 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Monocular SLAM-based Multi-User Positioning System with Image Occlusion in Augmented Reality
Nov 17, 2024



In recent years, with the rapid development of augmented reality (AR) technology, there is an increasing demand for multi-user collaborative experiences. Unlike for single-user experiences, ensuring the spatial localization of every user and maintaining synchronization and consistency of positioning and orientation across multiple users is a significant challenge. In this paper, we propose a multi-user localization system based on ORB-SLAM2 using monocular RGB images as a development platform based on the Unity 3D game engine. This system not only performs user localization but also places a common virtual object on a planar surface (such as table) in the environment so that every user holds a proper perspective view of the object. These generated virtual objects serve as reference points for multi-user position synchronization. The positioning information is passed among every user's AR devices via a central server, based on which the relative position and movement of other users in the space of a specific user are presented via virtual avatars all with respect to these virtual objects. In addition, we use deep learning techniques to estimate the depth map of an image from a single RGB image to solve occlusion problems in AR applications, making virtual objects appear more natural in AR scenes.
VPFNet: Voxel-Pixel Fusion Network for Multi-class 3D Object Detection
Nov 01, 2021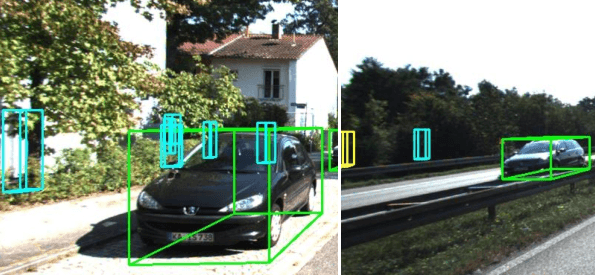
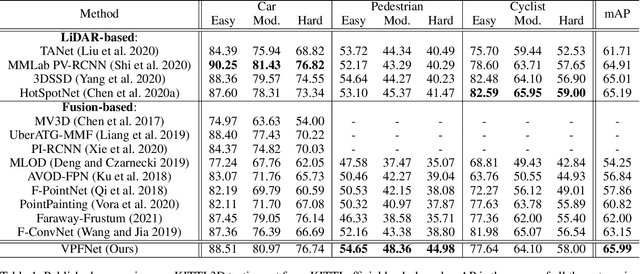
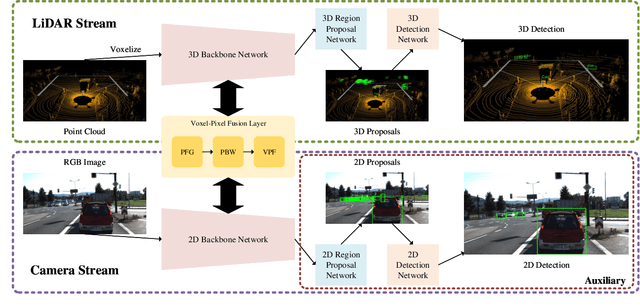

Many LiDAR-based methods for detecting large objects, single-class object detection, or under easy situations were claimed to perform quite well. However, their performances of detecting small objects or under hard situations did not surpass those of the fusion-based ones due to failure to leverage the image semantics. In order to elevate the detection performance in a complicated environment, this paper proposes a deep learning (DL)-embedded fusion-based multi-class 3D object detection network which admits both LiDAR and camera sensor data streams, named Voxel-Pixel Fusion Network (VPFNet). Inside this network, a key novel component is called Voxel-Pixel Fusion (VPF) layer, which takes advantage of the geometric relation of a voxel-pixel pair and fuses the voxel features and the pixel features with proper mechanisms. Moreover, several parameters are particularly designed to guide and enhance the fusion effect after considering the characteristics of a voxel-pixel pair. Finally, the proposed method is evaluated on the KITTI benchmark for multi-class 3D object detection task under multilevel difficulty, and is shown to outperform all state-of-the-art methods in mean average precision (mAP). It is also noteworthy that our approach here ranks the first on the KITTI leaderboard for the challenging pedestrian class.
Parallelized Reverse Curriculum Generation
Aug 04, 2021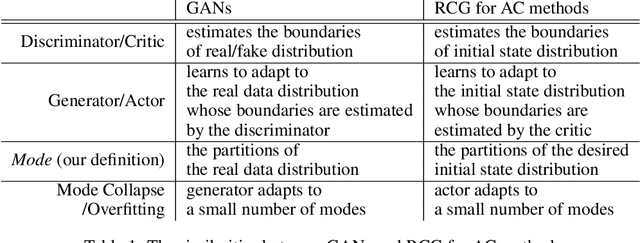
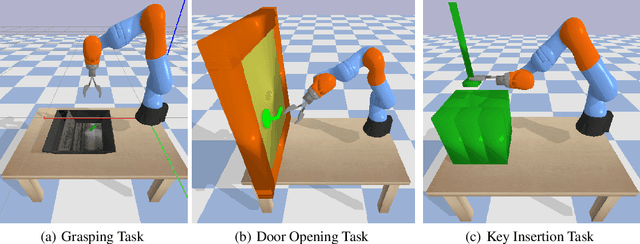
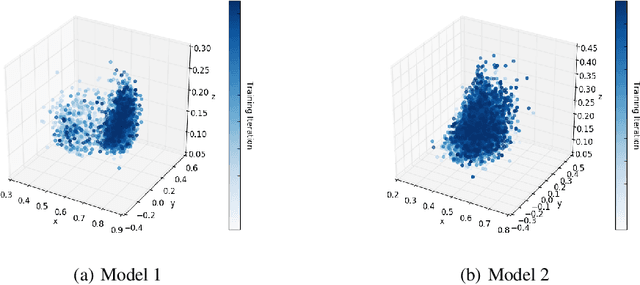

For reinforcement learning (RL), it is challenging for an agent to master a task that requires a specific series of actions due to sparse rewards. To solve this problem, reverse curriculum generation (RCG) provides a reverse expansion approach that automatically generates a curriculum for the agent to learn. More specifically, RCG adapts the initial state distribution from the neighborhood of a goal to a distance as training proceeds. However, the initial state distribution generated for each iteration might be biased, thus making the policy overfit or slowing down the reverse expansion rate. While training RCG for actor-critic (AC) based RL algorithms, this poor generalization and slow convergence might be induced by the tight coupling between an AC pair. Therefore, we propose a parallelized approach that simultaneously trains multiple AC pairs and periodically exchanges their critics. We empirically demonstrate that this proposed approach can improve RCG in performance and convergence, and it can also be applied to other AC based RL algorithms with adapted initial state distribution.
SE-PSNet: Silhouette-based Enhancement Feature for Panoptic Segmentation Network
Jul 11, 2021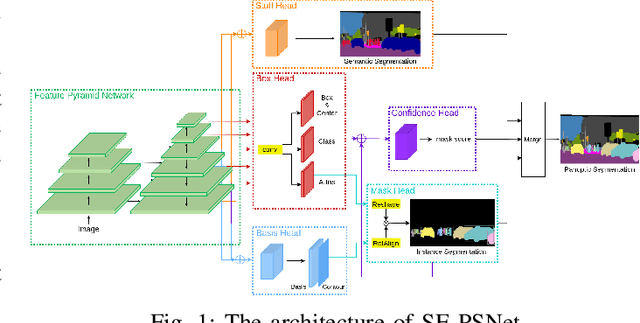


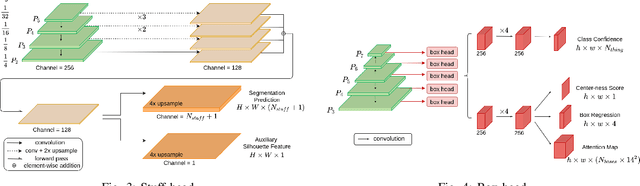
Recently, there has been a panoptic segmentation task combining semantic and instance segmentation, in which the goal is to classify each pixel with the corresponding instance ID. In this work, we propose a solution to tackle the panoptic segmentation task. The overall structure combines the bottom-up method and the top-down method. Therefore, not only can there be better performance, but also the execution speed can be maintained. The network mainly pays attention to the quality of the mask. In the previous work, we can see that the uneven contour of the object is more likely to appear, resulting in low-quality prediction. Accordingly, we propose enhancement features and corresponding loss functions for the silhouette of objects and backgrounds to improve the mask. Meanwhile, we use the new proposed confidence score to solve the occlusion problem and make the network tend to use higher quality masks as prediction results. To verify our research, we used the COCO dataset and CityScapes dataset to do experiments and obtained competitive results with fast inference time.
EPSNet: Efficient Panoptic Segmentation Network with Cross-layer Attention Fusion
Mar 23, 2020



Panoptic segmentation is a scene parsing task which unifies semantic segmentation and instance segmentation into one single task. However, the current state-of-the-art studies did not take too much concern on inference time. In this work, we propose an Efficient Panoptic Segmentation Network (EPSNet) to tackle the panoptic segmentation tasks with fast inference speed. Basically, EPSNet generates masks based on simple linear combination of prototype masks and mask coefficients. The light-weight network branches for instance segmentation and semantic segmentation only need to predict mask coefficients and produce masks with the shared prototypes predicted by prototype network branch. Furthermore, to enhance the quality of shared prototypes, we adopt a module called "cross-layer attention fusion module", which aggregates the multi-scale features with attention mechanism helping them capture the long-range dependencies between each other. To validate the proposed work, we have conducted various experiments on the challenging COCO panoptic dataset, which achieve highly promising performance with significantly faster inference speed (53ms on GPU).