 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Latent Binary Encoding in Deep Neural Network Classifiers
Oct 12, 2023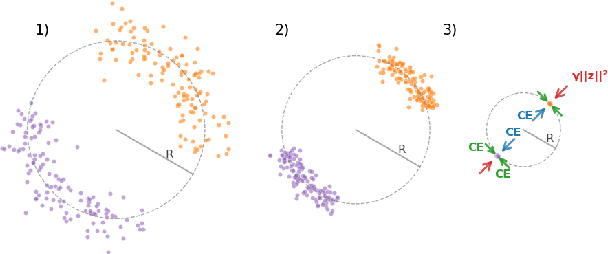
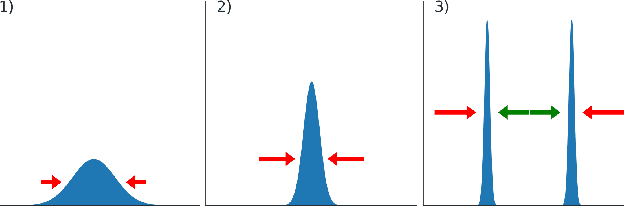
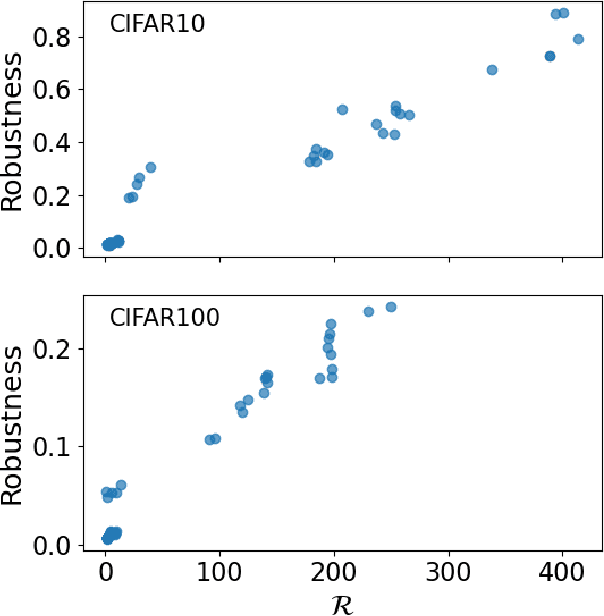
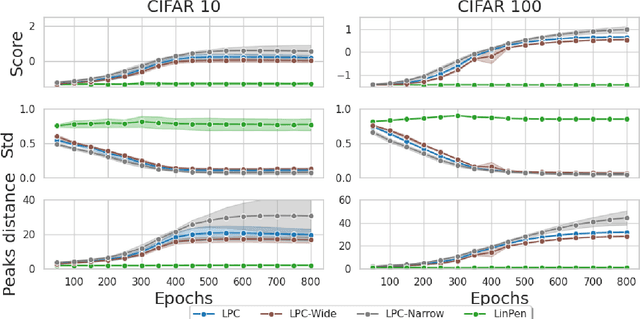
We observe the emergence of binary encoding within the latent space of deep-neural-network classifiers. Such binary encoding is induced by introducing a linear penultimate layer, which is equipped during training with a loss function that grows as $\exp(\vec{x}^2)$, where $\vec{x}$ are the coordinates in the latent space. The phenomenon we describe represents a specific instance of a well-documented occurrence known as \textit{neural collapse}, which arises in the terminal phase of training and entails the collapse of latent class means to the vertices of a simplex equiangular tight frame (ETF). We show that binary encoding accelerates convergence toward the simplex ETF and enhances classification accuracy.
Extrapolation to complete basis-set limit in density-functional theory by quantile random-forest models
Mar 31, 2023



The numerical precision of density-functional-theory (DFT) calculations depends on a variety of computational parameters, one of the most critical being the basis-set size. The ultimate precision is reached with an infinitely large basis set, i.e., in the limit of a complete basis set (CBS). Our aim in this work is to find a machine-learning model that extrapolates finite basis-size calculations to the CBS limit. We start with a data set of 63 binary solids investigated with two all-electron DFT codes, exciting and FHI-aims, which employ very different types of basis sets. A quantile-random-forest model is used to estimate the total-energy correction with respect to a fully converged calculation as a function of the basis-set size. The random-forest model achieves a symmetric mean absolute percentage error of lower than 25% for both codes and outperforms previous approaches in the literature. Our approach also provides prediction intervals, which quantify the uncertainty of the models' predictions.