 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuYun-LDM: A Latent Diffusion Model for High-Resolution Ensemble Weather Forecasts
Feb 13, 2026Latent diffusion models (LDMs) suffer from limited diffusability in high-resolution (<=0.25°) ensemble weather forecasting, where diffusability characterizes how easily a latent data distribution can be modeled by a diffusion process. Unlike natural image fields, meteorological fields lack task-agnostic foundation models and explicit semantic structures, making VFM-based regularization inapplicable. Moreover, existing frequency-based approaches impose identical spectral regularization across channels under a homogeneity assumption, which leads to uneven regularization strength under the inter-variable spectral heterogeneity in multivariate meteorological data. To address these challenges, we propose a 3D Masked AutoEncoder (3D-MAE) that encodes weather-state evolution features as an additional conditioning for the diffusion model, together with a Variable-Aware Masked Frequency Modeling (VA-MFM) strategy that adaptively selects thresholds based on the spectral energy distribution of each variable. Together, we propose PuYun-LDM, which enhances latent diffusability and achieves superior performance to ENS at short lead times while remaining comparable to ENS at longer horizons. PuYun-LDM generates a 15-day global forecast with a 6-hour temporal resolution in five minutes on a single NVIDIA H200 GPU, while ensemble forecasts can be efficiently produced in parallel.
XS-VID: An Extremely Small Video Object Detection Dataset
Jul 25, 2024

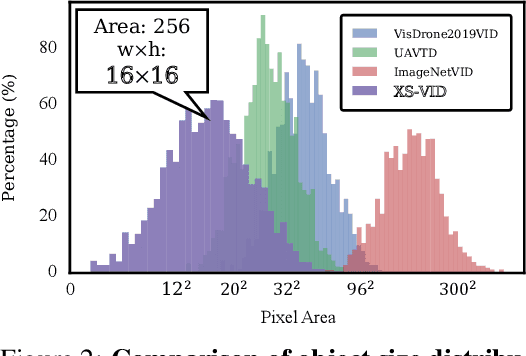
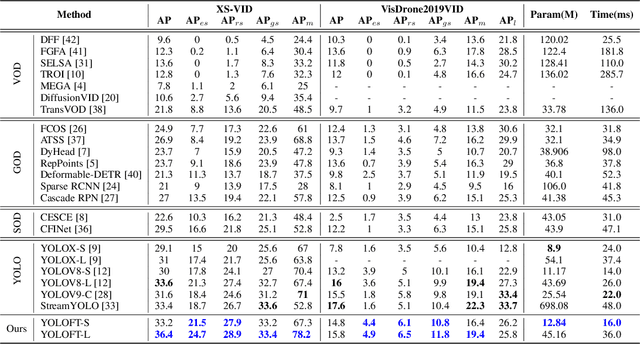
Small Video Object Detection (SVOD) is a crucial subfield in modern computer vision, essential for early object discovery and detection. However, existing SVOD datasets are scarce and suffer from issues such as insufficiently small objects, limited object categories, and lack of scene diversity, leading to unitary application scenarios for corresponding methods. To address this gap, we develop the XS-VID dataset, which comprises aerial data from various periods and scenes, and annotates eight major object categories. To further evaluate existing methods for detecting extremely small objects, XS-VID extensively collects three types of objects with smaller pixel areas: extremely small (\textit{es}, $0\sim12^2$), relatively small (\textit{rs}, $12^2\sim20^2$), and generally small (\textit{gs}, $20^2\sim32^2$). XS-VID offers unprecedented breadth and depth in covering and quantifying minuscule objects, significantly enriching the scene and object diversity in the dataset. Extensive validations on XS-VID and the publicly available VisDrone2019VID dataset show that existing methods struggle with small object detection and significantly underperform compared to general object detectors. Leveraging the strengths of previous methods and addressing their weaknesses, we propose YOLOFT, which enhances local feature associations and integrates temporal motion features, significantly improving the accuracy and stability of SVOD. Our datasets and benchmarks are available at \url{https://gjhhust.github.io/XS-VID/}.
Modeling and Simulation of Robotic Finger Powered by Nylon Artificial Muscles- Equations with Simulink model
Jan 28, 2019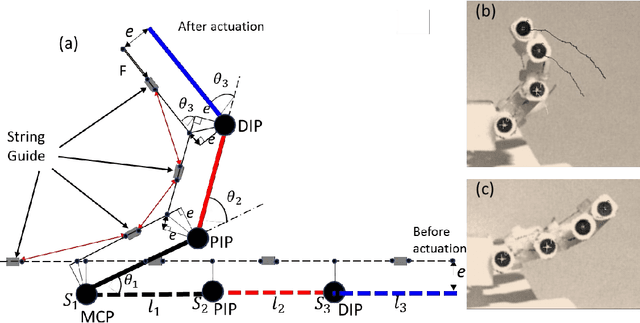
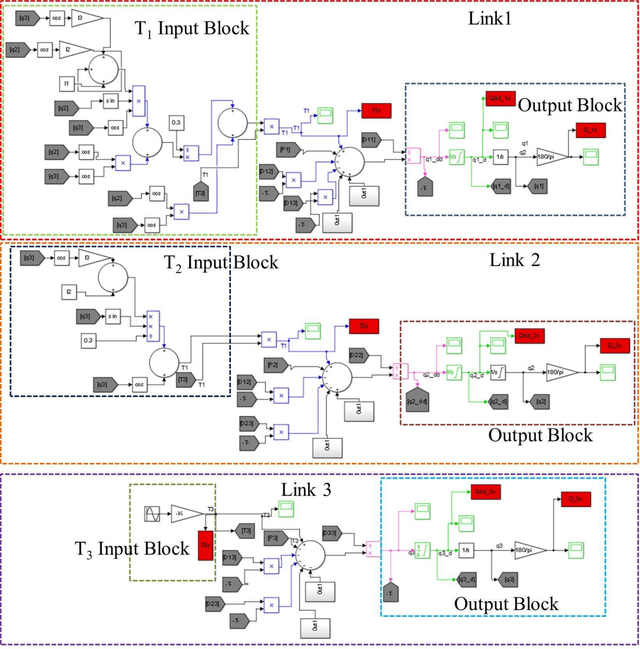
This paper shows a detailed modeling of three-link robotic finger that is actuated by nylon artificial muscles and a simulink model that can be used for numerical study of a robotic finger. The robotic hand prototype was recently demonstrated in recent publication Wu, L., Jung de Andrade, M., Saharan, L.,Rome, R., Baughman, R., and Tadesse, Y., 2017, Compact and Low-cost Humanoid Hand Powered by Nylon Artificial Muscles, Bioinspiration & Biomimetics, 12 (2). The robotic hand is a 3D printed, lightweight and compact hand actuated by silver-coated nylon muscles, often called Twisted and coiled Polymer (TCP) muscles. TCP muscles are thermal actuators that contract when they are heated and they are getting attention for application in robotics. The purpose of this paper is to demonstrate the modeling equations that were derived based on Euler Lagrangian approach that is suitable for implementation in simulink model.