 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBielik-Minitron-7B: Compressing Large Language Models via Structured Pruning and Knowledge Distillation for the Polish Language
Mar 12, 2026This report details the creation of Bielik-Minitron-7B, a compressed 7.35B parameter version of the Bielik-11B-v3.0 model, specifically optimized for European languages. By leveraging a two-stage compression methodology inspired by the NVIDIA Minitron approach, we combined structured hybrid pruning and knowledge distillation to reduce the model's parameter count by 33.4%, from 11.04B to 7.35B. We utilized the NVIDIA Model Optimizer for structural pruning and the NVIDIA NeMo Framework for logit-based distillation for quality recovery. Following distillation, the model underwent a rigorous alignment pipeline consisting of Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO-P), and Reinforcement Learning (GRPO). Our final model successfully recovered approximately 90% of the baseline model's performance while providing up to 50% inference speedup. This approach demonstrates an efficient pathway to create language models for less-represented languages, preserving the original model quality while reducing inference deployment costs.
Bielik Guard: Efficient Polish Language Safety Classifiers for LLM Content Moderation
Feb 08, 2026As Large Language Models (LLMs) become increasingly deployed in Polish language applications, the need for efficient and accurate content safety classifiers has become paramount. We present Bielik Guard, a family of compact Polish language safety classifiers comprising two model variants: a 0.1B parameter model based on MMLW-RoBERTa-base and a 0.5B parameter model based on PKOBP/polish-roberta-8k. Fine-tuned on a community-annotated dataset of 6,885 Polish texts, these models classify content across five safety categories: Hate/Aggression, Vulgarities, Sexual Content, Crime, and Self-Harm. Our evaluation demonstrates that both models achieve strong performance on multiple benchmarks. The 0.5B variant offers the best overall discrimination capability with F1 scores of 0.791 (micro) and 0.785 (macro) on the test set, while the 0.1B variant demonstrates exceptional efficiency. Notably, Bielik Guard 0.1B v1.1 achieves superior precision (77.65\%) and very low false positive rate (0.63\%) on real user prompts, outperforming HerBERT-PL-Guard (31.55\% precision, 4.70\% FPR) despite identical model size. The models are publicly available and designed to provide appropriate responses rather than simple content blocking, particularly for sensitive categories like self-harm.
Bielik 11B v2 Technical Report
May 05, 2025



We present Bielik 11B v2, a state-of-the-art language model optimized for Polish text processing. Built on the Mistral 7B v0.2 architecture and scaled to 11B parameters using depth up-scaling, this model demonstrates exceptional performance across Polish language benchmarks while maintaining strong cross-lingual capabilities. We introduce two key technical innovations: Weighted Instruction Cross-Entropy Loss, which optimizes learning across diverse instruction types by assigning quality-based weights to training examples, and Adaptive Learning Rate, which dynamically adjusts based on context length. Comprehensive evaluation across multiple benchmarks demonstrates that Bielik 11B v2 outperforms many larger models, including those with 2-6 times more parameters, and significantly surpasses other specialized Polish language models on tasks ranging from linguistic understanding to complex reasoning. The model's parameter efficiency and extensive quantization options enable deployment across various hardware configurations, advancing Polish language AI capabilities and establishing new benchmarks for resource-efficient language modeling in less-represented languages.
Bielik v3 Small: Technical Report
May 05, 2025



We introduce Bielik v3, a series of parameter-efficient generative text models (1.5B and 4.5B) optimized for Polish language processing. These models demonstrate that smaller, well-optimized architectures can achieve performance comparable to much larger counterparts while requiring substantially fewer computational resources. Our approach incorporates several key innovations: a custom Polish tokenizer (APT4) that significantly improves token efficiency, Weighted Instruction Cross-Entropy Loss to balance learning across instruction types, and Adaptive Learning Rate that dynamically adjusts based on training progress. Trained on a meticulously curated corpus of 292 billion tokens spanning 303 million documents, these models excel across multiple benchmarks, including the Open PL LLM Leaderboard, Complex Polish Text Understanding Benchmark, Polish EQ-Bench, and Polish Medical Leaderboard. The 4.5B parameter model achieves results competitive with models 2-3 times its size, while the 1.5B model delivers strong performance despite its extremely compact profile. These advances establish new benchmarks for parameter-efficient language modeling in less-represented languages, making high-quality Polish language AI more accessible for resource-constrained applications.
Bielik 7B v0.1: A Polish Language Model -- Development, Insights, and Evaluation
Oct 24, 2024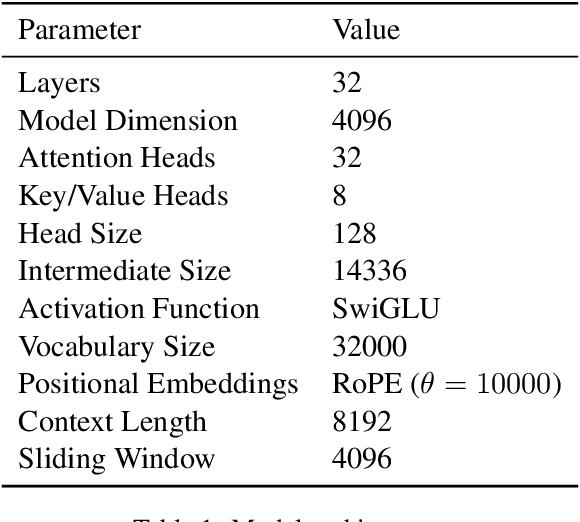
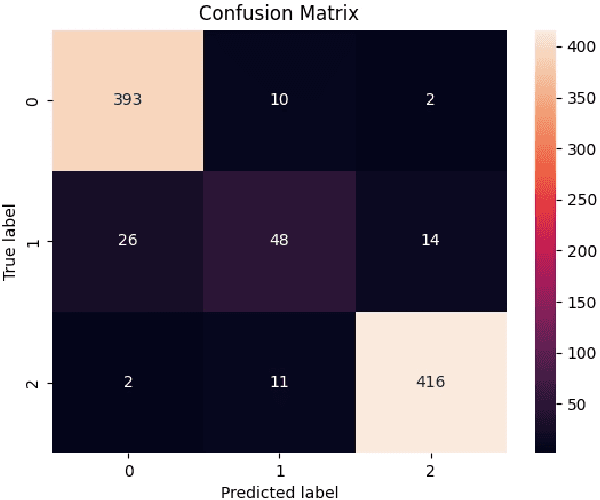
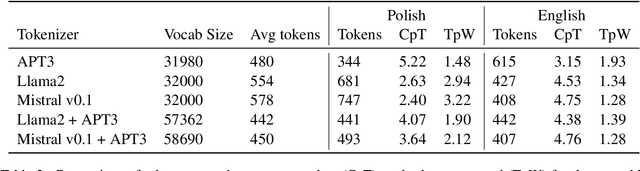
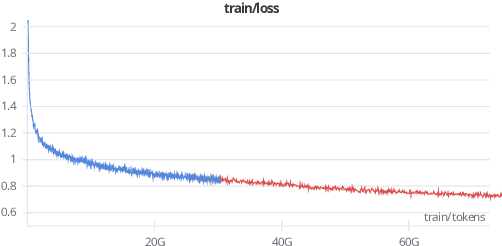
We introduce Bielik 7B v0.1, a 7-billion-parameter generative text model for Polish language processing. Trained on curated Polish corpora, this model addresses key challenges in language model development through innovative techniques. These include Weighted Instruction Cross-Entropy Loss, which balances the learning of different instruction types, and Adaptive Learning Rate, which dynamically adjusts the learning rate based on training progress. To evaluate performance, we created the Open PL LLM Leaderboard and Polish MT-Bench, novel frameworks assessing various NLP tasks and conversational abilities. Bielik 7B v0.1 demonstrates significant improvements, achieving a 9 percentage point increase in average score compared to Mistral-7B-v0.1 on the RAG Reader task. It also excels in the Polish MT-Bench, particularly in Reasoning (6.15/10) and Role-playing (7.83/10) categories. This model represents a substantial advancement in Polish language AI, offering a powerful tool for diverse linguistic applications and setting new benchmarks in the field.
eFontes. Part of Speech Tagging and Lemmatization of Medieval Latin Texts.A Cross-Genre Survey
Jun 29, 2024
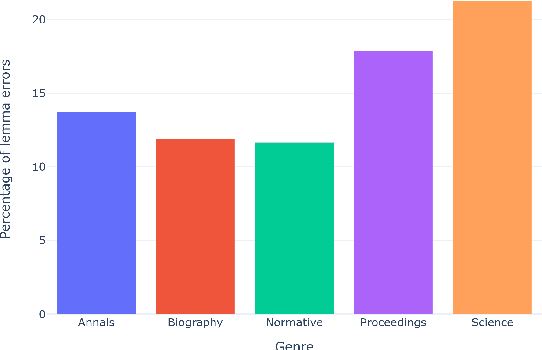
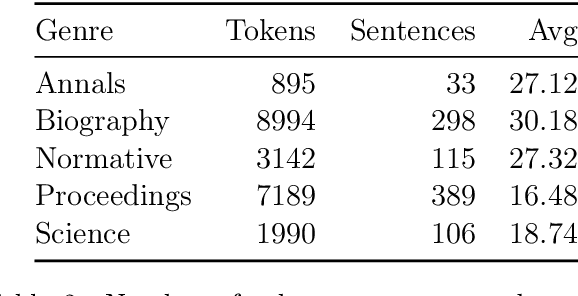
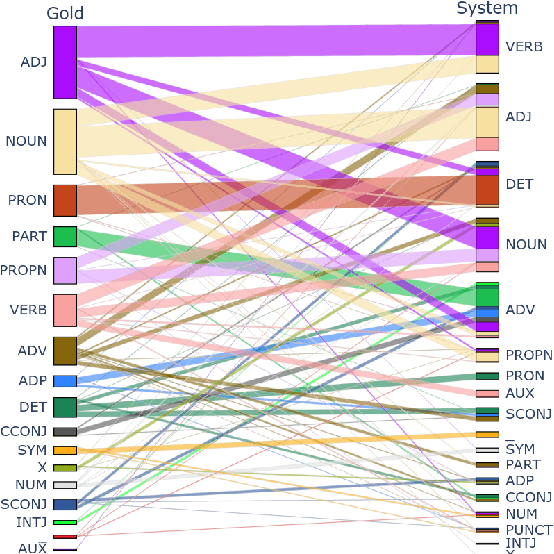
This study introduces the eFontes models for automatic linguistic annotation of Medieval Latin texts, focusing on lemmatization, part-of-speech tagging, and morphological feature determination. Using the Transformers library, these models were trained on Universal Dependencies (UD) corpora and the newly developed eFontes corpus of Polish Medieval Latin. The research evaluates the models' performance, addressing challenges such as orthographic variations and the integration of Latinized vernacular terms. The models achieved high accuracy rates: lemmatization at 92.60%, part-of-speech tagging at 83.29%, and morphological feature determination at 88.57%. The findings underscore the importance of high-quality annotated corpora and propose future enhancements, including extending the models to Named Entity Recognition.
Convolutional neural network compression for natural language processing
May 28, 2018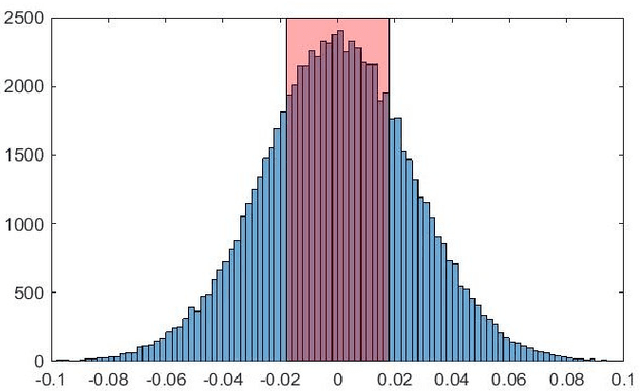
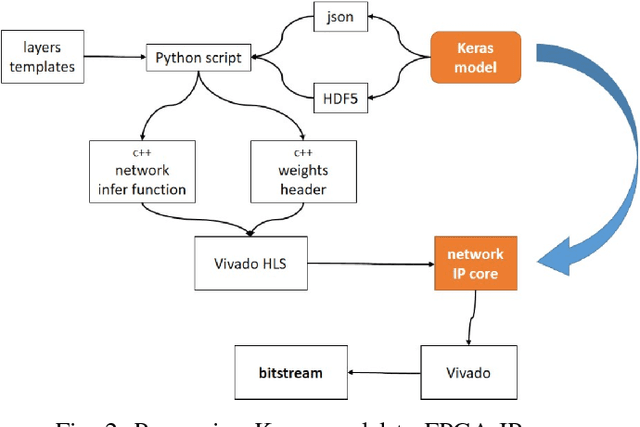
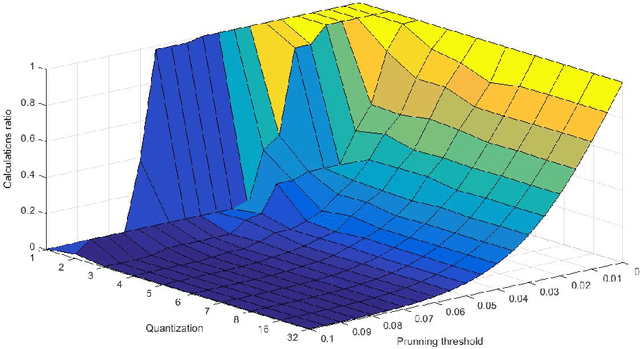
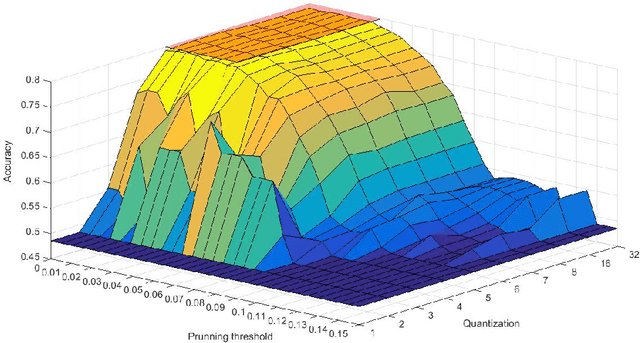
Convolutional neural networks are modern models that are very efficient in many classification tasks. They were originally created for image processing purposes. Then some trials were performed to use them in different domains like natural language processing. The artificial intelligence systems (like humanoid robots) are very often based on embedded systems with constraints on memory, power consumption etc. Therefore convolutional neural network because of its memory capacity should be reduced to be mapped to given hardware. In this paper, results are presented of compressing the efficient convolutional neural networks for sentiment analysis. The main steps are quantization and pruning processes. The method responsible for mapping compressed network to FPGA and results of this implementation are presented. The described simulations showed that 5-bit width is enough to have no drop in accuracy from floating point version of the network. Additionally, significant memory footprint reduction was achieved (from 85% up to 93%).
Improving text classification with vectors of reduced precision
Jun 20, 2017
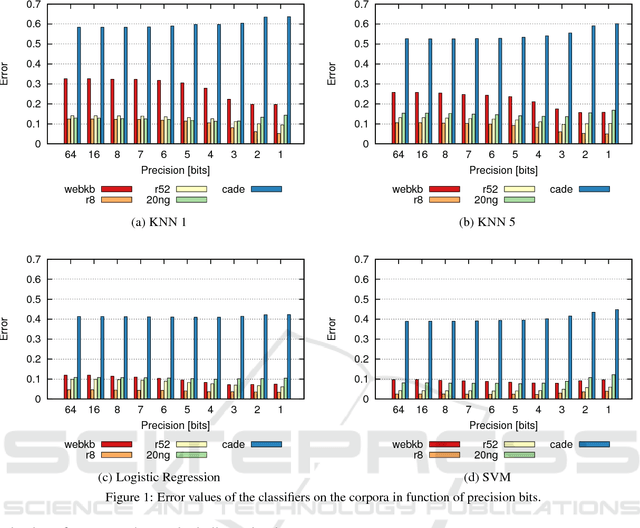

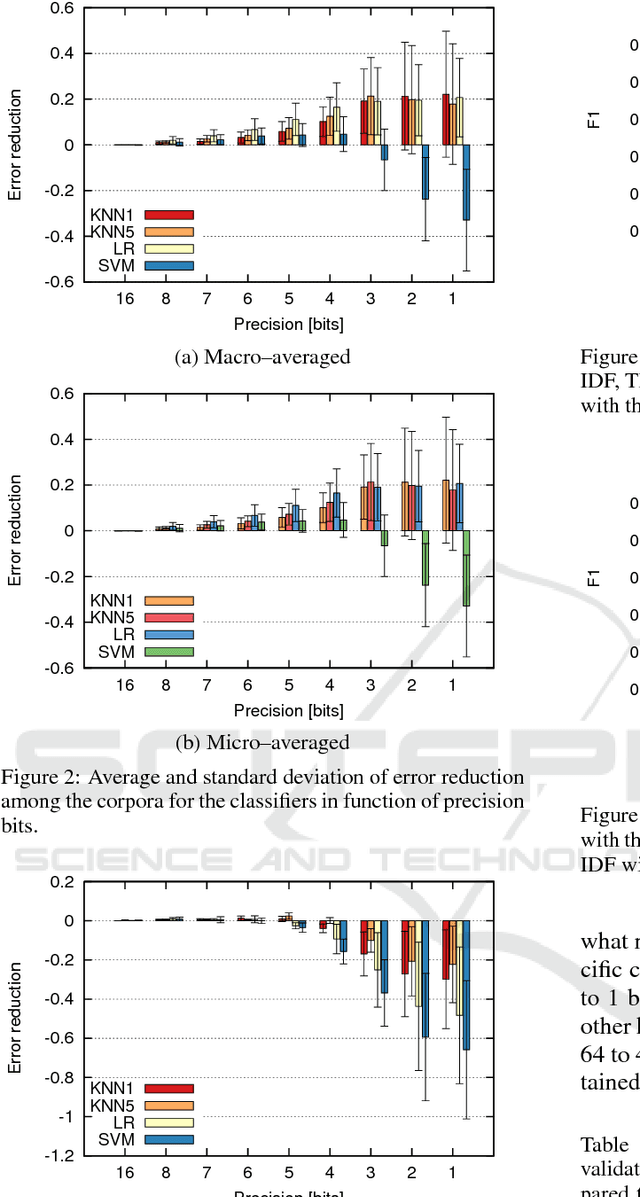
This paper presents the analysis of the impact of a floating-point number precision reduction on the quality of text classification. The precision reduction of the vectors representing the data (e.g. TF-IDF representation in our case) allows for a decrease of computing time and memory footprint on dedicated hardware platforms. The impact of precision reduction on the classification quality was performed on 5 corpora, using 4 different classifiers. Also, dimensionality reduction was taken into account. Results indicate that the precision reduction improves classification accuracy for most cases (up to 25% of error reduction). In general, the reduction from 64 to 4 bits gives the best scores and ensures that the results will not be worse than with the full floating-point representation.