 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeFontes. Part of Speech Tagging and Lemmatization of Medieval Latin Texts.A Cross-Genre Survey
Jun 29, 2024
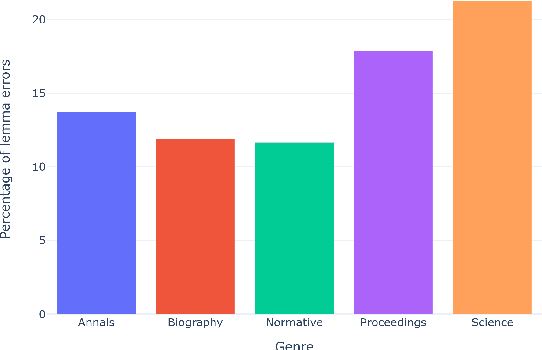
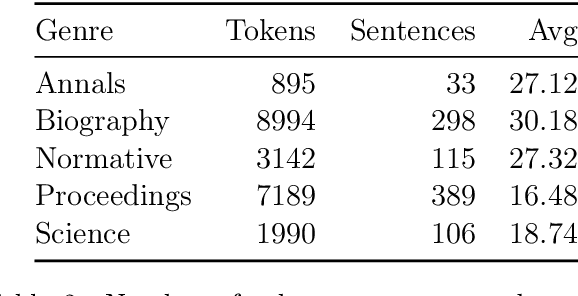
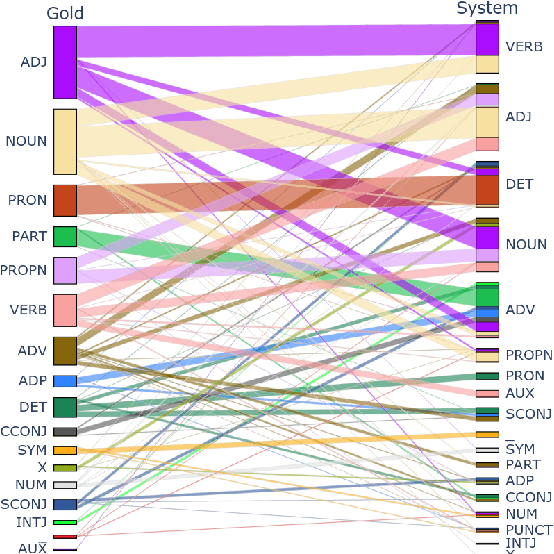
This study introduces the eFontes models for automatic linguistic annotation of Medieval Latin texts, focusing on lemmatization, part-of-speech tagging, and morphological feature determination. Using the Transformers library, these models were trained on Universal Dependencies (UD) corpora and the newly developed eFontes corpus of Polish Medieval Latin. The research evaluates the models' performance, addressing challenges such as orthographic variations and the integration of Latinized vernacular terms. The models achieved high accuracy rates: lemmatization at 92.60%, part-of-speech tagging at 83.29%, and morphological feature determination at 88.57%. The findings underscore the importance of high-quality annotated corpora and propose future enhancements, including extending the models to Named Entity Recognition.