 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Long-Tailed Relations and Uncommon Entities in Knowledge Graph Completion
Sep 25, 2019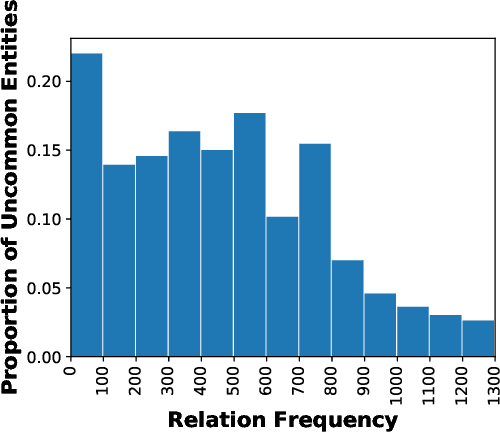
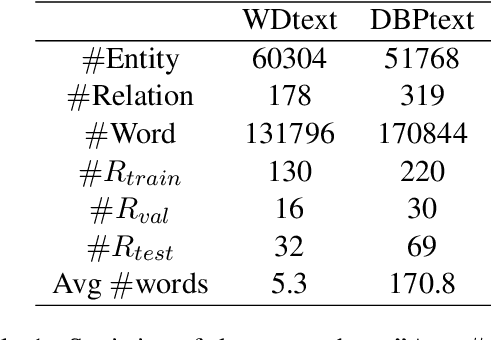


For large-scale knowledge graphs (KGs), recent research has been focusing on the large proportion of infrequent relations which have been ignored by previous studies. For example few-shot learning paradigm for relations has been investigated. In this work, we further advocate that handling uncommon entities is inevitable when dealing with infrequent relations. Therefore, we propose a meta-learning framework that aims at handling infrequent relations with few-shot learning and uncommon entities by using textual descriptions. We design a novel model to better extract key information from textual descriptions. Besides, we also develop a novel generative model in our framework to enhance the performance by generating extra triplets during the training stage. Experiments are conducted on two datasets from real-world KGs, and the results show that our framework outperforms previous methods when dealing with infrequent relations and their accompanying uncommon entities.
Jointly Learning Word Embeddings and Latent Topics
Jun 21, 2017
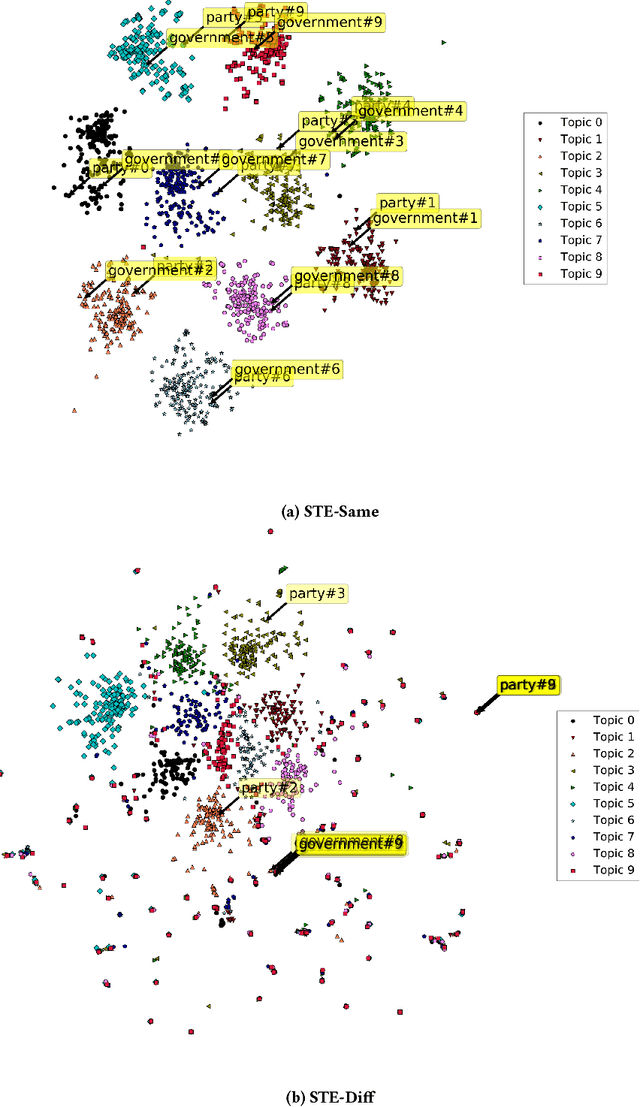
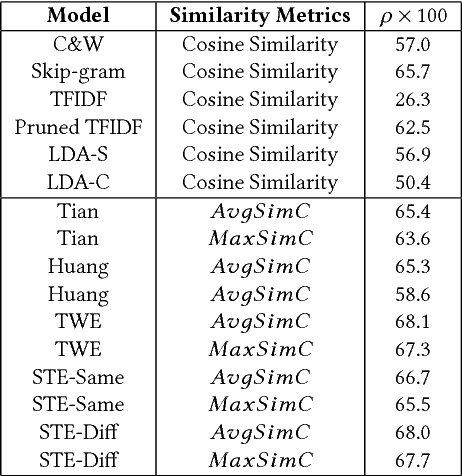

Word embedding models such as Skip-gram learn a vector-space representation for each word, based on the local word collocation patterns that are observed in a text corpus. Latent topic models, on the other hand, take a more global view, looking at the word distributions across the corpus to assign a topic to each word occurrence. These two paradigms are complementary in how they represent the meaning of word occurrences. While some previous works have already looked at using word embeddings for improving the quality of latent topics, and conversely, at using latent topics for improving word embeddings, such "two-step" methods cannot capture the mutual interaction between the two paradigms. In this paper, we propose STE, a framework which can learn word embeddings and latent topics in a unified manner. STE naturally obtains topic-specific word embeddings, and thus addresses the issue of polysemy. At the same time, it also learns the term distributions of the topics, and the topic distributions of the documents. Our experimental results demonstrate that the STE model can indeed generate useful topic-specific word embeddings and coherent latent topics in an effective and efficient way.