 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtures of Gaussian Process Experts with SMC$^2$
Aug 26, 2022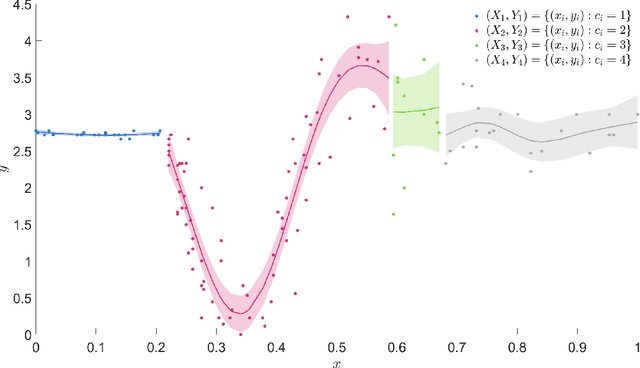



Gaussian processes are a key component of many flexible statistical and machine learning models. However, they exhibit cubic computational complexity and high memory constraints due to the need of inverting and storing a full covariance matrix. To circumvent this, mixtures of Gaussian process experts have been considered where data points are assigned to independent experts, reducing the complexity by allowing inference based on smaller, local covariance matrices. Moreover, mixtures of Gaussian process experts substantially enrich the model's flexibility, allowing for behaviors such as non-stationarity, heteroscedasticity, and discontinuities. In this work, we construct a novel inference approach based on nested sequential Monte Carlo samplers to simultaneously infer both the gating network and Gaussian process expert parameters. This greatly improves inference compared to importance sampling, particularly in settings when a stationary Gaussian process is inappropriate, while still being thoroughly parallelizable.
Convergence Rates for Stochastic Approximation on a Boundary
Aug 18, 2022

We analyze the behavior of projected stochastic gradient descent focusing on the case where the optimum is on the boundary of the constraint set and the gradient does not vanish at the optimum. Here iterates may in expectation make progress against the objective at each step. When this and an appropriate moment condition on noise holds, we prove that the convergence rate to the optimum of the constrained stochastic gradient descent will be different and typically be faster than the unconstrained stochastic gradient descent algorithm. Our results argue that the concentration around the optimum is exponentially distributed rather than normally distributed, which typically determines the limiting convergence in the unconstrained case. The methods that we develop rely on a geometric ergodicity proof. This extends a result on Markov chains by Hajek (1982) to the area of stochastic approximation algorithms. As examples, we show how the results apply to linear programming and tabular reinforcement learning.
Ultra-fast Deep Mixtures of Gaussian Process Experts
Jun 11, 2020
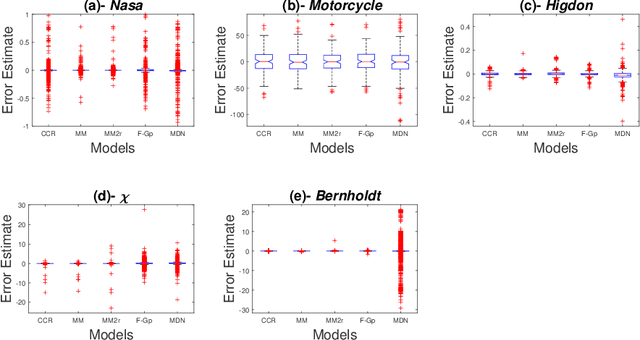
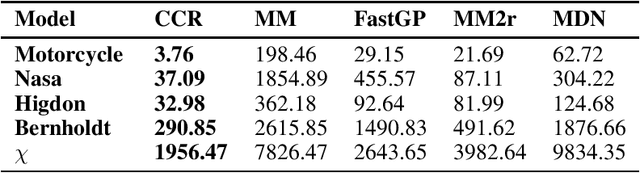
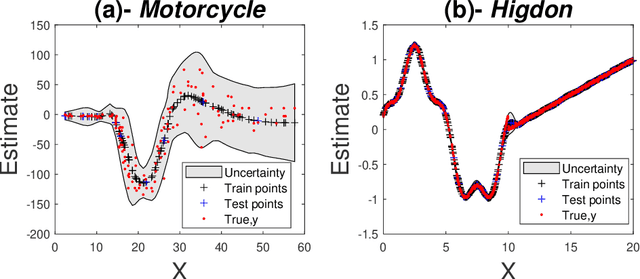
Mixtures of experts have become an indispensable tool for flexible modelling in a supervised learning context, and sparse Gaussian processes (GP) have shown promise as a leading candidate for the experts in such models. In the present article, we propose to design the gating network for selecting the experts from such mixtures of sparse GPs using a deep neural network (DNN). This combination provides a flexible, robust, and efficient model which is able to significantly outperform competing models. We furthermore consider efficient approaches to computing maximum a posteriori (MAP) estimators of these models by iteratively maximizing the distribution of experts given allocations and allocations given experts. We also show that a recently introduced method called Cluster-Classify-Regress (CCR) is capable of providing a good approximation of the optimal solution extremely quickly. This approximation can then be further refined with the iterative algorithm.