Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Paraphrases to Study Properties of Contextual Embeddings
Paper and Code
Jul 12, 2022
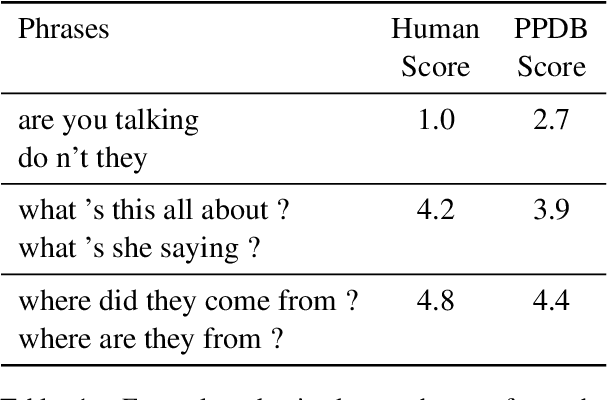

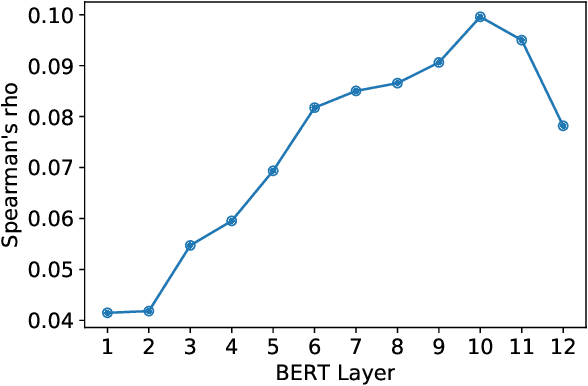
We use paraphrases as a unique source of data to analyze contextualized embeddings, with a particular focus on BERT. Because paraphrases naturally encode consistent word and phrase semantics, they provide a unique lens for investigating properties of embeddings. Using the Paraphrase Database's alignments, we study words within paraphrases as well as phrase representations. We find that contextual embeddings effectively handle polysemous words, but give synonyms surprisingly different representations in many cases. We confirm previous findings that BERT is sensitive to word order, but find slightly different patterns than prior work in terms of the level of contextualization across BERT's layers.
* Published at NAACL 2022
View paper on