 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression Implies Generalization
Jul 01, 2021Explaining the surprising generalization performance of deep neural networks is an active and important line of research in theoretical machine learning. Influential work by Arora et al. (ICML'18) showed that, noise stability properties of deep nets occurring in practice can be used to provably compress model representations. They then argued that the small representations of compressed networks imply good generalization performance albeit only of the compressed nets. Extending their compression framework to yield generalization bounds for the original uncompressed networks remains elusive. Our main contribution is the establishment of a compression-based framework for proving generalization bounds. The framework is simple and powerful enough to extend the generalization bounds by Arora et al. to also hold for the original network. To demonstrate the flexibility of the framework, we also show that it allows us to give simple proofs of the strongest known generalization bounds for other popular machine learning models, namely Support Vector Machines and Boosting.
Margins are Insufficient for Explaining Gradient Boosting
Nov 10, 2020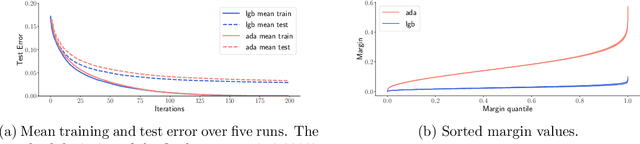
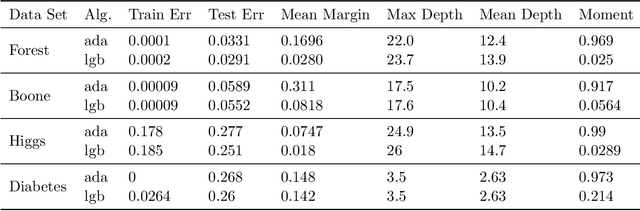
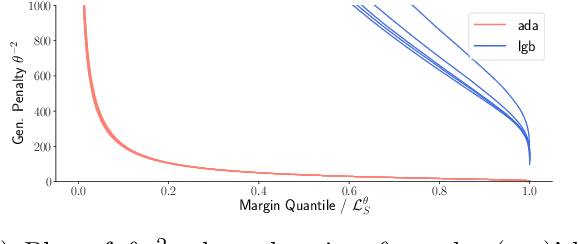
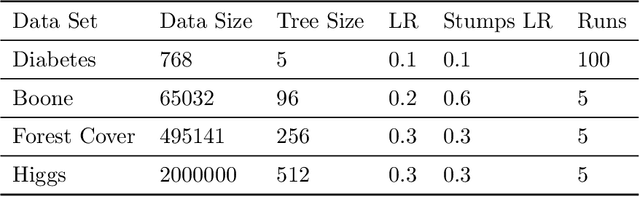
Boosting is one of the most successful ideas in machine learning, achieving great practical performance with little fine-tuning. The success of boosted classifiers is most often attributed to improvements in margins. The focus on margin explanations was pioneered in the seminal work by Schapire et al. (1998) and has culminated in the $k$'th margin generalization bound by Gao and Zhou (2013), which was recently proved to be near-tight for some data distributions (Gronlund et al. 2019). In this work, we first demonstrate that the $k$'th margin bound is inadequate in explaining the performance of state-of-the-art gradient boosters. We then explain the short comings of the $k$'th margin bound and prove a stronger and more refined margin-based generalization bound for boosted classifiers that indeed succeeds in explaining the performance of modern gradient boosters. Finally, we improve upon the recent generalization lower bound by Gr{\o}nlund et al. (2019).
Near-Tight Margin-Based Generalization Bounds for Support Vector Machines
Jun 03, 2020Support Vector Machines (SVMs) are among the most fundamental tools for binary classification. In its simplest formulation, an SVM produces a hyperplane separating two classes of data using the largest possible margin to the data. The focus on maximizing the margin has been well motivated through numerous generalization bounds. In this paper, we revisit and improve the classic generalization bounds in terms of margins. Furthermore, we complement our new generalization bound by a nearly matching lower bound, thus almost settling the generalization performance of SVMs in terms of margins.
Margin-Based Generalization Lower Bounds for Boosted Classifiers
Sep 30, 2019Boosting is one of the most successful ideas in machine learning. The most well-accepted explanations for the low generalization error of boosting algorithms such as AdaBoost stem from margin theory. The study of margins in the context of boosting algorithms was initiated by Schapire, Freund, Bartlett and Lee (1998) and has inspired numerous boosting algorithms and generalization bounds. To date, the strongest known generalization (upper bound) is the $k$th margin bound of Gao and Zhou (2013). Despite the numerous generalization upper bounds that have been proved over the last two decades, nothing is known about the tightness of these bounds. In this paper, we give the first margin-based lower bounds on the generalization error of boosted classifiers. Our lower bounds nearly match the $k$th margin bound and thus almost settle the generalization performance of boosted classifiers in terms of margins.
Fully Understanding the Hashing Trick
May 22, 2018

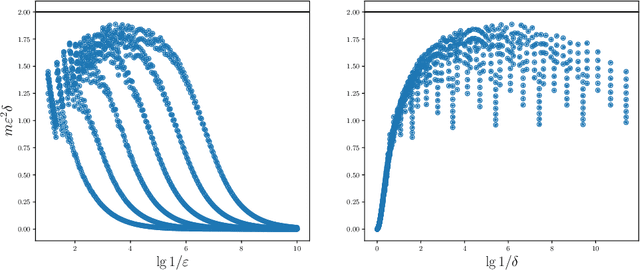
Feature hashing, also known as {\em the hashing trick}, introduced by Weinberger et al. (2009), is one of the key techniques used in scaling-up machine learning algorithms. Loosely speaking, feature hashing uses a random sparse projection matrix $A : \mathbb{R}^n \to \mathbb{R}^m$ (where $m \ll n$) in order to reduce the dimension of the data from $n$ to $m$ while approximately preserving the Euclidean norm. Every column of $A$ contains exactly one non-zero entry, equals to either $-1$ or $1$. Weinberger et al. showed tail bounds on $\|Ax\|_2^2$. Specifically they showed that for every $\varepsilon, \delta$, if $\|x\|_{\infty} / \|x\|_2$ is sufficiently small, and $m$ is sufficiently large, then $$\Pr[ \; | \;\|Ax\|_2^2 - \|x\|_2^2\; | < \varepsilon \|x\|_2^2 \;] \ge 1 - \delta \;.$$ These bounds were later extended by Dasgupta \etal (2010) and most recently refined by Dahlgaard et al. (2017), however, the true nature of the performance of this key technique, and specifically the correct tradeoff between the pivotal parameters $\|x\|_{\infty} / \|x\|_2, m, \varepsilon, \delta$ remained an open question. We settle this question by giving tight asymptotic bounds on the exact tradeoff between the central parameters, thus providing a complete understanding of the performance of feature hashing. We complement the asymptotic bound with empirical data, which shows that the constants "hiding" in the asymptotic notation are, in fact, very close to $1$, thus further illustrating the tightness of the presented bounds in practice.