 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA note on estimating the dimension from a random geometric graph
Nov 21, 2023Let $G_n$ be a random geometric graph with vertex set $[n]$ based on $n$ i.i.d.\ random vectors $X_1,\ldots,X_n$ drawn from an unknown density $f$ on $\R^d$. An edge $(i,j)$ is present when $\|X_i -X_j\| \le r_n$, for a given threshold $r_n$ possibly depending upon $n$, where $\| \cdot \|$ denotes Euclidean distance. We study the problem of estimating the dimension $d$ of the underlying space when we have access to the adjacency matrix of the graph but do not know $r_n$ or the vectors $X_i$. The main result of the paper is that there exists an estimator of $d$ that converges to $d$ in probability as $n \to \infty$ for all densities with $\int f^5 < \infty$ whenever $n^{3/2} r_n^d \to \infty$ and $r_n = o(1)$. The conditions allow very sparse graphs since when $n^{3/2} r_n^d \to 0$, the graph contains isolated edges only, with high probability. We also show that, without any condition on the density, a consistent estimator of $d$ exists when $n r_n^d \to \infty$ and $r_n = o(1)$.
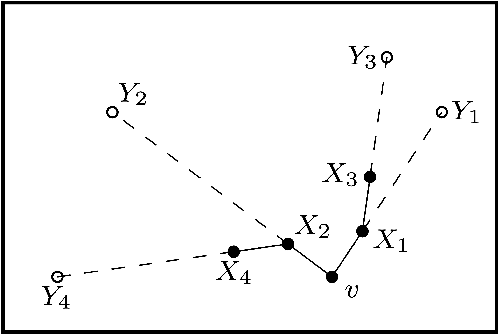
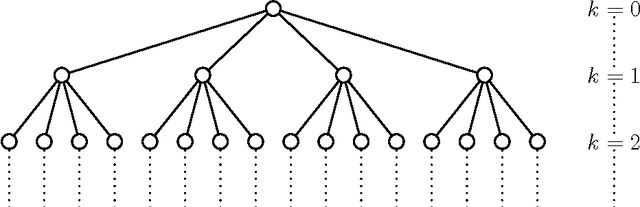
Broadcasting in random recursive dags
Jun 02, 2023



A uniform $k$-{\sc dag} generalizes the uniform random recursive tree by picking $k$ parents uniformly at random from the existing nodes. It starts with $k$ ''roots''. Each of the $k$ roots is assigned a bit. These bits are propagated by a noisy channel. The parents' bits are flipped with probability $p$, and a majority vote is taken. When all nodes have received their bits, the $k$-{\sc dag} is shown without identifying the roots. The goal is to estimate the majority bit among the roots. We identify the threshold for $p$ as a function of $k$ below which the majority rule among all nodes yields an error $c+o(1)$ with $c<1/2$. Above the threshold the majority rule errs with probability $1/2+o(1)$.
Consistent Density Estimation Under Discrete Mixture Models
May 10, 2021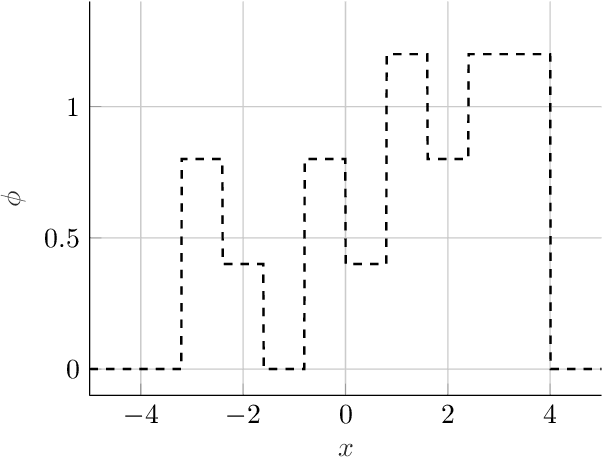
This work considers a problem of estimating a mixing probability density $f$ in the setting of discrete mixture models. The paper consists of three parts. The first part focuses on the construction of an $L_1$ consistent estimator of $f$. In particular, under the assumptions that the probability measure $\mu$ of the observation is atomic, and the map from $f$ to $\mu$ is bijective, it is shown that there exists an estimator $f_n$ such that for every density $f$ $\lim_{n\to \infty} \mathbb{E} \left[ \int |f_n -f | \right]=0$. The second part discusses the implementation details. Specifically, it is shown that the consistency for every $f$ can be attained with a computationally feasible estimator. The third part, as a study case, considers a Poisson mixture model. In particular, it is shown that in the Poisson noise setting, the bijection condition holds and, hence, estimation can be performed consistently for every $f$.
On Mean Estimation for Heteroscedastic Random Variables
Oct 22, 2020We study the problem of estimating the common mean $\mu$ of $n$ independent symmetric random variables with different and unknown standard deviations $\sigma_1 \le \sigma_2 \le \cdots \le\sigma_n$. We show that, under some mild regularity assumptions on the distribution, there is a fully adaptive estimator $\widehat{\mu}$ such that it is invariant to permutations of the elements of the sample and satisfies that, up to logarithmic factors, with high probability, \[ |\widehat{\mu} - \mu| \lesssim \min\left\{\sigma_{m^*}, \frac{\sqrt{n}}{\sum_{i = \sqrt{n}}^n \sigma_i^{-1}} \right\}~, \] where the index $m^* \lesssim \sqrt{n}$ satisfies $m^* \approx \sqrt{\sigma_{m^*}\sum_{i = m^*}^n\sigma_i^{-1}}$.
Probabilistic Analysis of RRT Trees
May 04, 2020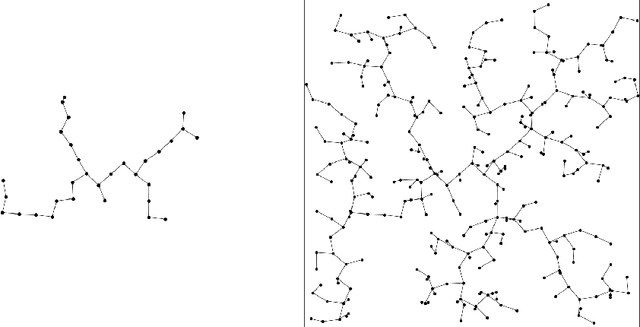


This thesis presents analysis of the properties and run-time of the Rapidly-exploring Random Tree (RRT) algorithm. It is shown that the time for the RRT with stepsize $\epsilon$ to grow close to every point in the $d$-dimensional unit cube is $\Theta\left(\frac1{\epsilon^d} \log \left(\frac1\epsilon\right)\right)$. Also, the time it takes for the tree to reach a region of positive probability is $O\left(\epsilon^{-\frac32}\right)$. Finally, a relationship is shown to the Nearest Neighbour Tree (NNT). This relationship shows that the total Euclidean path length after $n$ steps is $O(\sqrt n)$ and the expected height of the tree is bounded above by $(e + o(1)) \log n$.
Discrete minimax estimation with trees
Dec 14, 2018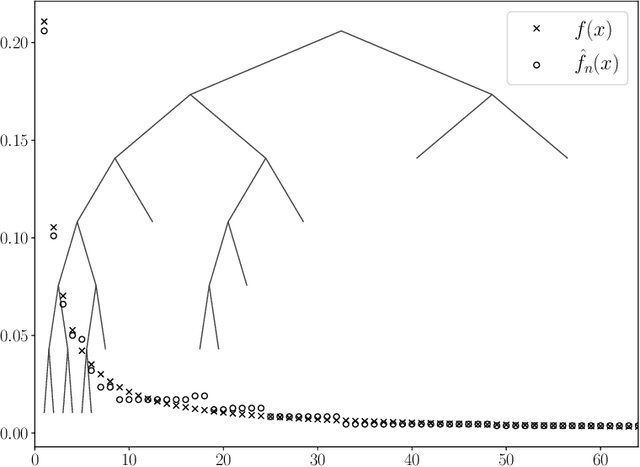
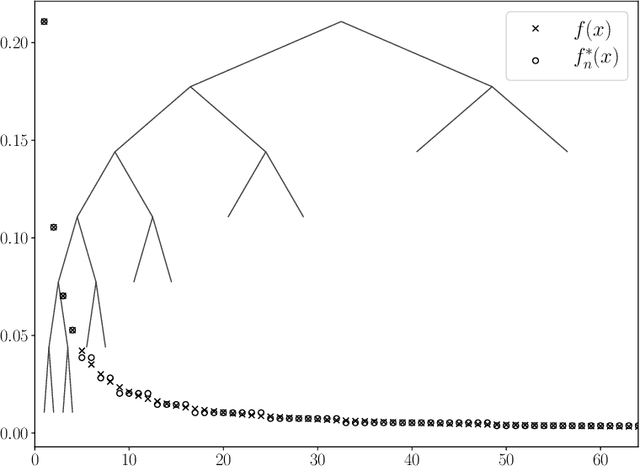

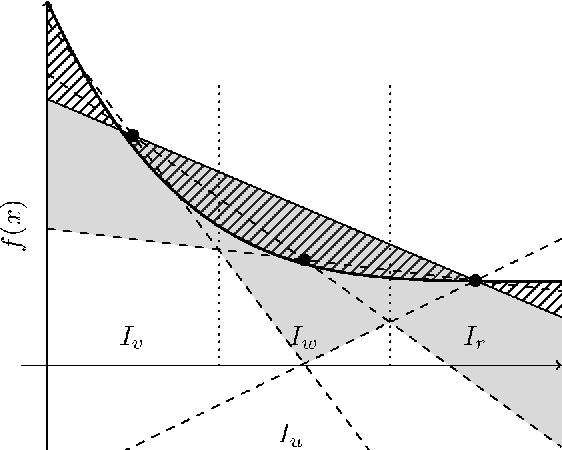
We propose a simple recursive data-based partitioning scheme which produces piecewise-constant or piecewise-linear density estimates on intervals, and show how this scheme can determine the optimal $L_1$ minimax rate for some discrete nonparametric classes.
The Minimax Learning Rate of Normal and Ising Undirected Graphical Models
Jun 18, 2018Let $G$ be an undirected graph with $m$ edges and $d$ vertices. We show that $d$-dimensional Ising models on $G$ can be learned from $n$ i.i.d. samples within expected total variation distance some constant factor of $\min\{1, \sqrt{(m + d)/n}\}$, and that this rate is optimal. We show that the same rate holds for the class of $d$-dimensional multivariate normal undirected graphical models with respect to $G$. We also identify the optimal rate of $\min\{1, \sqrt{m/n}\}$ for Ising models with no external magnetic field.
Cellular Tree Classifiers
Jun 25, 2013
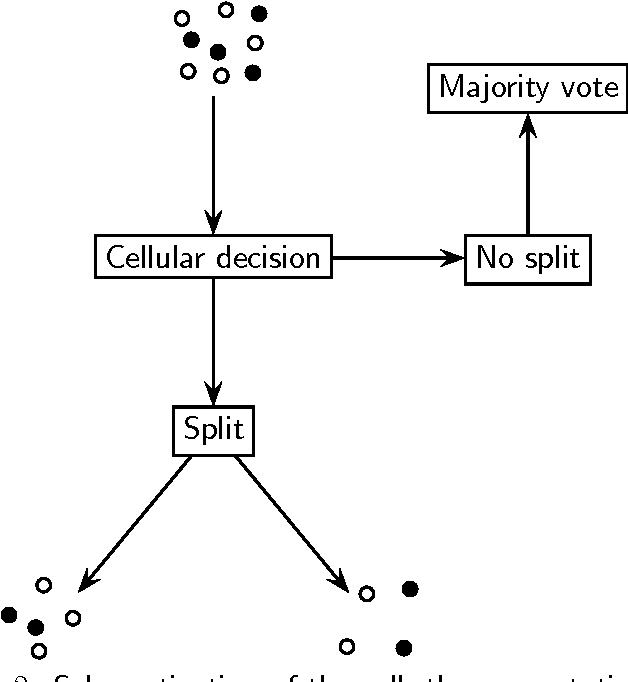
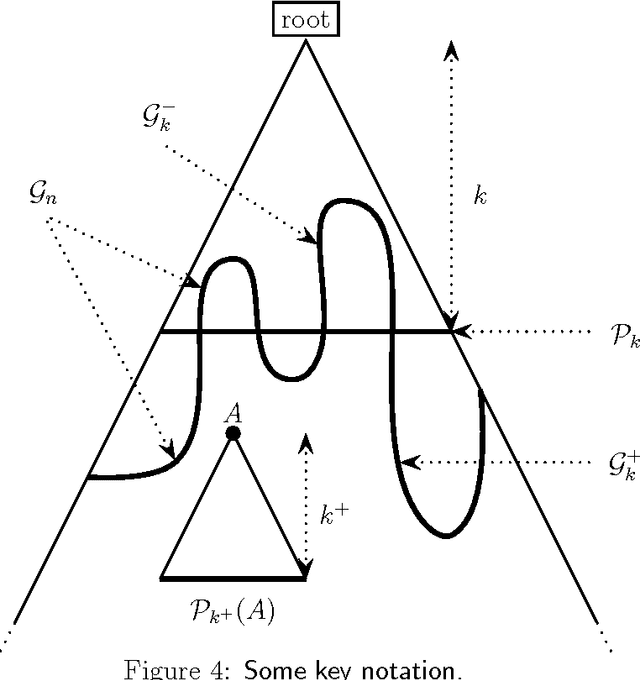
The cellular tree classifier model addresses a fundamental problem in the design of classifiers for a parallel or distributed computing world: Given a data set, is it sufficient to apply a majority rule for classification, or shall one split the data into two or more parts and send each part to a potentially different computer (or cell) for further processing? At first sight, it seems impossible to define with this paradigm a consistent classifier as no cell knows the "original data size", $n$. However, we show that this is not so by exhibiting two different consistent classifiers. The consistency is universal but is only shown for distributions with nonatomic marginals.
Prediction by Random-Walk Perturbation
Feb 23, 2013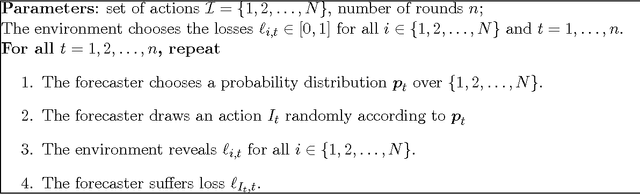
We propose a version of the follow-the-perturbed-leader online prediction algorithm in which the cumulative losses are perturbed by independent symmetric random walks. The forecaster is shown to achieve an expected regret of the optimal order O(sqrt(n log N)) where n is the time horizon and N is the number of experts. More importantly, it is shown that the forecaster changes its prediction at most O(sqrt(n log N)) times, in expectation. We also extend the analysis to online combinatorial optimization and show that even in this more general setting, the forecaster rarely switches between experts while having a regret of near-optimal order.