 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Unbiased Methods for Multi-Goal Reinforcement Learning
Jun 16, 2021
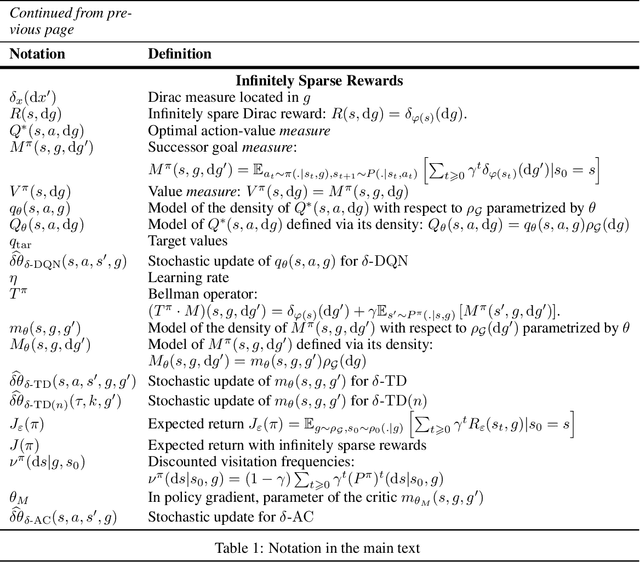
In multi-goal reinforcement learning (RL) settings, the reward for each goal is sparse, and located in a small neighborhood of the goal. In large dimension, the probability of reaching a reward vanishes and the agent receives little learning signal. Methods such as Hindsight Experience Replay (HER) tackle this issue by also learning from realized but unplanned-for goals. But HER is known to introduce bias, and can converge to low-return policies by overestimating chancy outcomes. First, we vindicate HER by proving that it is actually unbiased in deterministic environments, such as many optimal control settings. Next, for stochastic environments in continuous spaces, we tackle sparse rewards by directly taking the infinitely sparse reward limit. We fully formalize the problem of multi-goal RL with infinitely sparse Dirac rewards at each goal. We introduce unbiased deep Q-learning and actor-critic algorithms that can handle such infinitely sparse rewards, and test them in toy environments.
Learning Successor States and Goal-Dependent Values: A Mathematical Viewpoint
Jan 18, 2021
In reinforcement learning, temporal difference-based algorithms can be sample-inefficient: for instance, with sparse rewards, no learning occurs until a reward is observed. This can be remedied by learning richer objects, such as a model of the environment, or successor states. Successor states model the expected future state occupancy from any given state for a given policy and are related to goal-dependent value functions, which learn how to reach arbitrary states. We formally derive the temporal difference algorithm for successor state and goal-dependent value function learning, either for discrete or for continuous environments with function approximation. Especially, we provide finite-variance estimators even in continuous environments, where the reward for exactly reaching a goal state becomes infinitely sparse. Successor states satisfy more than just the Bellman equation: a backward Bellman operator and a Bellman-Newton (BN) operator encode path compositionality in the environment. The BN operator is akin to second-order gradient descent methods and provides the true update of the value function when acquiring more observations, with explicit tabular bounds. In the tabular case and with infinitesimal learning rates, mixing the usual and backward Bellman operators provably improves eigenvalues for asymptotic convergence, and the asymptotic convergence of the BN operator is provably better than TD, with a rate independent from the environment. However, the BN method is more complex and less robust to sampling noise. Finally, a forward-backward (FB) finite-rank parameterization of successor states enjoys reduced variance and improved samplability, provides a direct model of the value function, has fully understood fixed points corresponding to long-range dependencies, approximates the BN method, and provides two canonical representations of states as a byproduct.
Making Deep Q-learning methods robust to time discretization
Jan 29, 2019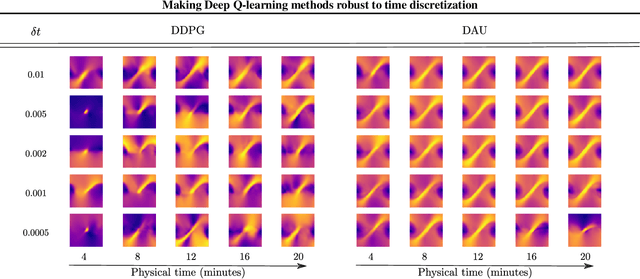
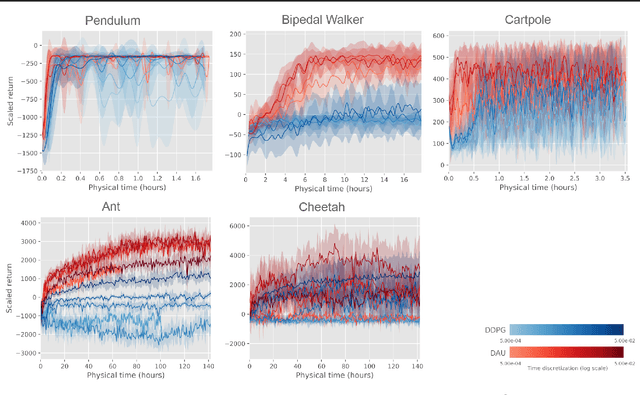
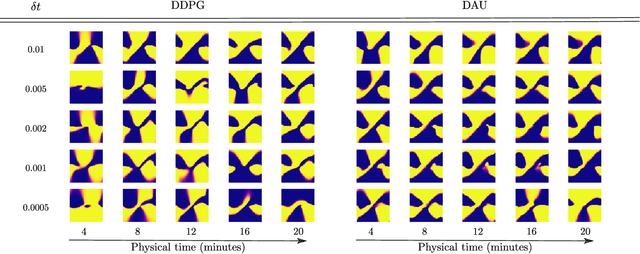
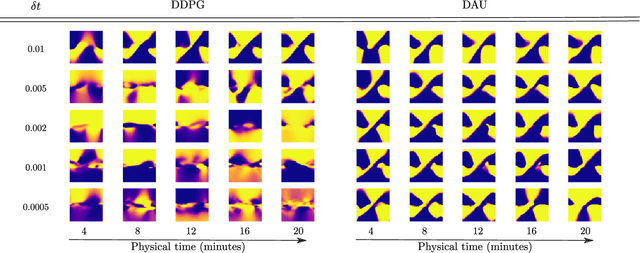
Despite remarkable successes, Deep Reinforcement Learning (DRL) is not robust to hyperparameterization, implementation details, or small environment changes (Henderson et al. 2017, Zhang et al. 2018). Overcoming such sensitivity is key to making DRL applicable to real world problems. In this paper, we identify sensitivity to time discretization in near continuous-time environments as a critical factor; this covers, e.g., changing the number of frames per second, or the action frequency of the controller. Empirically, we find that Q-learning-based approaches such as Deep Q- learning (Mnih et al., 2015) and Deep Deterministic Policy Gradient (Lillicrap et al., 2015) collapse with small time steps. Formally, we prove that Q-learning does not exist in continuous time. We detail a principled way to build an off-policy RL algorithm that yields similar performances over a wide range of time discretizations, and confirm this robustness empirically.
The Description Length of Deep Learning Models
Nov 01, 2018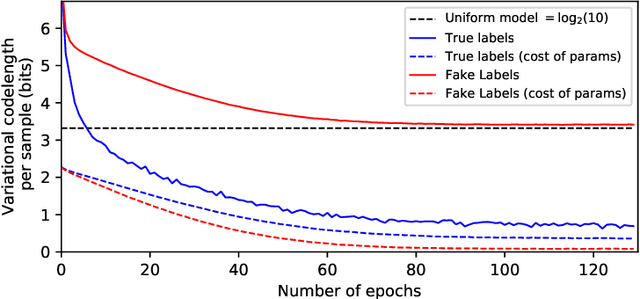
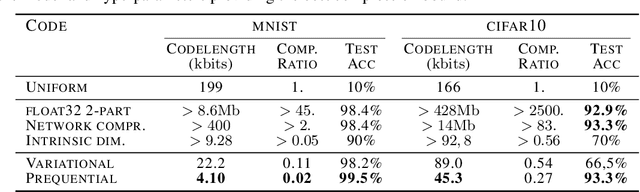
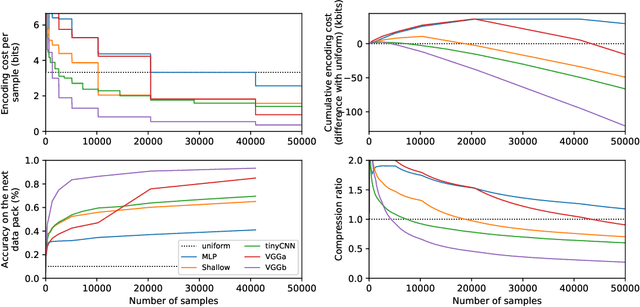
Solomonoff's general theory of inference and the Minimum Description Length principle formalize Occam's razor, and hold that a good model of data is a model that is good at losslessly compressing the data, including the cost of describing the model itself. Deep neural networks might seem to go against this principle given the large number of parameters to be encoded. We demonstrate experimentally the ability of deep neural networks to compress the training data even when accounting for parameter encoding. The compression viewpoint originally motivated the use of variational methods in neural networks. Unexpectedly, we found that these variational methods provide surprisingly poor compression bounds, despite being explicitly built to minimize such bounds. This might explain the relatively poor practical performance of variational methods in deep learning. On the other hand, simple incremental encoding methods yield excellent compression values on deep networks, vindicating Solomonoff's approach.
Learning with Random Learning Rates
Oct 03, 2018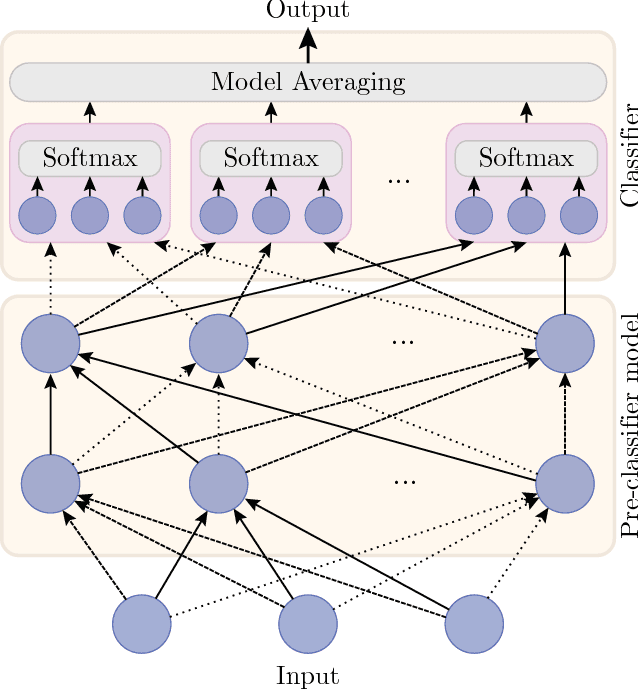
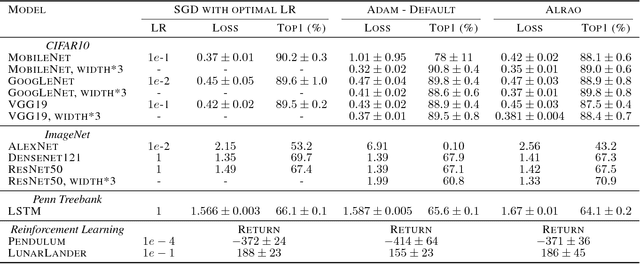
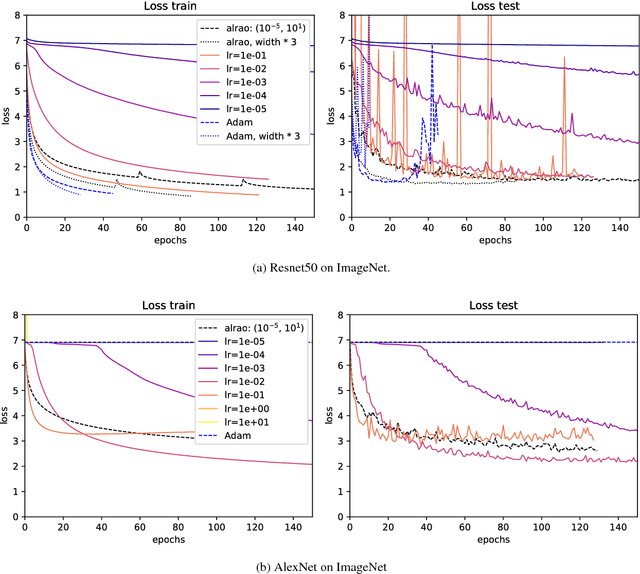
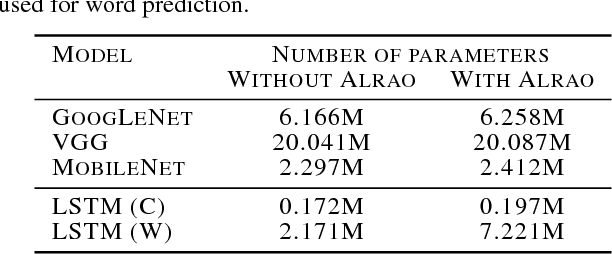
Hyperparameter tuning is a bothersome step in the training of deep learning models. One of the most sensitive hyperparameters is the learning rate of the gradient descent. We present the 'All Learning Rates At Once' (Alrao) optimization method for neural networks: each unit or feature in the network gets its own learning rate sampled from a random distribution spanning several orders of magnitude. This comes at practically no computational cost. Perhaps surprisingly, stochastic gradient descent (SGD) with Alrao performs close to SGD with an optimally tuned learning rate, for various architectures and problems. Alrao could save time when testing deep learning models: a range of models could be quickly assessed with Alrao, and the most promising models could then be trained more extensively. This text comes with a PyTorch implementation of the method, which can be plugged on an existing PyTorch model: https://github.com/leonardblier/alrao .