 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHJB Optimal Feedback Control with Deep Differential Value Functions and Action Constraints
Oct 11, 2019



Learning optimal feedback control laws capable of executing optimal trajectories is essential for many robotic applications. Such policies can be learned using reinforcement learning or planned using optimal control. While reinforcement learning is sample inefficient, optimal control only plans an optimal trajectory from a specific starting configuration. In this paper we propose deep optimal feedback control to learn an optimal feedback policy rather than a single trajectory. By exploiting the inherent structure of the robot dynamics and strictly convex action cost, we can derive principled cost functions such that the optimal policy naturally obeys the action limits, is globally optimal and stable on the training domain given the optimal value function. The corresponding optimal value function is learned end-to-end by embedding a deep differential network in the Hamilton-Jacobi-Bellmann differential equation and minimizing the error of this equality while simultaneously decreasing the discounting from short- to far-sighted to enable the learning. Our proposed approach enables us to learn an optimal feedback control law in continuous time, that in contrast to existing approaches generates an optimal trajectory from any point in state-space without the need of replanning. The resulting approach is evaluated on non-linear systems and achieves optimal feedback control, where standard optimal control methods require frequent replanning.
Deep Lagrangian Networks for end-to-end learning of energy-based control for under-actuated systems
Aug 03, 2019
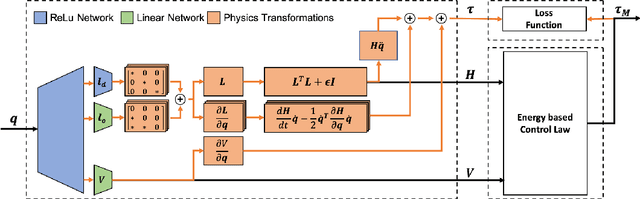

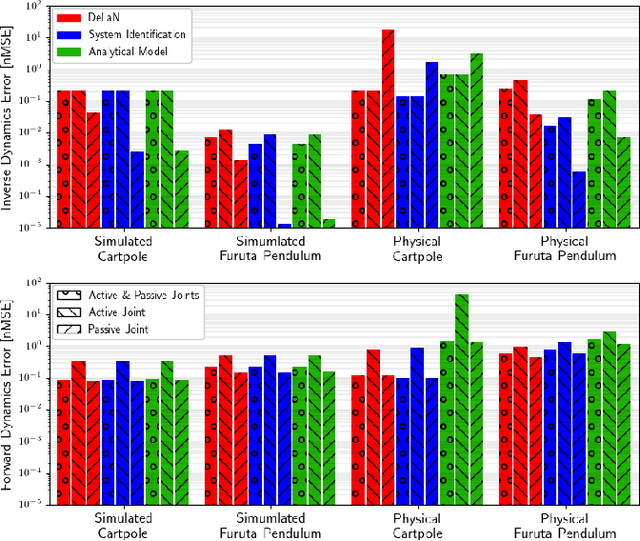
Applying Deep Learning to control has a lot of potential for enabling the intelligent design of robot control laws. Unfortunately common deep learning approaches to control, such as deep reinforcement learning, require an unrealistic amount of interaction with the real system, do not yield any performance guarantees, and do not make good use of extensive insights from model-based control. In particular, common black-box approaches -- that abandon all insight from control -- are not suitable for complex robot systems. We propose a deep control approach as a bridge between the solid theoretical foundations of energy-based control and the flexibility of deep learning. To accomplish this goal, we extend Deep Lagrangian Networks (DeLaN) to not only adhere to Lagrangian Mechanics but also ensure conservation of energy and passivity of the learned representation. This novel extension is embedded within generic model-based control laws to enable energy control of under-actuated systems. The resulting DeLaN for energy control (DeLaN 4EC) is the first model learning approach using generic function approximation that is capable of learning energy control. DeLaN 4EC exhibits excellent real-time control on the physical Furuta Pendulum and learns to swing-up the pendulum while the control law using system identification does not.