 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMargins are Insufficient for Explaining Gradient Boosting
Paper and Code
Nov 10, 2020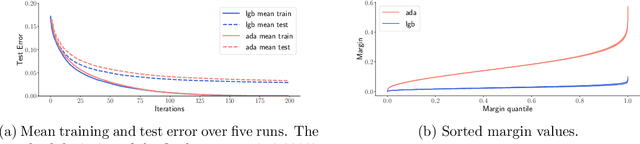
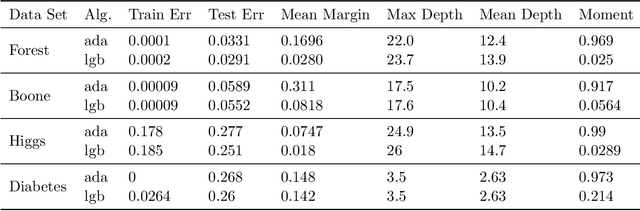
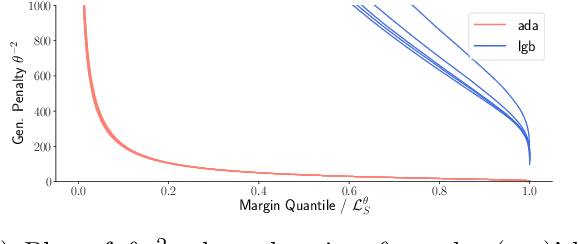
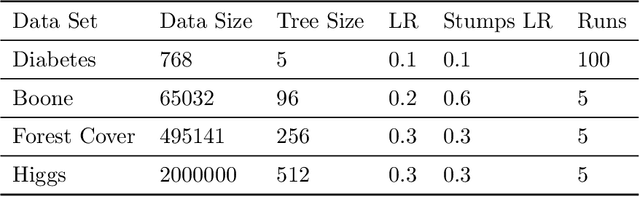
Boosting is one of the most successful ideas in machine learning, achieving great practical performance with little fine-tuning. The success of boosted classifiers is most often attributed to improvements in margins. The focus on margin explanations was pioneered in the seminal work by Schapire et al. (1998) and has culminated in the $k$'th margin generalization bound by Gao and Zhou (2013), which was recently proved to be near-tight for some data distributions (Gronlund et al. 2019). In this work, we first demonstrate that the $k$'th margin bound is inadequate in explaining the performance of state-of-the-art gradient boosters. We then explain the short comings of the $k$'th margin bound and prove a stronger and more refined margin-based generalization bound for boosted classifiers that indeed succeeds in explaining the performance of modern gradient boosters. Finally, we improve upon the recent generalization lower bound by Gr{\o}nlund et al. (2019).