 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Stochastic Natural Gradient Method for One-Shot Neural Architecture Search
May 21, 2019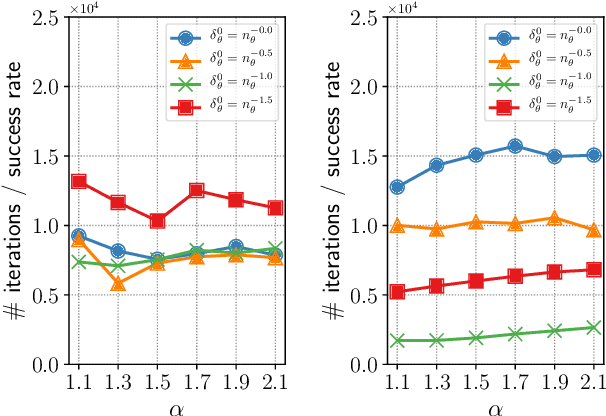
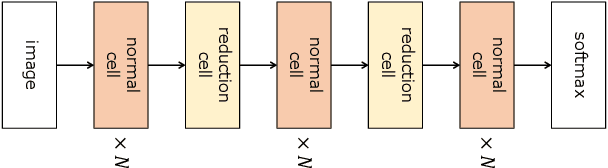
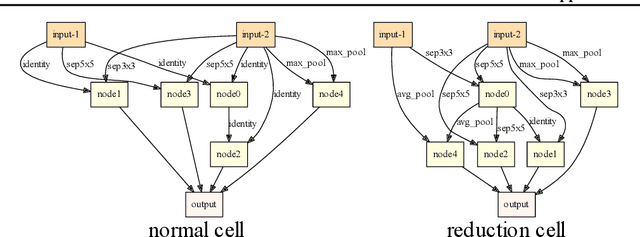
High sensitivity of neural architecture search (NAS) methods against their input such as step-size (i.e., learning rate) and search space prevents practitioners from applying them out-of-the-box to their own problems, albeit its purpose is to automate a part of tuning process. Aiming at a fast, robust, and widely-applicable NAS, we develop a generic optimization framework for NAS. We turn a coupled optimization of connection weights and neural architecture into a differentiable optimization by means of stochastic relaxation. It accepts arbitrary search space (widely-applicable) and enables to employ a gradient-based simultaneous optimization of weights and architecture (fast). We propose a stochastic natural gradient method with an adaptive step-size mechanism built upon our theoretical investigation (robust). Despite its simplicity and no problem-dependent parameter tuning, our method exhibited near state-of-the-art performances with low computational budgets both on image classification and inpainting tasks.
Parameterless Stochastic Natural Gradient Method for Discrete Optimization and its Application to Hyper-Parameter Optimization for Neural Network
Sep 18, 2018
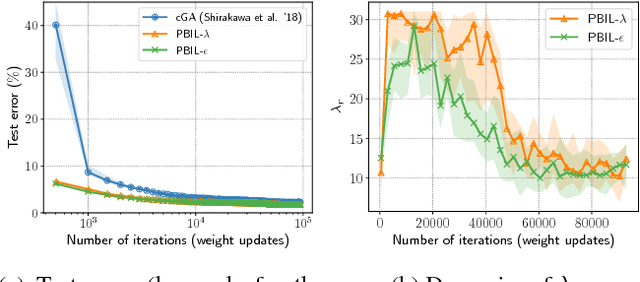

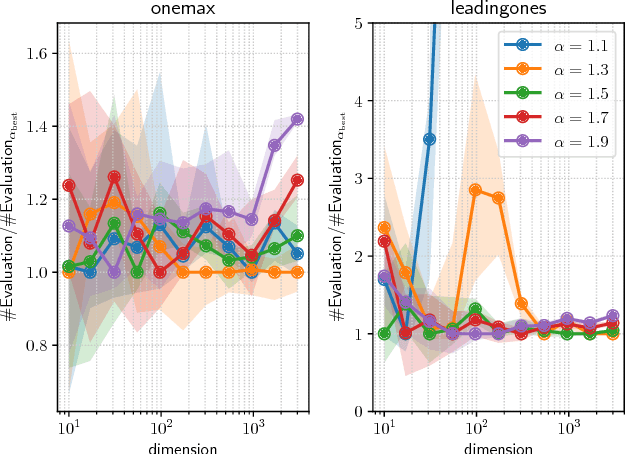
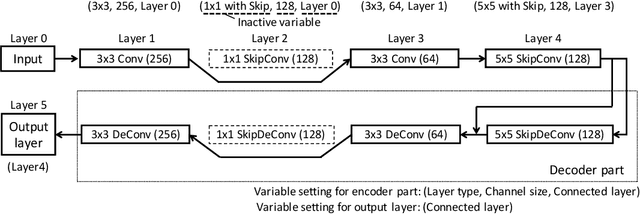
Black box discrete optimization (BBDO) appears in wide range of engineering tasks. Evolutionary or other BBDO approaches have been applied, aiming at automating necessary tuning of system parameters, such as hyper parameter tuning of machine learning based systems when being installed for a specific task. However, automation is often jeopardized by the need of strategy parameter tuning for BBDO algorithms. An expert with the domain knowledge must undergo time-consuming strategy parameter tuning. This paper proposes a parameterless BBDO algorithm based on information geometric optimization, a recent framework for black box optimization using stochastic natural gradient. Inspired by some theoretical implications, we develop an adaptation mechanism for strategy parameters of the stochastic natural gradient method for discrete search domains. The proposed algorithm is evaluated on commonly used test problems. It is further extended to two examples of simultaneous optimization of the hyper parameters and the connection weights of deep learning models, leading to a faster optimization than the existing approaches without any effort of parameter tuning.