 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation For Community Standards Violation In Online Social Networks
Sep 30, 2020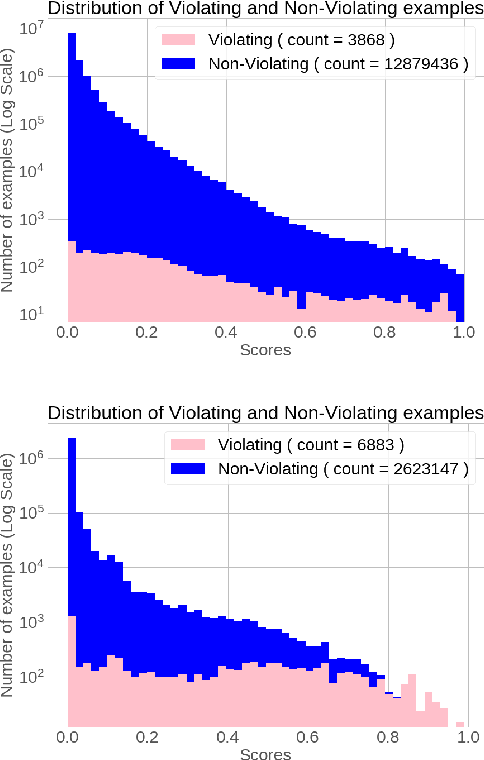
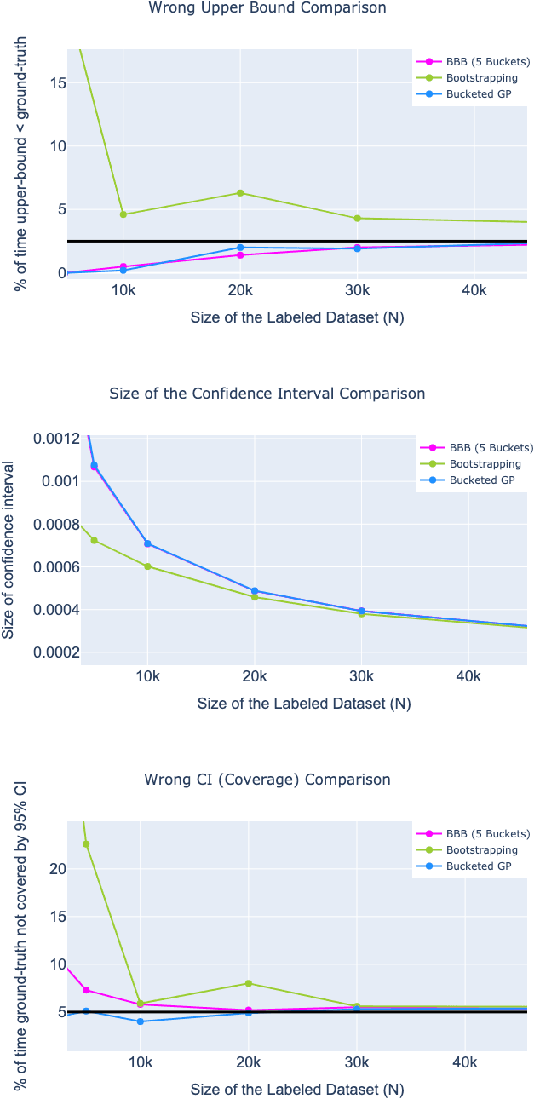
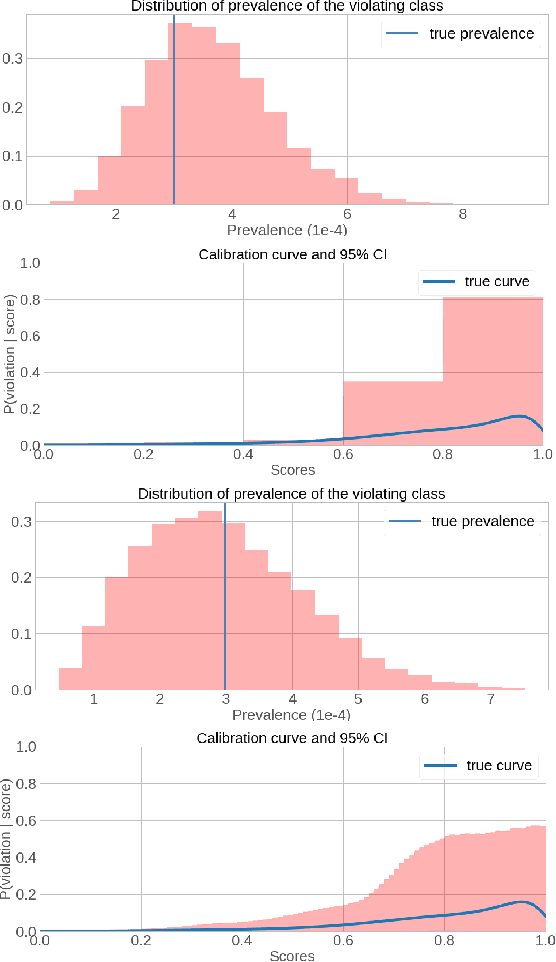
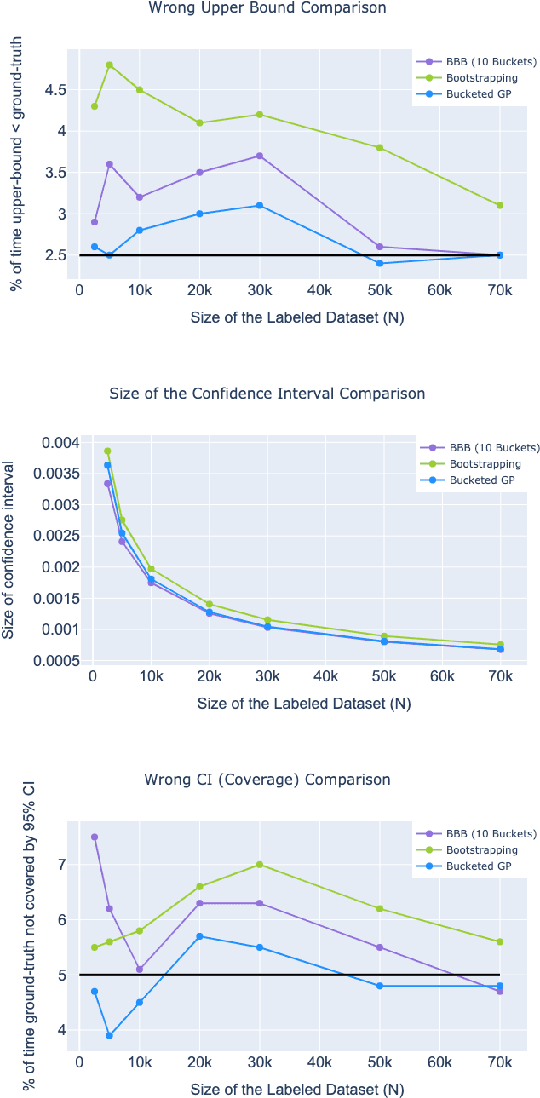
Online Social Networks (OSNs) provide a platform for users to share their thoughts and opinions with their community of friends or to the general public. In order to keep the platform safe for all users, as well as to keep it compliant with local laws, OSNs typically create a set of community standards organized into policy groups, and use Machine Learning (ML) models to identify and remove content that violates any of the policies. However, out of the billions of content that is uploaded on a daily basis only a small fraction is so unambiguously violating that it can be removed by the automated models. Prevalence estimation is the task of estimating the fraction of violating content in the residual items by sending a small sample of these items to human labelers to get ground truth labels. This task is exceedingly hard because even though we can easily get the ML scores or features for all of the billions of items we can only get ground truth labels on a few thousands of these items due to practical considerations. Indeed the prevalence can be so low that even after a judicious choice of items to be labeled there can be many days in which not even a single item is labeled violating. A pragmatic choice for such low prevalence, $10^{-4}$ to $10^{-5}$, regimes is to report the upper bound, or $97.5\%$ confidence interval, prevalence (UBP) that takes the uncertainties of the sampling and labeling processes into account and gives a smoothed estimate. In this work we present two novel techniques Bucketed-Beta-Binomial and a Bucketed-Gaussian Process for this UBP task and demonstrate on real and simulated data that it has much better coverage than the commonly used bootstrapping technique.
The Labeling Distribution Matrix : A Tool for Estimating Machine Learning Algorithm Capacity
Jan 07, 2020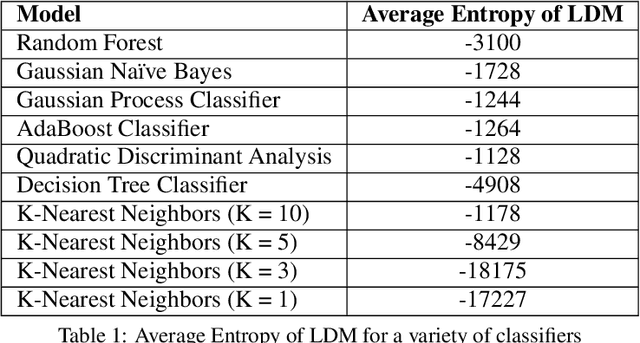
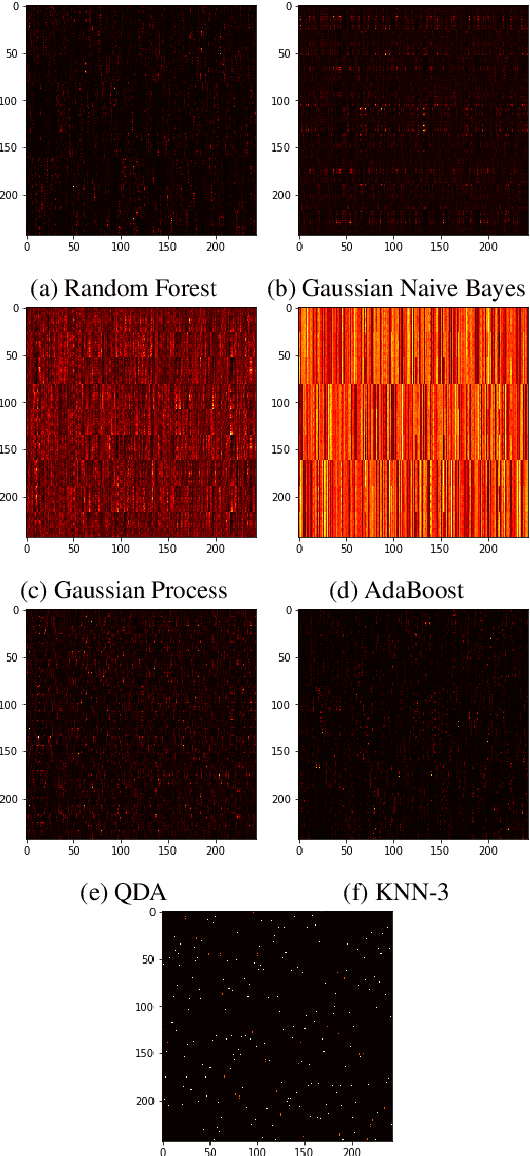
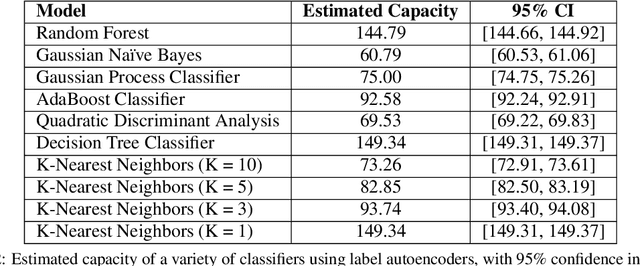
Algorithm performance in supervised learning is a combination of memorization, generalization, and luck. By estimating how much information an algorithm can memorize from a dataset, we can set a lower bound on the amount of performance due to other factors such as generalization and luck. With this goal in mind, we introduce the Labeling Distribution Matrix (LDM) as a tool for estimating the capacity of learning algorithms. The method attempts to characterize the diversity of possible outputs by an algorithm for different training datasets, using this to measure algorithm flexibility and responsiveness to data. We test the method on several supervised learning algorithms, and find that while the results are not conclusive, the LDM does allow us to gain potentially valuable insight into the prediction behavior of algorithms. We also introduce the Label Recorder as an additional tool for estimating algorithm capacity, with more promising initial results.