 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing and Understanding Energy Footprint and Efficiency of Small Language Model on Edges
Nov 07, 2025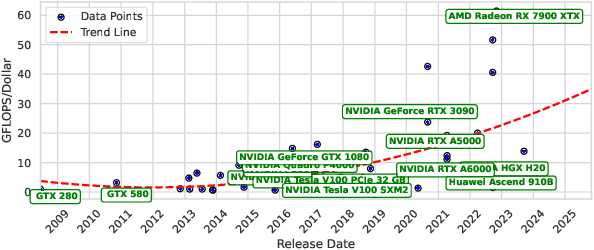
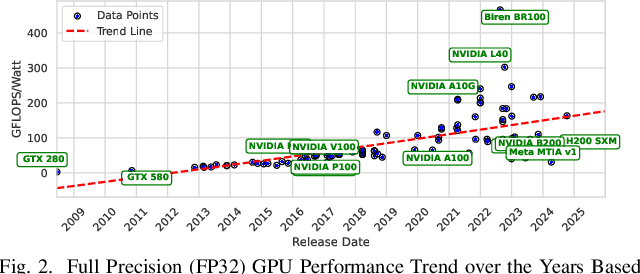

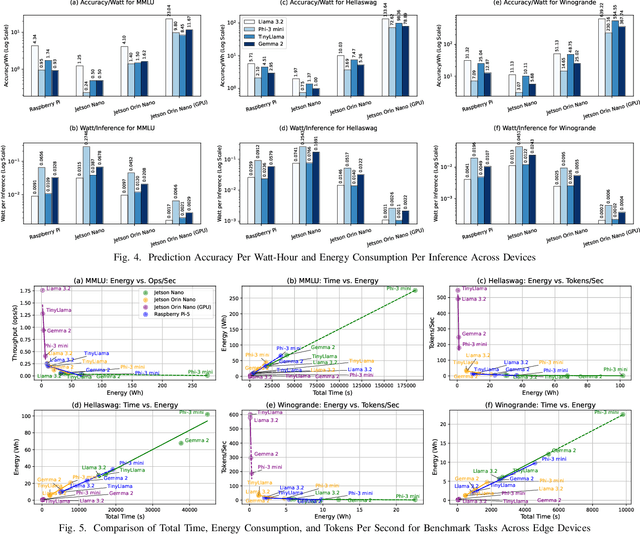
Cloud-based large language models (LLMs) and their variants have significantly influenced real-world applications. Deploying smaller models (i.e., small language models (SLMs)) on edge devices offers additional advantages, such as reduced latency and independence from network connectivity. However, edge devices' limited computing resources and constrained energy budgets challenge efficient deployment. This study evaluates the power efficiency of five representative SLMs - Llama 3.2, Phi-3 Mini, TinyLlama, and Gemma 2 on Raspberry Pi 5, Jetson Nano, and Jetson Orin Nano (CPU and GPU configurations). Results show that Jetson Orin Nano with GPU acceleration achieves the highest energy-to-performance ratio, significantly outperforming CPU-based setups. Llama 3.2 provides the best balance of accuracy and power efficiency, while TinyLlama is well-suited for low-power environments at the cost of reduced accuracy. In contrast, Phi-3 Mini consumes the most energy despite its high accuracy. In addition, GPU acceleration, memory bandwidth, and model architecture are key in optimizing inference energy efficiency. Our empirical analysis offers practical insights for AI, smart systems, and mobile ad-hoc platforms to leverage tradeoffs from accuracy, inference latency, and power efficiency in energy-constrained environments.
Activation Sparsity Opportunities for Compressing General Large Language Models
Dec 13, 2024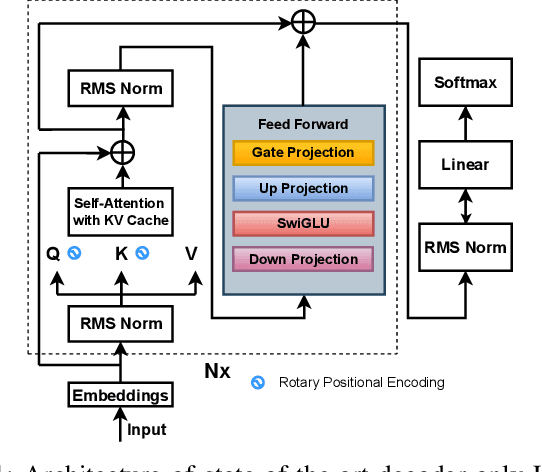



Deploying local AI models, such as Large Language Models (LLMs), to edge devices can substantially enhance devices' independent capabilities, alleviate the server's burden, and lower the response time. Owing to these tremendous potentials, many big tech companies have released several lightweight Small Language Models (SLMs) to bridge this gap. However, we still have huge motivations to deploy more powerful (LLMs) AI models on edge devices and enhance their smartness level. Unlike the conventional approaches for AI model compression, we investigate activation sparsity. The activation sparsity method is orthogonal and combinable with existing techniques to maximize compression rate while maintaining great accuracy. LLMs' Feed-Forward Network (FFN) components, which typically comprise a large proportion of parameters (around 3/2), ensure that our FFN optimizations would have a better chance of achieving effective compression. Moreover, our findings are beneficial to general LLMs and are not restricted to ReLU-based models. This work systematically investigates the tradeoff between enforcing activation sparsity and perplexity (accuracy) on state-of-the-art LLMs. Our empirical analysis demonstrates that we can obtain around 50% of main memory and computing reductions for critical FFN components with negligible accuracy degradation. This extra 50% sparsity does not naturally exist in the current LLMs, which require tuning LLMs' activation outputs by injecting zero-enforcing thresholds. To obtain the benefits of activation sparsity, we provide a guideline for the system architect for LLM prediction and prefetching. The success prediction allows the system to prefetch the necessary weights while omitting the inactive ones and their successors, therefore lowering cache and memory pollution and reducing LLM execution time on resource-constrained edge devices.
FTBC: Forward Temporal Bias Correction for Optimizing ANN-SNN Conversion
Mar 27, 2024Spiking Neural Networks (SNNs) offer a promising avenue for energy-efficient computing compared with Artificial Neural Networks (ANNs), closely mirroring biological neural processes. However, this potential comes with inherent challenges in directly training SNNs through spatio-temporal backpropagation -- stemming from the temporal dynamics of spiking neurons and their discrete signal processing -- which necessitates alternative ways of training, most notably through ANN-SNN conversion. In this work, we introduce a lightweight Forward Temporal Bias Correction (FTBC) technique, aimed at enhancing conversion accuracy without the computational overhead. We ground our method on provided theoretical findings that through proper temporal bias calibration the expected error of ANN-SNN conversion can be reduced to be zero after each time step. We further propose a heuristic algorithm for finding the temporal bias only in the forward pass, thus eliminating the computational burden of backpropagation and we evaluate our method on CIFAR-10/100 and ImageNet datasets, achieving a notable increase in accuracy on all datasets. Codes are released at a GitHub repository.