 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Paraphrases to Study Properties of Contextual Embeddings
Jul 12, 2022
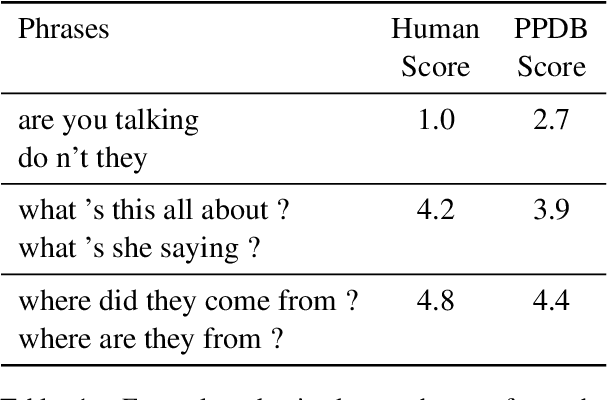

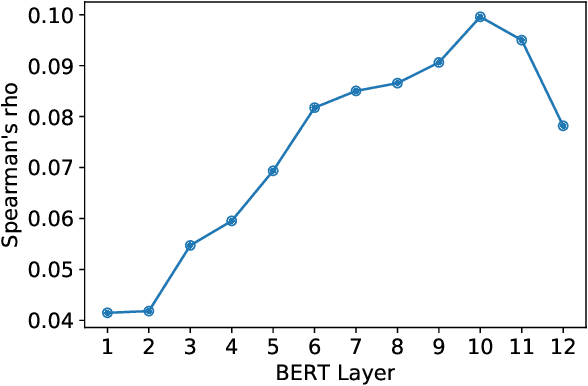
We use paraphrases as a unique source of data to analyze contextualized embeddings, with a particular focus on BERT. Because paraphrases naturally encode consistent word and phrase semantics, they provide a unique lens for investigating properties of embeddings. Using the Paraphrase Database's alignments, we study words within paraphrases as well as phrase representations. We find that contextual embeddings effectively handle polysemous words, but give synonyms surprisingly different representations in many cases. We confirm previous findings that BERT is sensitive to word order, but find slightly different patterns than prior work in terms of the level of contextualization across BERT's layers.
Analyzing the Surprising Variability in Word Embedding Stability Across Languages
Apr 30, 2020
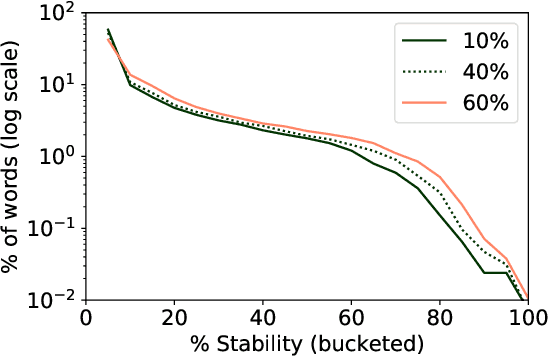
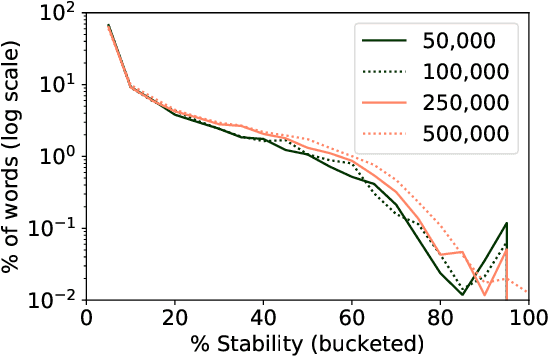
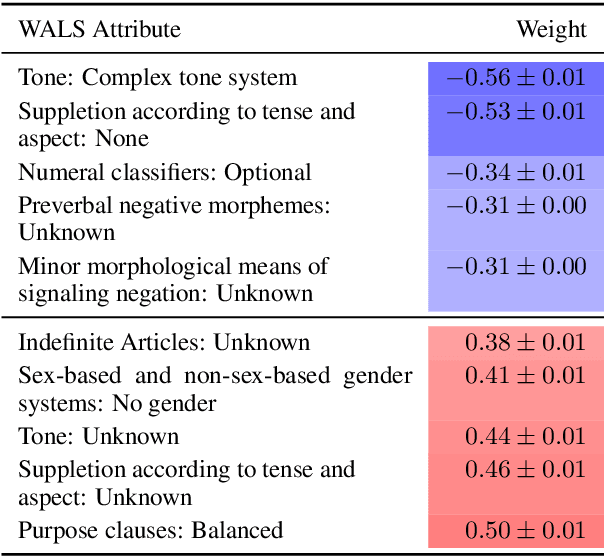
Word embeddings are powerful representations that form the foundation of many natural language processing architectures and tasks, both in English and in other languages. To gain further insight into word embeddings in multiple languages, we explore their stability, defined as the overlap between the nearest neighbors of a word in different embedding spaces. We discuss linguistic properties that are related to stability, drawing out insights about how morphological and other features relate to stability. This has implications for the usage of embeddings, particularly in research that uses embeddings to study language trends.
Identifying Visible Actions in Lifestyle Vlogs
Jun 10, 2019


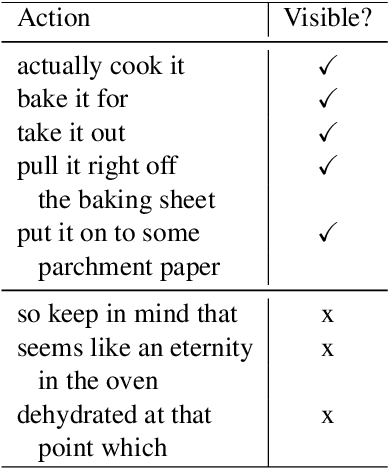
We consider the task of identifying human actions visible in online videos. We focus on the widely spread genre of lifestyle vlogs, which consist of videos of people performing actions while verbally describing them. Our goal is to identify if actions mentioned in the speech description of a video are visually present. We construct a dataset with crowdsourced manual annotations of visible actions, and introduce a multimodal algorithm that leverages information derived from visual and linguistic clues to automatically infer which actions are visible in a video. We demonstrate that our multimodal algorithm outperforms algorithms based only on one modality at a time.