 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBielik v3 Small: Technical Report
May 05, 2025We introduce Bielik v3, a series of parameter-efficient generative text models (1.5B and 4.5B) optimized for Polish language processing. These models demonstrate that smaller, well-optimized architectures can achieve performance comparable to much larger counterparts while requiring substantially fewer computational resources. Our approach incorporates several key innovations: a custom Polish tokenizer (APT4) that significantly improves token efficiency, Weighted Instruction Cross-Entropy Loss to balance learning across instruction types, and Adaptive Learning Rate that dynamically adjusts based on training progress. Trained on a meticulously curated corpus of 292 billion tokens spanning 303 million documents, these models excel across multiple benchmarks, including the Open PL LLM Leaderboard, Complex Polish Text Understanding Benchmark, Polish EQ-Bench, and Polish Medical Leaderboard. The 4.5B parameter model achieves results competitive with models 2-3 times its size, while the 1.5B model delivers strong performance despite its extremely compact profile. These advances establish new benchmarks for parameter-efficient language modeling in less-represented languages, making high-quality Polish language AI more accessible for resource-constrained applications.
Bielik 11B v2 Technical Report
May 05, 2025We present Bielik 11B v2, a state-of-the-art language model optimized for Polish text processing. Built on the Mistral 7B v0.2 architecture and scaled to 11B parameters using depth up-scaling, this model demonstrates exceptional performance across Polish language benchmarks while maintaining strong cross-lingual capabilities. We introduce two key technical innovations: Weighted Instruction Cross-Entropy Loss, which optimizes learning across diverse instruction types by assigning quality-based weights to training examples, and Adaptive Learning Rate, which dynamically adjusts based on context length. Comprehensive evaluation across multiple benchmarks demonstrates that Bielik 11B v2 outperforms many larger models, including those with 2-6 times more parameters, and significantly surpasses other specialized Polish language models on tasks ranging from linguistic understanding to complex reasoning. The model's parameter efficiency and extensive quantization options enable deployment across various hardware configurations, advancing Polish language AI capabilities and establishing new benchmarks for resource-efficient language modeling in less-represented languages.
Reasoning Language Models: A Blueprint
Jan 20, 2025Reasoning language models (RLMs), also known as Large Reasoning Models (LRMs), such as OpenAI's o1 and o3, DeepSeek-V3, and Alibaba's QwQ, have redefined AI's problem-solving capabilities by extending large language models (LLMs) with advanced reasoning mechanisms. Yet, their high costs, proprietary nature, and complex architectures - uniquely combining Reinforcement Learning (RL), search heuristics, and LLMs - present accessibility and scalability challenges. To address these, we propose a comprehensive blueprint that organizes RLM components into a modular framework, based on a survey and analysis of all RLM works. This blueprint incorporates diverse reasoning structures (chains, trees, graphs, and nested forms), reasoning strategies (e.g., Monte Carlo Tree Search, Beam Search), RL concepts (policy, value models and others), and supervision schemes (Output-Based and Process-Based Supervision). We also provide detailed mathematical formulations and algorithmic specifications to simplify RLM implementation. By showing how schemes like LLaMA-Berry, QwQ, Journey Learning, and Graph of Thoughts fit as special cases, we demonstrate the blueprint's versatility and unifying potential. To illustrate its utility, we introduce x1, a modular implementation for rapid RLM prototyping and experimentation. Using x1 and a literature review, we provide key insights, such as multi-phase training for policy and value models, and the importance of familiar training distributions. Finally, we outline how RLMs can integrate with a broader LLM ecosystem, including tools and databases. Our work demystifies RLM construction, democratizes advanced reasoning capabilities, and fosters innovation, aiming to mitigate the gap between "rich AI" and "poor AI" by lowering barriers to RLM development and experimentation.
Bielik 7B v0.1: A Polish Language Model -- Development, Insights, and Evaluation
Oct 24, 2024
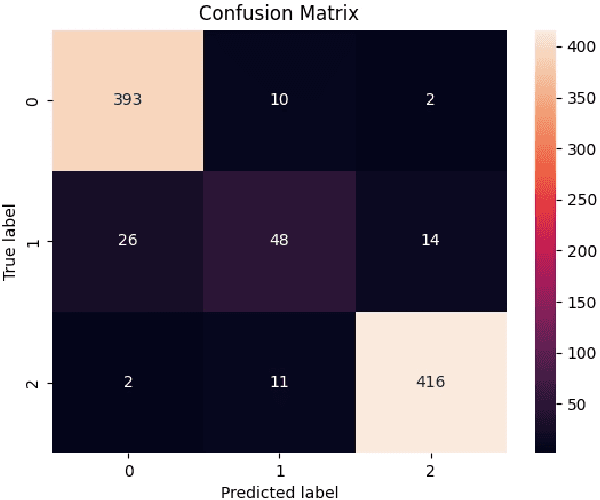
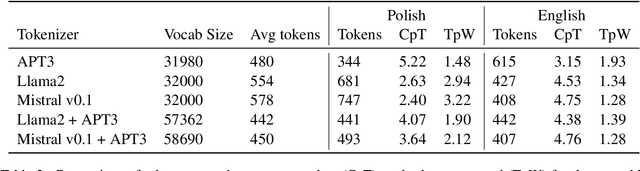
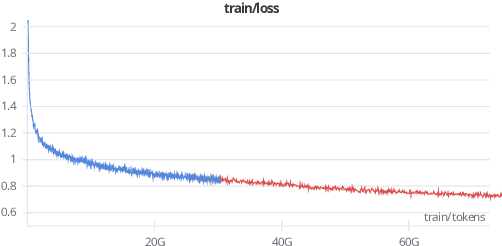
We introduce Bielik 7B v0.1, a 7-billion-parameter generative text model for Polish language processing. Trained on curated Polish corpora, this model addresses key challenges in language model development through innovative techniques. These include Weighted Instruction Cross-Entropy Loss, which balances the learning of different instruction types, and Adaptive Learning Rate, which dynamically adjusts the learning rate based on training progress. To evaluate performance, we created the Open PL LLM Leaderboard and Polish MT-Bench, novel frameworks assessing various NLP tasks and conversational abilities. Bielik 7B v0.1 demonstrates significant improvements, achieving a 9 percentage point increase in average score compared to Mistral-7B-v0.1 on the RAG Reader task. It also excels in the Polish MT-Bench, particularly in Reasoning (6.15/10) and Role-playing (7.83/10) categories. This model represents a substantial advancement in Polish language AI, offering a powerful tool for diverse linguistic applications and setting new benchmarks in the field.