 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Robustness of Federated Learning via Server Learning
Apr 03, 2026This paper explores the use of server learning for enhancing the robustness of federated learning against malicious attacks even when clients' training data are not independent and identically distributed. We propose a heuristic algorithm that uses server learning and client update filtering in combination with geometric median aggregation. We demonstrate via experiments that this approach can achieve significant improvement in model accuracy even when the fraction of malicious clients is high, even more than $50\%$ in some cases, and the dataset utilized by the server is small and could be synthetic with its distribution not necessarily close to that of the clients' aggregated data.
Multi-Head Attention Is a Multi-Player Game
Jan 31, 2026Modern transformer attention is internally multi-agent -- heads compete and coordinate -- yet we train it as if it were a monolithic optimizer. We formalize this gap: cross-entropy training induces an implicit potential game among heads, and gradient descent converges to Nash equilibria with potentially unbounded inefficiency due to unpriced externalities (redundancy, correlated errors). Our main result bounds the Price of Anarchy by $Γ(G)$, the off-diagonal mass of a head interaction matrix capturing weight and gradient coupling. Under mild smoothness assumptions, we prove that both \emph{excess hallucination probability} and \emph{excess head redundancy} scale with PoA, unifying two distinct failure modes into a single mechanism. The bound is prescriptive: regularization that reduces $Γ(G)$ provably tightens PoA. We instantiate this as GAME-LoRA, combining Barlow Twins decorrelation with log-determinant coordination pressure. Experiments validate the theory: $Γ(G)$ predicts hallucination ($p{<}0.05$), emergent coalitions exhibit selective coordination, and GAME-LoRA achieves up to 18\% hallucination reduction (8\% average) with no knowledge degradation -- a Pareto improvement inaccessible to methods ignoring the game structure.
Neural Diversity Regularizes Hallucinations in Small Models
Oct 23, 2025Language models continue to hallucinate despite increases in parameters, compute, and data. We propose neural diversity -- decorrelated parallel representations -- as a principled mechanism that reduces hallucination rates at fixed parameter and data budgets. Inspired by portfolio theory, where uncorrelated assets reduce risk by $\sqrt{P}$, we prove hallucination probability is bounded by representational correlation: $P(H) \leq f(\sigma^2((1-\rho(P))/P + \rho(P)), \mu^2)$, which predicts that language models need an optimal amount of neurodiversity. To validate this, we introduce ND-LoRA (Neural Diversity Low-Rank Adaptation), combining parallel LoRA adapters with Barlow Twins regularization, and demonstrate that ND-LoRA reduces hallucinations by up to 25.6% (and 14.6% on average) without degrading general accuracy. Ablations show LoRA adapters and regularization act synergistically, causal interventions prove neurodiversity as the mediating factor and correlational analyses indicate scale: a 0.1% neural correlation increase is associated with a 3.8% hallucination increase. Finally, task-dependent optimality emerges: different tasks require different amounts of optimal neurodiversity. Together, our results highlight neural diversity as a third axis of scaling -- orthogonal to parameters and data -- to improve the reliability of language models at fixed budgets.
On Model Protection in Federated Learning against Eavesdropping Attacks
Apr 02, 2025In this study, we investigate the protection offered by federated learning algorithms against eavesdropping adversaries. In our model, the adversary is capable of intercepting model updates transmitted from clients to the server, enabling it to create its own estimate of the model. Unlike previous research, which predominantly focuses on safeguarding client data, our work shifts attention protecting the client model itself. Through a theoretical analysis, we examine how various factors, such as the probability of client selection, the structure of local objective functions, global aggregation at the server, and the eavesdropper's capabilities, impact the overall level of protection. We further validate our findings through numerical experiments, assessing the protection by evaluating the model accuracy achieved by the adversary. Finally, we compare our results with methods based on differential privacy, underscoring their limitations in this specific context.
Distributed Optimization via Energy Conservation Laws in Dilated Coordinates
Sep 28, 2024

Optimizing problems in a distributed manner is critical for systems involving multiple agents with private data. Despite substantial interest, a unified method for analyzing the convergence rates of distributed optimization algorithms is lacking. This paper introduces an energy conservation approach for analyzing continuous-time dynamical systems in dilated coordinates. Instead of directly analyzing dynamics in the original coordinate system, we establish a conserved quantity, akin to physical energy, in the dilated coordinate system. Consequently, convergence rates can be explicitly expressed in terms of the inverse time-dilation factor. Leveraging this generalized approach, we formulate a novel second-order distributed accelerated gradient flow with a convergence rate of $O\left(1/t^{2-\epsilon}\right)$ in time $t$ for $\epsilon>0$. We then employ a semi second-order symplectic Euler discretization to derive a rate-matching algorithm with a convergence rate of $O\left(1/k^{2-\epsilon}\right)$ in $k$ iterations. To the best of our knowledge, this represents the most favorable convergence rate for any distributed optimization algorithm designed for smooth convex optimization. Its accelerated convergence behavior is benchmarked against various state-of-the-art distributed optimization algorithms on practical, large-scale problems.
A Methodology Establishing Linear Convergence of Adaptive Gradient Methods under PL Inequality
Jul 17, 2024Adaptive gradient-descent optimizers are the standard choice for training neural network models. Despite their faster convergence than gradient-descent and remarkable performance in practice, the adaptive optimizers are not as well understood as vanilla gradient-descent. A reason is that the dynamic update of the learning rate that helps in faster convergence of these methods also makes their analysis intricate. Particularly, the simple gradient-descent method converges at a linear rate for a class of optimization problems, whereas the practically faster adaptive gradient methods lack such a theoretical guarantee. The Polyak-{\L}ojasiewicz (PL) inequality is the weakest known class, for which linear convergence of gradient-descent and its momentum variants has been proved. Therefore, in this paper, we prove that AdaGrad and Adam, two well-known adaptive gradient methods, converge linearly when the cost function is smooth and satisfies the PL inequality. Our theoretical framework follows a simple and unified approach, applicable to both batch and stochastic gradients, which can potentially be utilized in analyzing linear convergence of other variants of Adam.
Linear Convergence of Pre-Conditioned PI Consensus Algorithm under Restricted Strong Convexity
Sep 30, 2023
This paper considers solving distributed convex optimization problems in peer-to-peer multi-agent networks. The network is assumed to be synchronous and connected. By using the proportional-integral (PI) control strategy, various algorithms with fixed stepsize have been developed. The earliest among them is the PI consensus algorithm. Using Lyapunov theory, we guarantee exponential convergence of the PI consensus algorithm for restricted strongly convex functions with rate-matching discretization, without requiring convexity of individual local cost functions, for the first time. In order to accelerate the PI consensus algorithm, we incorporate local pre-conditioning in the form of constant positive definite matrices and numerically validate its efficiency compared to the prominent distributed convex optimization algorithms. Unlike classical pre-conditioning, where only the gradients are multiplied by a pre-conditioner, the proposed pre-conditioning modifies both the gradients and the consensus terms, thereby controlling the effect of the communication graph between the agents on the PI consensus algorithm.
Iteratively Preconditioned Gradient-Descent Approach for Moving Horizon Estimation Problems
Jun 22, 2023


Moving horizon estimation (MHE) is a widely studied state estimation approach in several practical applications. In the MHE problem, the state estimates are obtained via the solution of an approximated nonlinear optimization problem. However, this optimization step is known to be computationally complex. Given this limitation, this paper investigates the idea of iteratively preconditioned gradient-descent (IPG) to solve MHE problem with the aim of an improved performance than the existing solution techniques. To our knowledge, the preconditioning technique is used for the first time in this paper to reduce the computational cost and accelerate the crucial optimization step for MHE. The convergence guarantee of the proposed iterative approach for a class of MHE problems is presented. Additionally, sufficient conditions for the MHE problem to be convex are also derived. Finally, the proposed method is implemented on a unicycle localization example. The simulation results demonstrate that the proposed approach can achieve better accuracy with reduced computational costs.
A Control Theoretic Framework for Adaptive Gradient Optimizers in Machine Learning
Jun 04, 2022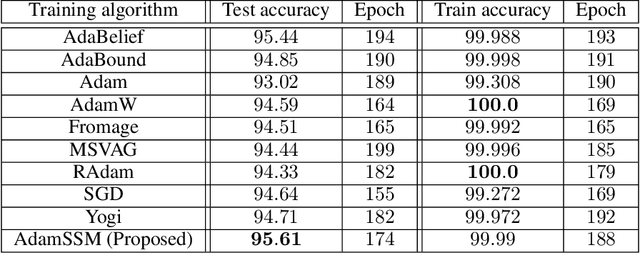

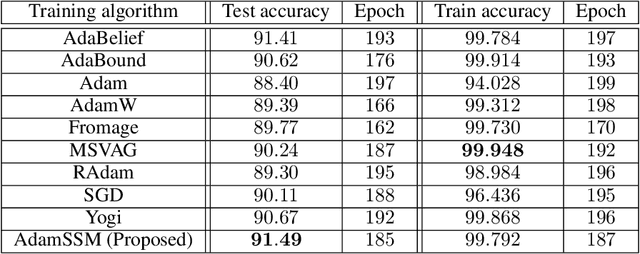
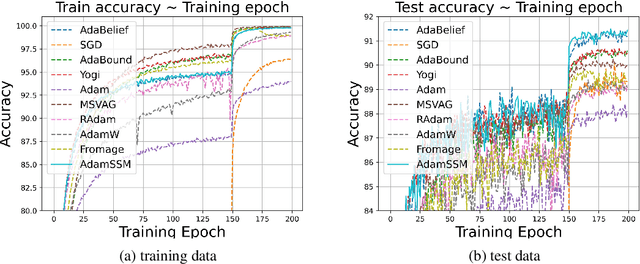
Adaptive gradient methods have become popular in optimizing deep neural networks; recent examples include AdaGrad and Adam. Although Adam usually converges faster, variations of Adam, for instance, the AdaBelief algorithm, have been proposed to enhance Adam's poor generalization ability compared to the classical stochastic gradient method. This paper develops a generic framework for adaptive gradient methods that solve non-convex optimization problems. We first model the adaptive gradient methods in a state-space framework, which allows us to present simpler convergence proofs of adaptive optimizers such as AdaGrad, Adam, and AdaBelief. We then utilize the transfer function paradigm from classical control theory to propose a new variant of Adam, coined AdamSSM. We add an appropriate pole-zero pair in the transfer function from squared gradients to the second moment estimate. We prove the convergence of the proposed AdamSSM algorithm. Applications on benchmark machine learning tasks of image classification using CNN architectures and language modeling using LSTM architecture demonstrate that the AdamSSM algorithm improves the gap between generalization accuracy and faster convergence than the recent adaptive gradient methods.
On Accelerating Distributed Convex Optimizations
Aug 19, 2021



This paper studies a distributed multi-agent convex optimization problem. The system comprises multiple agents in this problem, each with a set of local data points and an associated local cost function. The agents are connected to a server, and there is no inter-agent communication. The agents' goal is to learn a parameter vector that optimizes the aggregate of their local costs without revealing their local data points. In principle, the agents can solve this problem by collaborating with the server using the traditional distributed gradient-descent method. However, when the aggregate cost is ill-conditioned, the gradient-descent method (i) requires a large number of iterations to converge, and (ii) is highly unstable against process noise. We propose an iterative pre-conditioning technique to mitigate the deleterious effects of the cost function's conditioning on the convergence rate of distributed gradient-descent. Unlike the conventional pre-conditioning techniques, the pre-conditioner matrix in our proposed technique updates iteratively to facilitate implementation on the distributed network. In the distributed setting, we provably show that the proposed algorithm converges linearly with an improved rate of convergence than the traditional and adaptive gradient-descent methods. Additionally, for the special case when the minimizer of the aggregate cost is unique, our algorithm converges superlinearly. We demonstrate our algorithm's superior performance compared to prominent distributed algorithms for solving real logistic regression problems and emulating neural network training via a noisy quadratic model, thereby signifying the proposed algorithm's efficiency for distributively solving non-convex optimization. Moreover, we empirically show that the proposed algorithm results in faster training without compromising the generalization performance.