 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-fast Deep Mixtures of Gaussian Process Experts
Paper and Code
Jun 11, 2020
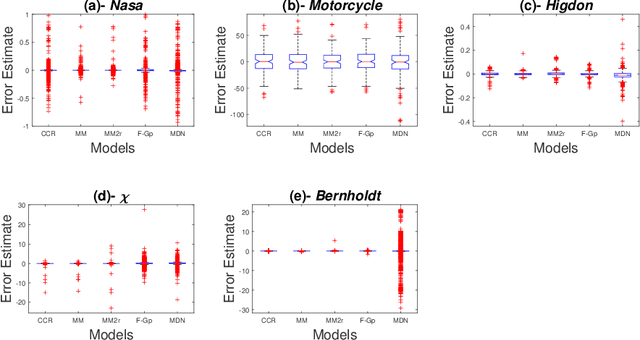
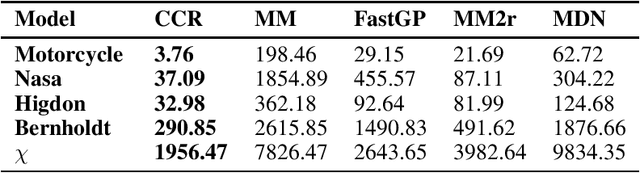
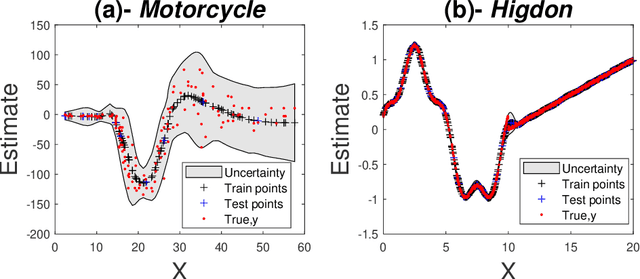
Mixtures of experts have become an indispensable tool for flexible modelling in a supervised learning context, and sparse Gaussian processes (GP) have shown promise as a leading candidate for the experts in such models. In the present article, we propose to design the gating network for selecting the experts from such mixtures of sparse GPs using a deep neural network (DNN). This combination provides a flexible, robust, and efficient model which is able to significantly outperform competing models. We furthermore consider efficient approaches to computing maximum a posteriori (MAP) estimators of these models by iteratively maximizing the distribution of experts given allocations and allocations given experts. We also show that a recently introduced method called Cluster-Classify-Regress (CCR) is capable of providing a good approximation of the optimal solution extremely quickly. This approximation can then be further refined with the iterative algorithm.