 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPFNet: Voxel-Pixel Fusion Network for Multi-class 3D Object Detection
Paper and Code
Nov 01, 2021
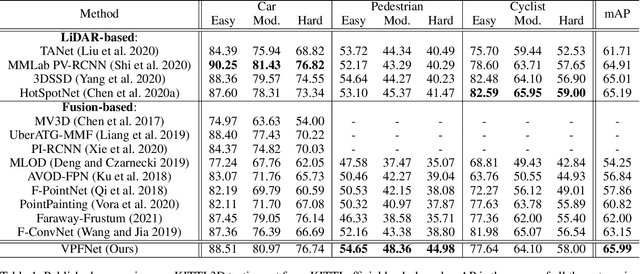
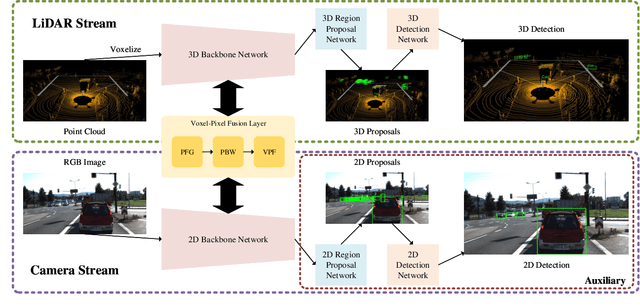

Many LiDAR-based methods for detecting large objects, single-class object detection, or under easy situations were claimed to perform quite well. However, their performances of detecting small objects or under hard situations did not surpass those of the fusion-based ones due to failure to leverage the image semantics. In order to elevate the detection performance in a complicated environment, this paper proposes a deep learning (DL)-embedded fusion-based multi-class 3D object detection network which admits both LiDAR and camera sensor data streams, named Voxel-Pixel Fusion Network (VPFNet). Inside this network, a key novel component is called Voxel-Pixel Fusion (VPF) layer, which takes advantage of the geometric relation of a voxel-pixel pair and fuses the voxel features and the pixel features with proper mechanisms. Moreover, several parameters are particularly designed to guide and enhance the fusion effect after considering the characteristics of a voxel-pixel pair. Finally, the proposed method is evaluated on the KITTI benchmark for multi-class 3D object detection task under multilevel difficulty, and is shown to outperform all state-of-the-art methods in mean average precision (mAP). It is also noteworthy that our approach here ranks the first on the KITTI leaderboard for the challenging pedestrian class.