 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNet2Brain: A Toolbox to compare artificial vision models with human brain responses
Aug 25, 2022

We introduce Net2Brain, a graphical and command-line user interface toolbox for comparing the representational spaces of artificial deep neural networks (DNNs) and human brain recordings. While different toolboxes facilitate only single functionalities or only focus on a small subset of supervised image classification models, Net2Brain allows the extraction of activations of more than 600 DNNs trained to perform a diverse range of vision-related tasks (e.g semantic segmentation, depth estimation, action recognition, etc.), over both image and video datasets. The toolbox computes the representational dissimilarity matrices (RDMs) over those activations and compares them to brain recordings using representational similarity analysis (RSA), weighted RSA, both in specific ROIs and with searchlight search. In addition, it is possible to add a new data set of stimuli and brain recordings to the toolbox for evaluation. We demonstrate the functionality and advantages of Net2Brain with an example showcasing how it can be used to test hypotheses of cognitive computational neuroscience.
What do navigation agents learn about their environment?
Jun 17, 2022
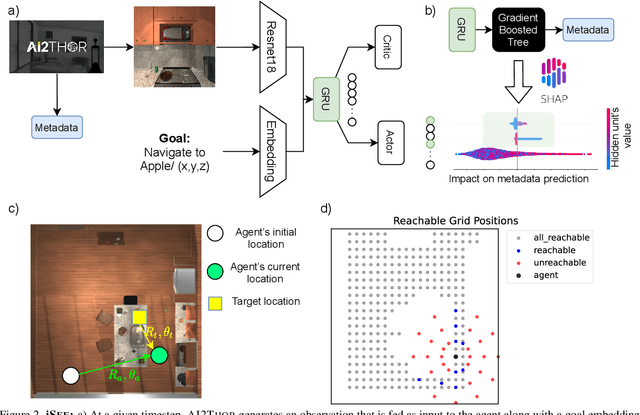


Today's state of the art visual navigation agents typically consist of large deep learning models trained end to end. Such models offer little to no interpretability about the learned skills or the actions of the agent taken in response to its environment. While past works have explored interpreting deep learning models, little attention has been devoted to interpreting embodied AI systems, which often involve reasoning about the structure of the environment, target characteristics and the outcome of one's actions. In this paper, we introduce the Interpretability System for Embodied agEnts (iSEE) for Point Goal and Object Goal navigation agents. We use iSEE to probe the dynamic representations produced by these agents for the presence of information about the agent as well as the environment. We demonstrate interesting insights about navigation agents using iSEE, including the ability to encode reachable locations (to avoid obstacles), visibility of the target, progress from the initial spawn location as well as the dramatic effect on the behaviors of agents when we mask out critical individual neurons. The code is available at: https://github.com/allenai/iSEE
Duality Diagram Similarity: a generic framework for initialization selection in task transfer learning
Aug 05, 2020In this paper, we tackle an open research question in transfer learning, which is selecting a model initialization to achieve high performance on a new task, given several pre-trained models. We propose a new highly efficient and accurate approach based on duality diagram similarity (DDS) between deep neural networks (DNNs). DDS is a generic framework to represent and compare data of different feature dimensions. We validate our approach on the Taskonomy dataset by measuring the correspondence between actual transfer learning performance rankings on 17 taskonomy tasks and predicted rankings. Computing DDS based ranking for $17\times17$ transfers requires less than 2 minutes and shows a high correlation ($0.86$) with actual transfer learning rankings, outperforming state-of-the-art methods by a large margin ($10\%$) on the Taskonomy benchmark. We also demonstrate the robustness of our model selection approach to a new task, namely Pascal VOC semantic segmentation. Additionally, we show that our method can be applied to select the best layer locations within a DNN for transfer learning on 2D, 3D and semantic tasks on NYUv2 and Pascal VOC datasets.
The Algonauts Project: A Platform for Communication between the Sciences of Biological and Artificial Intelligence
May 14, 2019

In the last decade, artificial intelligence (AI) models inspired by the brain have made unprecedented progress in performing real-world perceptual tasks like object classification and speech recognition. Recently, researchers of natural intelligence have begun using those AI models to explore how the brain performs such tasks. These developments suggest that future progress will benefit from increased interaction between disciplines. Here we introduce the Algonauts Project as a structured and quantitative communication channel for interdisciplinary interaction between natural and artificial intelligence researchers. The project's core is an open challenge with a quantitative benchmark whose goal is to account for brain data through computational models. This project has the potential to provide better models of natural intelligence and to gather findings that advance AI. The 2019 Algonauts Project focuses on benchmarking computational models predicting human brain activity when people look at pictures of objects. The 2019 edition of the Algonauts Project is available online: http://algonauts.csail.mit.edu/.
Representation Similarity Analysis for Efficient Task taxonomy & Transfer Learning
Apr 26, 2019



Transfer learning is widely used in deep neural network models when there are few labeled examples available. The common approach is to take a pre-trained network in a similar task and finetune the model parameters. This is usually done blindly without a pre-selection from a set of pre-trained models, or by finetuning a set of models trained on different tasks and selecting the best performing one by cross-validation. We address this problem by proposing an approach to assess the relationship between visual tasks and their task-specific models. Our method uses Representation Similarity Analysis (RSA), which is commonly used to find a correlation between neuronal responses from brain data and models. With RSA we obtain a similarity score among tasks by computing correlations between models trained on different tasks. Our method is efficient as it requires only pre-trained models, and a few images with no further training. We demonstrate the effectiveness and efficiency of our method for generating task taxonomy on Taskonomy dataset. We next evaluate the relationship of RSA with the transfer learning performance on Taskonomy tasks and a new task: Pascal VOC semantic segmentation. Our results reveal that models trained on tasks with higher similarity score show higher transfer learning performance. Surprisingly, the best transfer learning result for Pascal VOC semantic segmentation is not obtained from the pre-trained model on semantic segmentation, probably due to the domain differences, and our method successfully selects the high performing models.
Deep Anchored Convolutional Neural Networks
Apr 22, 2019

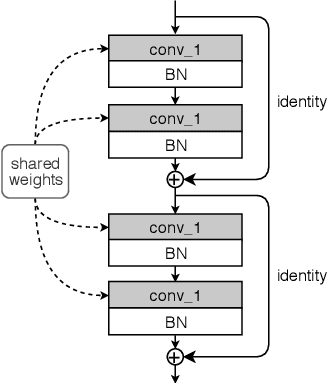

Convolutional Neural Networks (CNNs) have been proven to be extremely successful at solving computer vision tasks. State-of-the-art methods favor such deep network architectures for its accuracy performance, with the cost of having massive number of parameters and high weights redundancy. Previous works have studied how to prune such CNNs weights. In this paper, we go to another extreme and analyze the performance of a network stacked with a single convolution kernel across layers, as well as other weights sharing techniques. We name it Deep Anchored Convolutional Neural Network (DACNN). Sharing the same kernel weights across layers allows to reduce the model size tremendously, more precisely, the network is compressed in memory by a factor of L, where L is the desired depth of the network, disregarding the fully connected layer for prediction. The number of parameters in DACNN barely increases as the network grows deeper, which allows us to build deep DACNNs without any concern about memory costs. We also introduce a partial shared weights network (DACNN-mix) as well as an easy-plug-in module, coined regulators, to boost the performance of our architecture. We validated our idea on 3 datasets: CIFAR-10, CIFAR-100 and SVHN. Our results show that we can save massive amounts of memory with our model, while maintaining a high accuracy performance.