 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation with Structured Chain-of-Thought for Text-to-SQL
Dec 18, 2025Deploying accurate Text-to-SQL systems at the enterprise level faces a difficult trilemma involving cost, security and performance. Current solutions force enterprises to choose between expensive, proprietary Large Language Models (LLMs) and low-performing Small Language Models (SLMs). Efforts to improve SLMs often rely on distilling reasoning from large LLMs using unstructured Chain-of-Thought (CoT) traces, a process that remains inherently ambiguous. Instead, we hypothesize that a formal, structured reasoning representation provides a clearer, more reliable teaching signal, as the Text-to-SQL task requires explicit and precise logical steps. To evaluate this hypothesis, we propose Struct-SQL, a novel Knowledge Distillation (KD) framework that trains an SLM to emulate a powerful large LLM. Consequently, we adopt a query execution plan as a formal blueprint to derive this structured reasoning. Our SLM, distilled with structured CoT, achieves an absolute improvement of 8.1% over an unstructured CoT distillation baseline. A detailed error analysis reveals that a key factor in this gain is a marked reduction in syntactic errors. This demonstrates that teaching a model to reason using a structured logical blueprint is beneficial for reliable SQL generation in SLMs.
Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents
Jun 23, 2021
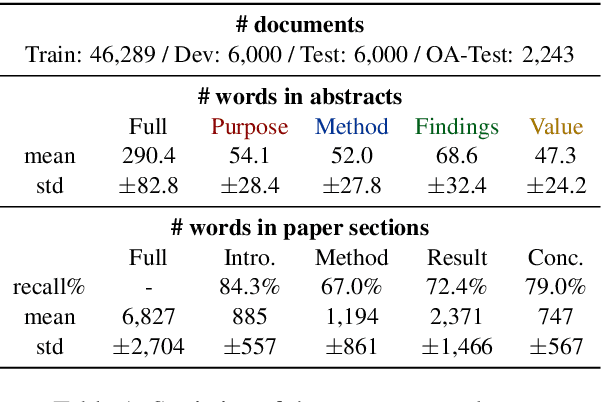

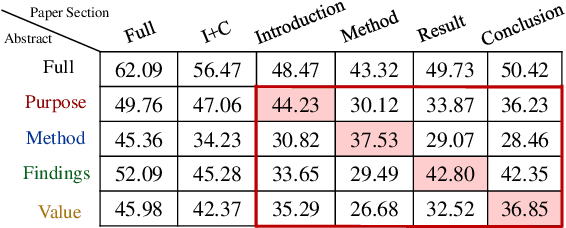
Faceted summarization provides briefings of a document from different perspectives. Readers can quickly comprehend the main points of a long document with the help of a structured outline. However, little research has been conducted on this subject, partially due to the lack of large-scale faceted summarization datasets. In this study, we present FacetSum, a faceted summarization benchmark built on Emerald journal articles, covering a diverse range of domains. Different from traditional document-summary pairs, FacetSum provides multiple summaries, each targeted at specific sections of a long document, including the purpose, method, findings, and value. Analyses and empirical results on our dataset reveal the importance of bringing structure into summaries. We believe FacetSum will spur further advances in summarization research and foster the development of NLP systems that can leverage the structured information in both long texts and summaries.
Generating Diverse Numbers of Diverse Keyphrases
Oct 11, 2018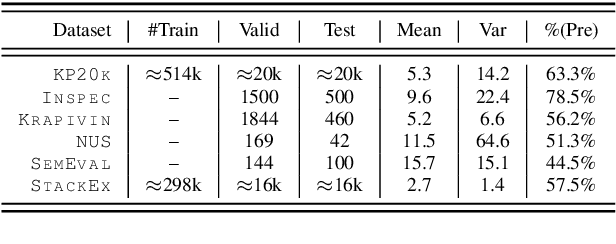

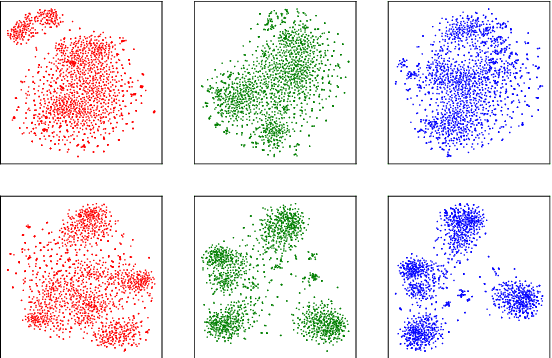
Existing keyphrase generation studies suffer from the problems of generating duplicate phrases and deficient evaluation based on a fixed number of predicted phrases. We propose a recurrent generative model that generates multiple keyphrases sequentially from a text, with specific modules that promote generation diversity. We further propose two new metrics that consider a variable number of phrases. With both existing and proposed evaluation setups, our model demonstrates superior performance to baselines on three types of keyphrase generation datasets, including two newly introduced in this work: StackExchange and TextWorld ACG. In contrast to previous keyphrase generation approaches, our model generates sets of diverse keyphrases of a variable number.