 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
Transferable Candidate Proposal with Bounded Uncertainty
Dec 07, 2023From an empirical perspective, the subset chosen through active learning cannot guarantee an advantage over random sampling when transferred to another model. While it underscores the significance of verifying transferability, experimental design from previous works often neglected that the informativeness of a data subset can change over model configurations. To tackle this issue, we introduce a new experimental design, coined as Candidate Proposal, to find transferable data candidates from which active learning algorithms choose the informative subset. Correspondingly, a data selection algorithm is proposed, namely Transferable candidate proposal with Bounded Uncertainty (TBU), which constrains the pool of transferable data candidates by filtering out the presumably redundant data points based on uncertainty estimation. We verified the validity of TBU in image classification benchmarks, including CIFAR-10/100 and SVHN. When transferred to different model configurations, TBU consistency improves performance in existing active learning algorithms. Our code is available at https://github.com/gokyeongryeol/TBU.
Neural Processes with Stochastic Attention: Paying more attention to the context dataset
Apr 11, 2022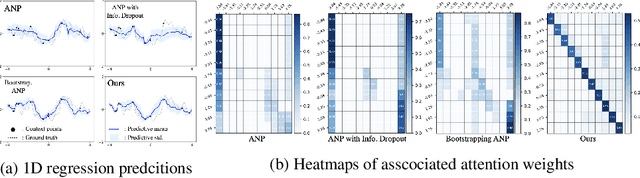
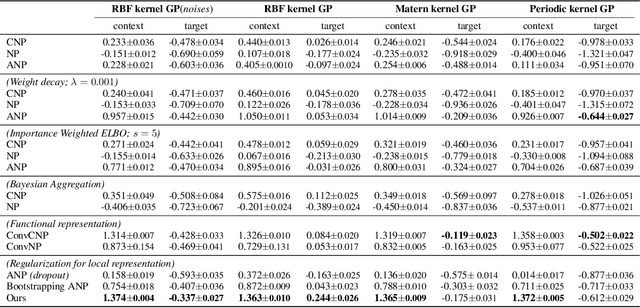
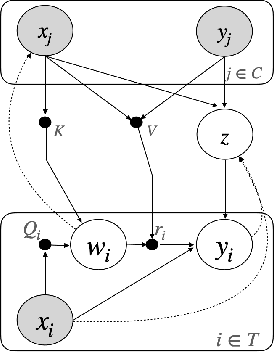
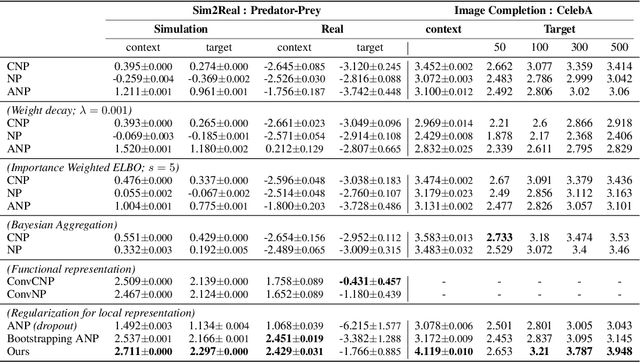
Neural processes (NPs) aim to stochastically complete unseen data points based on a given context dataset. NPs essentially leverage a given dataset as a context representation to derive a suitable identifier for a novel task. To improve the prediction accuracy, many variants of NPs have investigated context embedding approaches that generally design novel network architectures and aggregation functions satisfying permutation invariant. In this work, we propose a stochastic attention mechanism for NPs to capture appropriate context information. From the perspective of information theory, we demonstrate that the proposed method encourages context embedding to be differentiated from a target dataset, allowing NPs to consider features in a target dataset and context embedding independently. We observe that the proposed method can appropriately capture context embedding even under noisy data sets and restricted task distributions, where typical NPs suffer from a lack of context embeddings. We empirically show that our approach substantially outperforms conventional NPs in various domains through 1D regression, predator-prey model, and image completion. Moreover, the proposed method is also validated by MovieLens-10k dataset, a real-world problem.
Meta-learning Amidst Heterogeneity and Ambiguity
Jul 05, 2021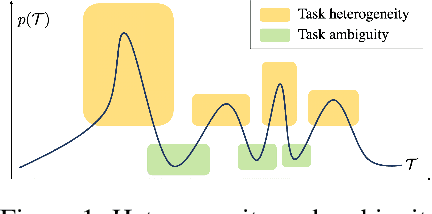
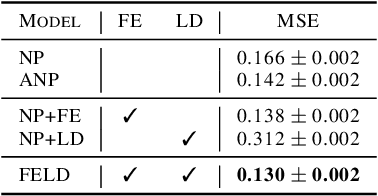
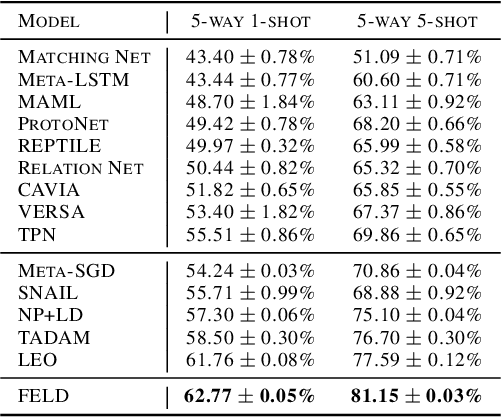

Meta-learning aims to learn a model that can handle multiple tasks generated from an unknown but shared distribution. However, typical meta-learning algorithms have assumed the tasks to be similar such that a single meta-learner is sufficient to aggregate the variations in all aspects. In addition, there has been less consideration on uncertainty when limited information is given as context. In this paper, we devise a novel meta-learning framework, called Meta-learning Amidst Heterogeneity and Ambiguity (MAHA), that outperforms previous works in terms of prediction based on its ability on task identification. By extensively conducting several experiments in regression and classification, we demonstrate the validity of our model, which turns out to be robust to both task heterogeneity and ambiguity.