 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARG: Multi-Agent Review Generation for Scientific Papers
Jan 08, 2024We study the ability of LLMs to generate feedback for scientific papers and develop MARG, a feedback generation approach using multiple LLM instances that engage in internal discussion. By distributing paper text across agents, MARG can consume the full text of papers beyond the input length limitations of the base LLM, and by specializing agents and incorporating sub-tasks tailored to different comment types (experiments, clarity, impact) it improves the helpfulness and specificity of feedback. In a user study, baseline methods using GPT-4 were rated as producing generic or very generic comments more than half the time, and only 1.7 comments per paper were rated as good overall in the best baseline. Our system substantially improves the ability of GPT-4 to generate specific and helpful feedback, reducing the rate of generic comments from 60% to 29% and generating 3.7 good comments per paper (a 2.2x improvement).
Learning to Perform Complex Tasks through Compositional Fine-Tuning of Language Models
Oct 23, 2022



How to usefully encode compositional task structure has long been a core challenge in AI. Recent work in chain of thought prompting has shown that for very large neural language models (LMs), explicitly demonstrating the inferential steps involved in a target task may improve performance over end-to-end learning that focuses on the target task alone. However, chain of thought prompting has significant limitations due to its dependency on huge pretrained LMs. In this work, we present compositional fine-tuning (CFT): an approach based on explicitly decomposing a target task into component tasks, and then fine-tuning smaller LMs on a curriculum of such component tasks. We apply CFT to recommendation tasks in two domains, world travel and local dining, as well as a previously studied inferential task (sports understanding). We show that CFT outperforms end-to-end learning even with equal amounts of data, and gets consistently better as more component tasks are modeled via fine-tuning. Compared with chain of thought prompting, CFT performs at least as well using LMs only 7.4% of the size, and is moreover applicable to task domains for which data are not available during pretraining.
"It doesn't look good for a date": Transforming Critiques into Preferences for Conversational Recommendation Systems
Sep 15, 2021
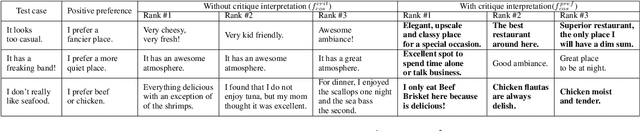
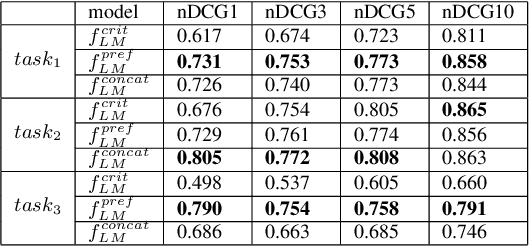
Conversations aimed at determining good recommendations are iterative in nature. People often express their preferences in terms of a critique of the current recommendation (e.g., "It doesn't look good for a date"), requiring some degree of common sense for a preference to be inferred. In this work, we present a method for transforming a user critique into a positive preference (e.g., "I prefer more romantic") in order to retrieve reviews pertaining to potentially better recommendations (e.g., "Perfect for a romantic dinner"). We leverage a large neural language model (LM) in a few-shot setting to perform critique-to-preference transformation, and we test two methods for retrieving recommendations: one that matches embeddings, and another that fine-tunes an LM for the task. We instantiate this approach in the restaurant domain and evaluate it using a new dataset of restaurant critiques. In an ablation study, we show that utilizing critique-to-preference transformation improves recommendations, and that there are at least three general cases that explain this improved performance.
Developing a Conversational Recommendation System for Navigating Limited Options
Apr 13, 2021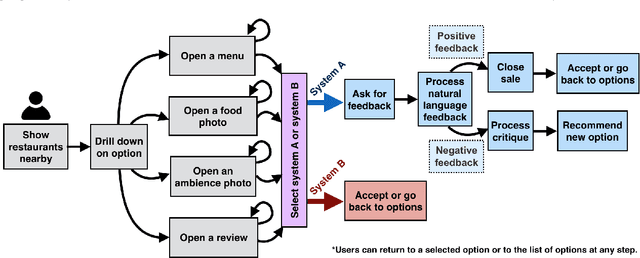
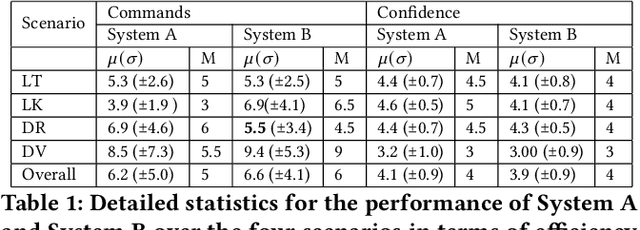
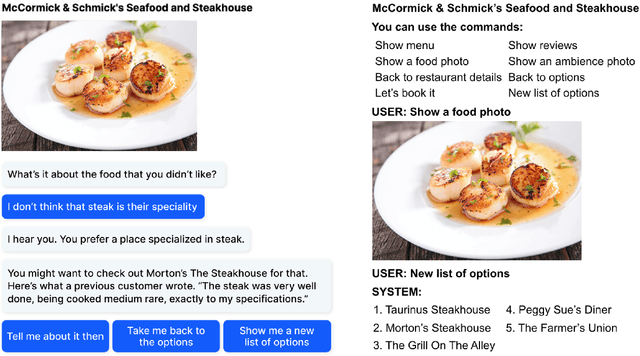
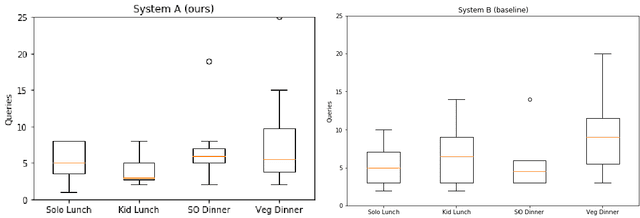
We have developed a conversational recommendation system designed to help users navigate through a set of limited options to find the best choice. Unlike many internet scale systems that use a singular set of search terms and return a ranked list of options from amongst thousands, our system uses multi-turn user dialog to deeply understand the users preferences. The system responds in context to the users specific and immediate feedback to make sequential recommendations. We envision our system would be highly useful in situations with intrinsic constraints, such as finding the right restaurant within walking distance or the right retail item within a limited inventory. Our research prototype instantiates the former use case, leveraging real data from Google Places, Yelp, and Zomato. We evaluated our system against a similar system that did not incorporate user feedback in a 16 person remote study, generating 64 scenario-based search journeys. When our recommendation system was successfully triggered, we saw both an increase in efficiency and a higher confidence rating with respect to final user choice. We also found that users preferred our system (75%) compared with the baseline.
Definition Modeling: Learning to define word embeddings in natural language
Dec 01, 2016
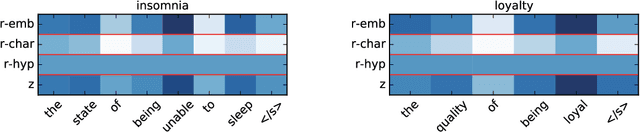
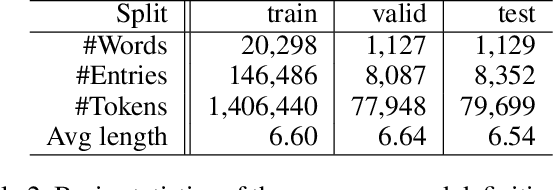

Distributed representations of words have been shown to capture lexical semantics, as demonstrated by their effectiveness in word similarity and analogical relation tasks. But, these tasks only evaluate lexical semantics indirectly. In this paper, we study whether it is possible to utilize distributed representations to generate dictionary definitions of words, as a more direct and transparent representation of the embeddings' semantics. We introduce definition modeling, the task of generating a definition for a given word and its embedding. We present several definition model architectures based on recurrent neural networks, and experiment with the models over multiple data sets. Our results show that a model that controls dependencies between the word being defined and the definition words performs significantly better, and that a character-level convolution layer designed to leverage morphology can complement word-level embeddings. Finally, an error analysis suggests that the errors made by a definition model may provide insight into the shortcomings of word embeddings.