 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Methods for Multi-Goal Reinforcement Learning
Paper and Code
Jun 16, 2021
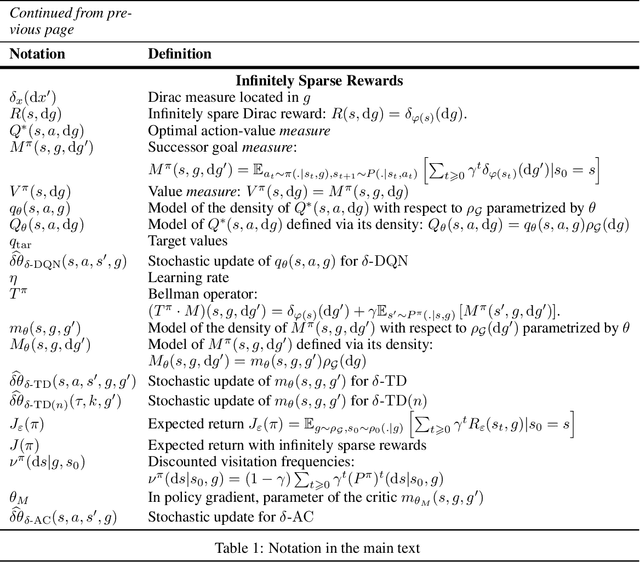
In multi-goal reinforcement learning (RL) settings, the reward for each goal is sparse, and located in a small neighborhood of the goal. In large dimension, the probability of reaching a reward vanishes and the agent receives little learning signal. Methods such as Hindsight Experience Replay (HER) tackle this issue by also learning from realized but unplanned-for goals. But HER is known to introduce bias, and can converge to low-return policies by overestimating chancy outcomes. First, we vindicate HER by proving that it is actually unbiased in deterministic environments, such as many optimal control settings. Next, for stochastic environments in continuous spaces, we tackle sparse rewards by directly taking the infinitely sparse reward limit. We fully formalize the problem of multi-goal RL with infinitely sparse Dirac rewards at each goal. We introduce unbiased deep Q-learning and actor-critic algorithms that can handle such infinitely sparse rewards, and test them in toy environments.