 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional neural network compression for natural language processing
Paper and Code
May 28, 2018
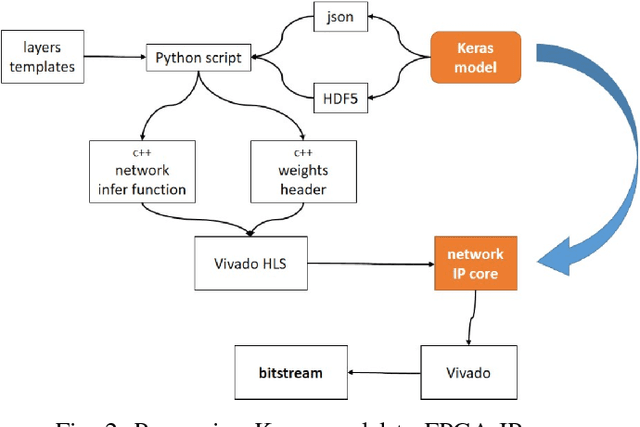
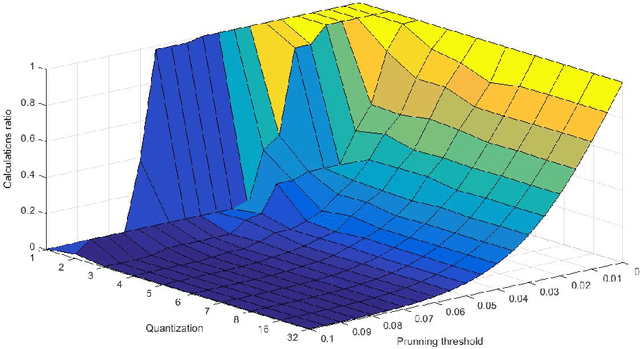
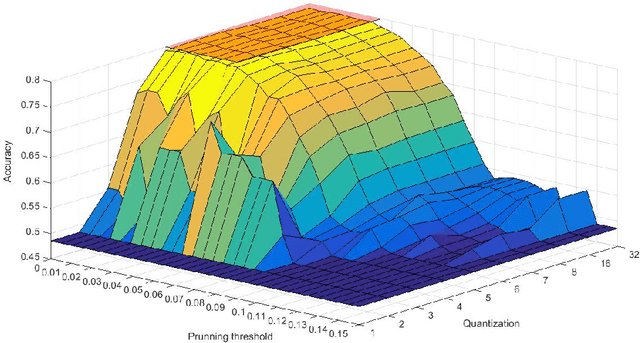
Convolutional neural networks are modern models that are very efficient in many classification tasks. They were originally created for image processing purposes. Then some trials were performed to use them in different domains like natural language processing. The artificial intelligence systems (like humanoid robots) are very often based on embedded systems with constraints on memory, power consumption etc. Therefore convolutional neural network because of its memory capacity should be reduced to be mapped to given hardware. In this paper, results are presented of compressing the efficient convolutional neural networks for sentiment analysis. The main steps are quantization and pruning processes. The method responsible for mapping compressed network to FPGA and results of this implementation are presented. The described simulations showed that 5-bit width is enough to have no drop in accuracy from floating point version of the network. Additionally, significant memory footprint reduction was achieved (from 85% up to 93%).