 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Robotic Reinforcement Learning without Reward Engineering
May 16, 2019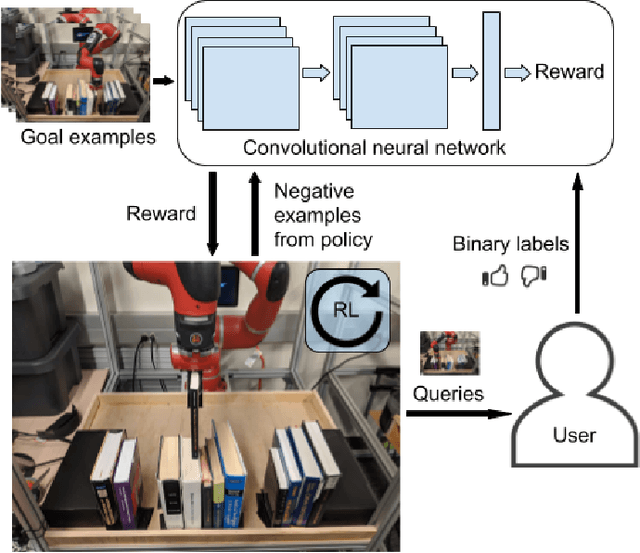
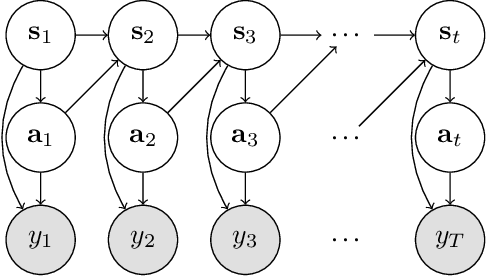
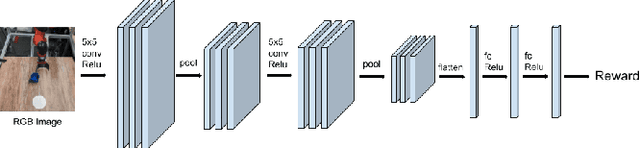

The combination of deep neural network models and reinforcement learning algorithms can make it possible to learn policies for robotic behaviors that directly read in raw sensory inputs, such as camera images, effectively subsuming both estimation and control into one model. However, real-world applications of reinforcement learning must specify the goal of the task by means of a manually programmed reward function, which in practice requires either designing the very same perception pipeline that end-to-end reinforcement learning promises to avoid, or else instrumenting the environment with additional sensors to determine if the task has been performed successfully. In this paper, we propose an approach for removing the need for manual engineering of reward specifications by enabling a robot to learn from a modest number of examples of successful outcomes, followed by actively solicited queries, where the robot shows the user a state and asks for a label to determine whether that state represents successful completion of the task. While requesting labels for every single state would amount to asking the user to manually provide the reward signal, our method requires labels for only a tiny fraction of the states seen during training, making it an efficient and practical approach for learning skills without manually engineered rewards. We evaluate our method on real-world robotic manipulation tasks where the observations consist of images viewed by the robot's camera. In our experiments, our method effectively learns to arrange objects, place books, and drape cloth, directly from images and without any manually specified reward functions, and with only 1-4 hours of interaction with the real world.
Variational Inverse Control with Events: A General Framework for Data-Driven Reward Definition
May 31, 2018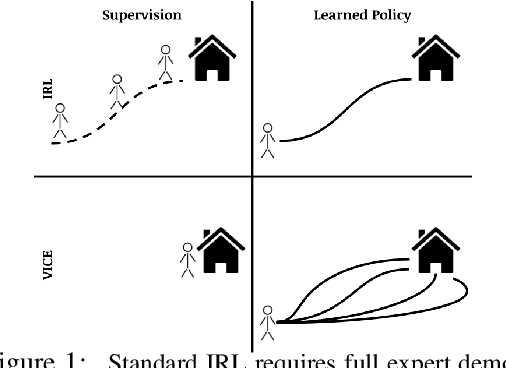



The design of a reward function often poses a major practical challenge to real-world applications of reinforcement learning. Approaches such as inverse reinforcement learning attempt to overcome this challenge, but require expert demonstrations, which can be difficult or expensive to obtain in practice. We propose variational inverse control with events (VICE), which generalizes inverse reinforcement learning methods to cases where full demonstrations are not needed, such as when only samples of desired goal states are available. Our method is grounded in an alternative perspective on control and reinforcement learning, where an agent's goal is to maximize the probability that one or more events will happen at some point in the future, rather than maximizing cumulative rewards. We demonstrate the effectiveness of our methods on continuous control tasks, with a focus on high-dimensional observations like images where rewards are hard or even impossible to specify.
GPLAC: Generalizing Vision-Based Robotic Skills using Weakly Labeled Images
Aug 07, 2017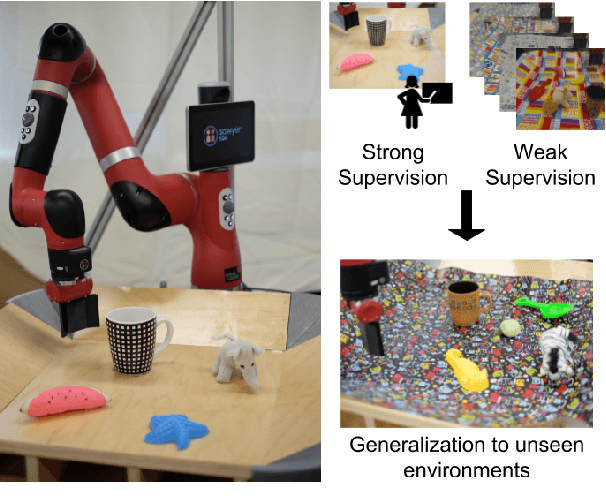

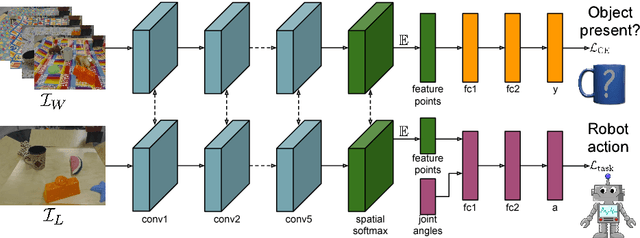

We tackle the problem of learning robotic sensorimotor control policies that can generalize to visually diverse and unseen environments. Achieving broad generalization typically requires large datasets, which are difficult to obtain for task-specific interactive processes such as reinforcement learning or learning from demonstration. However, much of the visual diversity in the world can be captured through passively collected datasets of images or videos. In our method, which we refer to as GPLAC (Generalized Policy Learning with Attentional Classifier), we use both interaction data and weakly labeled image data to augment the generalization capacity of sensorimotor policies. Our method combines multitask learning on action selection and an auxiliary binary classification objective, together with a convolutional neural network architecture that uses an attentional mechanism to avoid distractors. We show that pairing interaction data from just a single environment with a diverse dataset of weakly labeled data results in greatly improved generalization to unseen environments, and show that this generalization depends on both the auxiliary objective and the attentional architecture that we propose. We demonstrate our results in both simulation and on a real robotic manipulator, and demonstrate substantial improvement over standard convolutional architectures and domain adaptation methods.