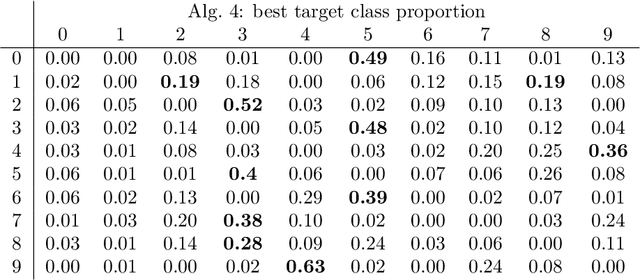
Deep neural networks are capable of state-of-the-art performance in many classification tasks. However, they are known to be vulnerable to adversarial attacks -- small perturbations to the input that lead to a change in classification. We address this issue from the perspective of backward error and condition number, concepts that have proved useful in numerical analysis. To do this, we build on the work of Beuzeville et al. (2021). In particular, we develop a new class of attack algorithms that use componentwise relative perturbations. Such attacks are highly relevant in the case of handwritten documents or printed texts where, for example, the classification of signatures, postcodes, dates or numerical quantities may be altered by changing only the ink consistency and not the background. This makes the perturbed images look natural to the naked eye. Such ``adversarial ink'' attacks therefore reveal a weakness that can have a serious impact on safety and security. We illustrate the new attacks on real data and contrast them with existing algorithms. We also study the use of a componentwise condition number to quantify vulnerability.