 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inverse Control with Events: A General Framework for Data-Driven Reward Definition
Paper and Code
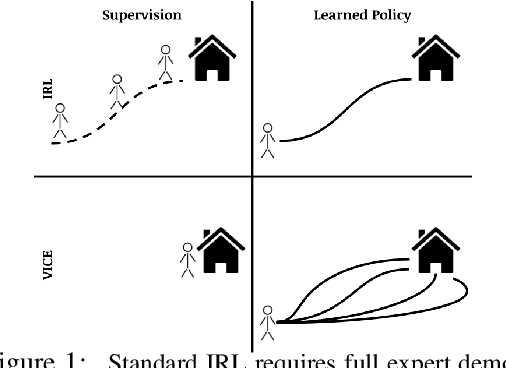



The design of a reward function often poses a major practical challenge to real-world applications of reinforcement learning. Approaches such as inverse reinforcement learning attempt to overcome this challenge, but require expert demonstrations, which can be difficult or expensive to obtain in practice. We propose variational inverse control with events (VICE), which generalizes inverse reinforcement learning methods to cases where full demonstrations are not needed, such as when only samples of desired goal states are available. Our method is grounded in an alternative perspective on control and reinforcement learning, where an agent's goal is to maximize the probability that one or more events will happen at some point in the future, rather than maximizing cumulative rewards. We demonstrate the effectiveness of our methods on continuous control tasks, with a focus on high-dimensional observations like images where rewards are hard or even impossible to specify.