 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClip Your Sequences Fairly: Enforcing Length Fairness for Sequence-Level RL
Sep 11, 2025


We propose FSPO (Fair Sequence Policy Optimization), a sequence-level reinforcement learning method for LLMs that enforces length-fair clipping directly in the importance-sampling (IS) weight space. We revisit sequence-level RL methods and identify a mismatch when PPO/GRPO-style clipping is transplanted to sequences: a fixed clip range systematically reweights short vs. long responses, distorting the effective objective. Theoretically, we formalize length fairness via a Length Reweighting Error (LRE) and prove that small LRE yields a directional cosine guarantee between the clipped and true updates. FSPO introduces a simple, Gaussian-motivated remedy: we clip the sequence log-IS ratio with a band that applies a KL-corrected drift term and scales as $\sqrt{L}$. Empirically, FSPO flattens clip rates across length bins, stabilizes training, and outperforms all baselines across multiple evaluation datasets.
In2x at WMT25 Translation Task
Aug 20, 2025This paper presents the open-system submission by the In2x research team for the WMT25 General Machine Translation Shared Task. Our submission focuses on Japanese-related translation tasks, aiming to explore a generalizable paradigm for extending large language models (LLMs) to other languages. This paradigm encompasses aspects such as data construction methods and reward model design. The ultimate goal is to enable large language model systems to achieve exceptional performance in low-resource or less commonly spoken languages.
Adaptive Split-Fusion Transformer
Apr 26, 2022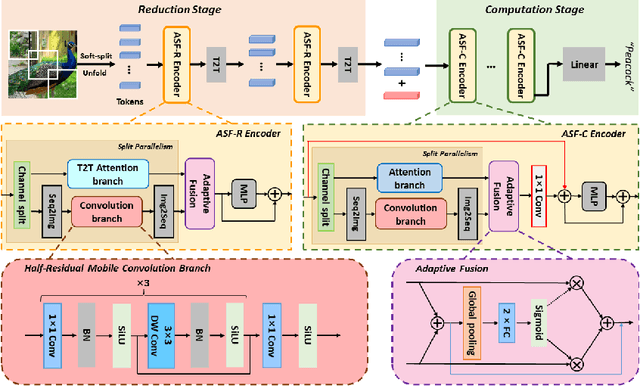


Neural networks for visual content understanding have recently evolved from convolutional ones (CNNs) to transformers. The prior (CNN) relies on small-windowed kernels to capture the regional clues, demonstrating solid local expressiveness. On the contrary, the latter (transformer) establishes long-range global connections between localities for holistic learning. Inspired by this complementary nature, there is a growing interest in designing hybrid models to best utilize each technique. Current hybrids merely replace convolutions as simple approximations of linear projection or juxtapose a convolution branch with attention, without concerning the importance of local/global modeling. To tackle this, we propose a new hybrid named Adaptive Split-Fusion Transformer (ASF-former) to treat convolutional and attention branches differently with adaptive weights. Specifically, an ASF-former encoder equally splits feature channels into half to fit dual-path inputs. Then, the outputs of dual-path are fused with weighting scalars calculated from visual cues. We also design the convolutional path compactly for efficiency concerns. Extensive experiments on standard benchmarks, such as ImageNet-1K, CIFAR-10, and CIFAR-100, show that our ASF-former outperforms its CNN, transformer counterparts, and hybrid pilots in terms of accuracy (83.9% on ImageNet-1K), under similar conditions (12.9G MACs/56.7M Params, without large-scale pre-training). The code is available at: https://github.com/szx503045266/ASF-former.
Neural Architecture Refinement: A Practical Way for Avoiding Overfitting in NAS
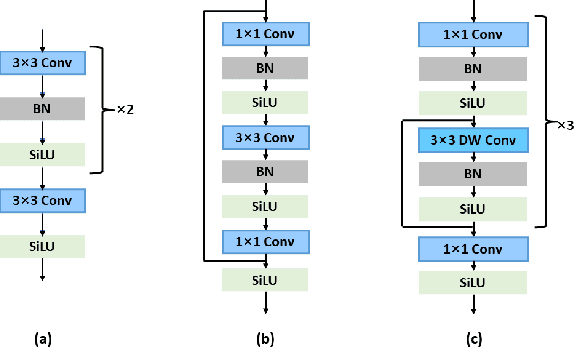
May 07, 2019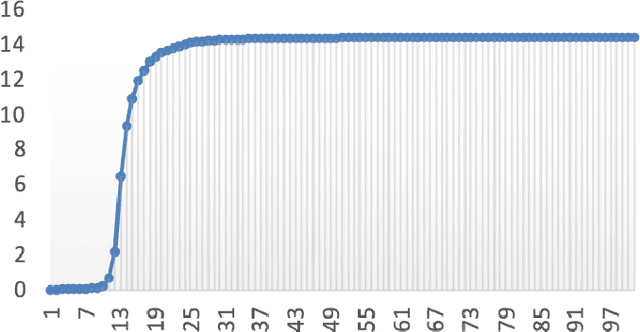
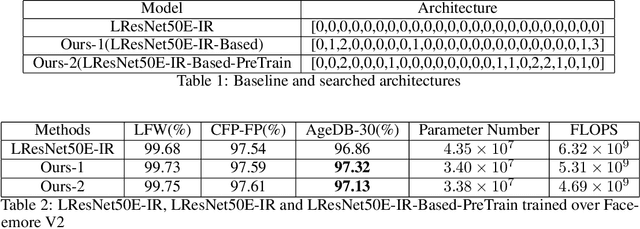

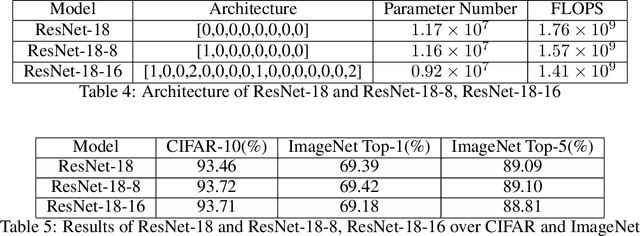
Neural architecture search (NAS) is proposed to automate the architecture design process and attracts overwhelming interest from both academia and industry. However, it is confronted with overfitting issue due to the high-dimensional search space composed by $operator$ selection and $skip$ connection of each layer. This paper analyzes the overfitting issue from a novel perspective, which separates the primitives of search space into architecture-overfitting related and parameter-overfitting related elements. The $operator$ of each layer, which mainly contributes to parameter-overfitting and is important for model acceleration, is selected as our optimization target based on state-of-the-art architecture, meanwhile $skip$ which related to architecture-overfitting, is ignored. With the largely reduced search space, our proposed method is both quick to converge and practical to use in various tasks. Extensive experiments have demonstrated that the proposed method can achieve fascinated results, including classification, face recognition etc.