 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Random Learning Rates
Paper and Code
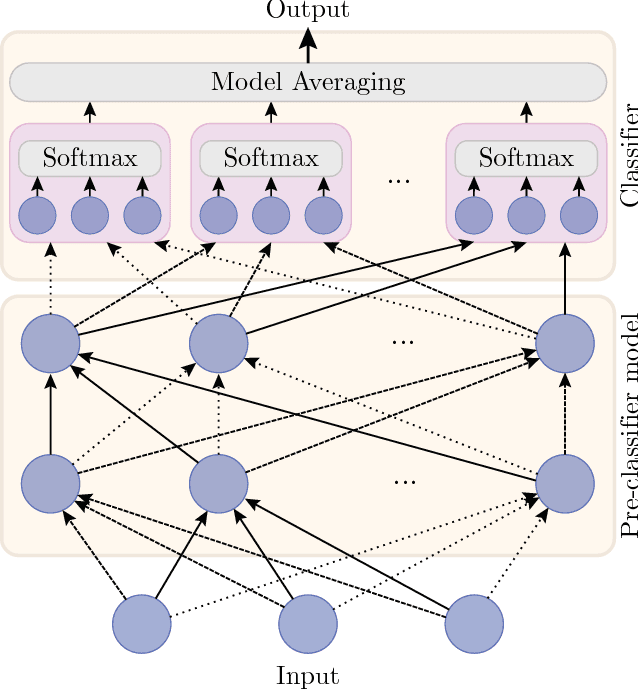
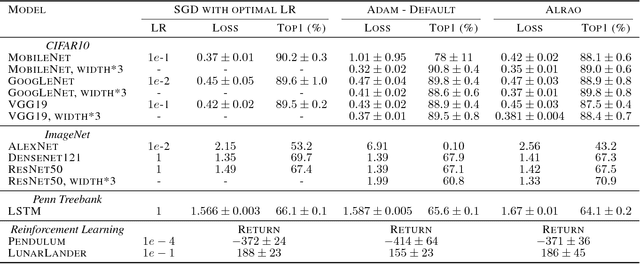
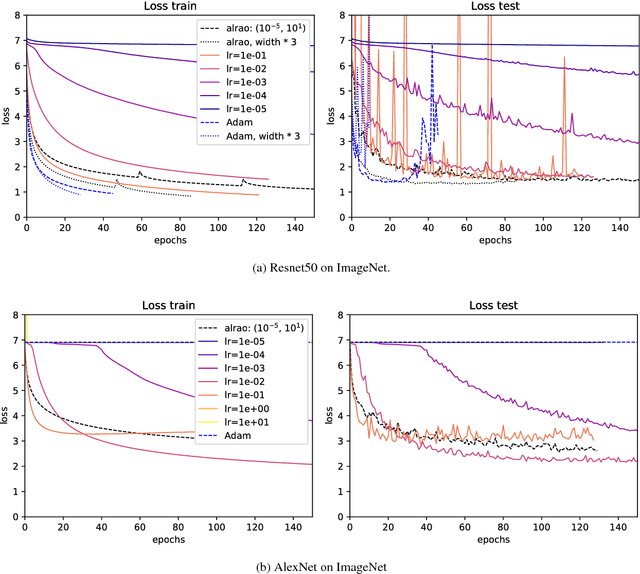
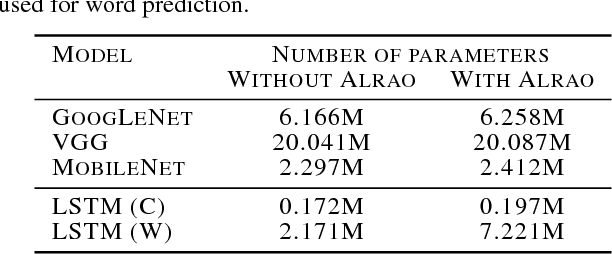
Hyperparameter tuning is a bothersome step in the training of deep learning models. One of the most sensitive hyperparameters is the learning rate of the gradient descent. We present the 'All Learning Rates At Once' (Alrao) optimization method for neural networks: each unit or feature in the network gets its own learning rate sampled from a random distribution spanning several orders of magnitude. This comes at practically no computational cost. Perhaps surprisingly, stochastic gradient descent (SGD) with Alrao performs close to SGD with an optimally tuned learning rate, for various architectures and problems. Alrao could save time when testing deep learning models: a range of models could be quickly assessed with Alrao, and the most promising models could then be trained more extensively. This text comes with a PyTorch implementation of the method, which can be plugged on an existing PyTorch model: https://github.com/leonardblier/alrao .