 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Interactive A2C for Improved RL in Open Many-Agent Systems
May 09, 2023There is a prevalence of multiagent reinforcement learning (MARL) methods that engage in centralized training. But, these methods involve obtaining various types of information from the other agents, which may not be feasible in competitive or adversarial settings. A recent method, the interactive advantage actor critic (IA2C), engages in decentralized training coupled with decentralized execution, aiming to predict the other agents' actions from possibly noisy observations. In this paper, we present the latent IA2C that utilizes an encoder-decoder architecture to learn a latent representation of the hidden state and other agents' actions. Our experiments in two domains -- each populated by many agents -- reveal that the latent IA2C significantly improves sample efficiency by reducing variance and converging faster. Additionally, we introduce open versions of these domains where the agent population may change over time, and evaluate on these instances as well.
Many Agent Reinforcement Learning Under Partial Observability
Jun 17, 2021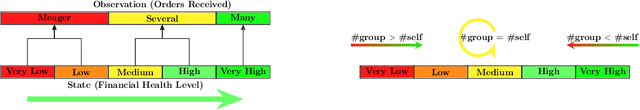
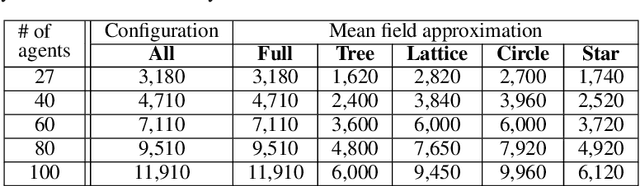
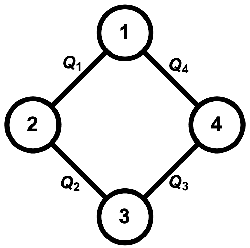
Recent renewed interest in multi-agent reinforcement learning (MARL) has generated an impressive array of techniques that leverage deep reinforcement learning, primarily actor-critic architectures, and can be applied to a limited range of settings in terms of observability and communication. However, a continuing limitation of much of this work is the curse of dimensionality when it comes to representations based on joint actions, which grow exponentially with the number of agents. In this paper, we squarely focus on this challenge of scalability. We apply the key insight of action anonymity, which leads to permutation invariance of joint actions, to two recently presented deep MARL algorithms, MADDPG and IA2C, and compare these instantiations to another recent technique that leverages action anonymity, viz., mean-field MARL. We show that our instantiations can learn the optimal behavior in a broader class of agent networks than the mean-field method, using a recently introduced pragmatic domain.
Cooperative-Competitive Reinforcement Learning with History-Dependent Rewards
Oct 15, 2020

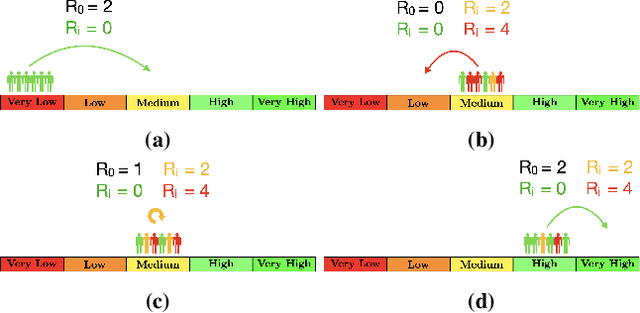
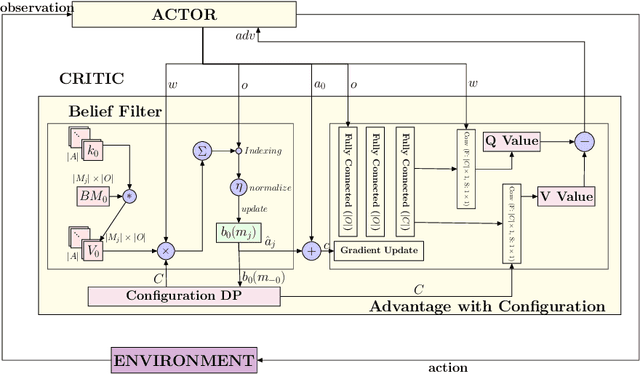
Consider a typical organization whose worker agents seek to collectively cooperate for its general betterment. However, each individual agent simultaneously seeks to act to secure a larger chunk than its co-workers of the annual increment in compensation, which usually comes from a {\em fixed} pot. As such, the individual agent in the organization must cooperate and compete. Another feature of many organizations is that a worker receives a bonus, which is often a fraction of previous year's total profit. As such, the agent derives a reward that is also partly dependent on historical performance. How should the individual agent decide to act in this context? Few methods for the mixed cooperative-competitive setting have been presented in recent years, but these are challenged by problem domains whose reward functions do not depend on the current state and action only. Recent deep multi-agent reinforcement learning (MARL) methods using long short-term memory (LSTM) may be used, but these adopt a joint perspective to the interaction or require explicit exchange of information among the agents to promote cooperation, which may not be possible under competition. In this paper, we first show that the agent's decision-making problem can be modeled as an interactive partially observable Markov decision process (I-POMDP) that captures the dynamic of a history-dependent reward. We present an interactive advantage actor-critic method (IA2C$^+$), which combines the independent advantage actor-critic network with a belief filter that maintains a belief distribution over other agents' models. Empirical results show that IA2C$^+$ learns the optimal policy faster and more robustly than several other baselines including one that uses a LSTM, even when attributed models are incorrect.
Reinforcement Learning for Heterogeneous Teams with PALO Bounds
May 23, 2018
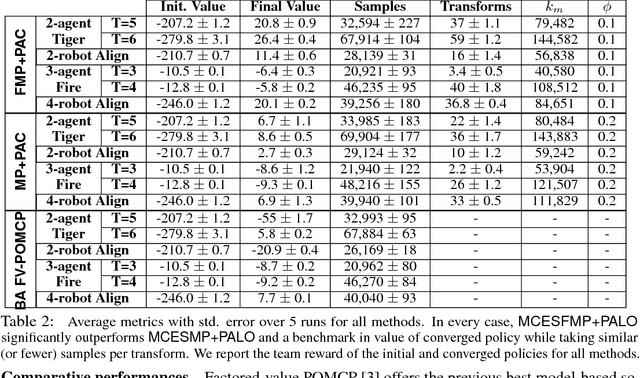
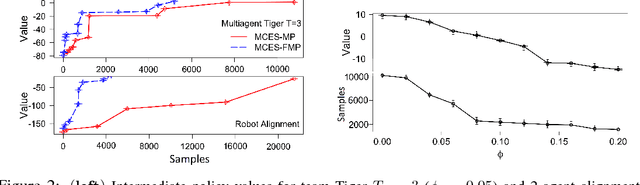
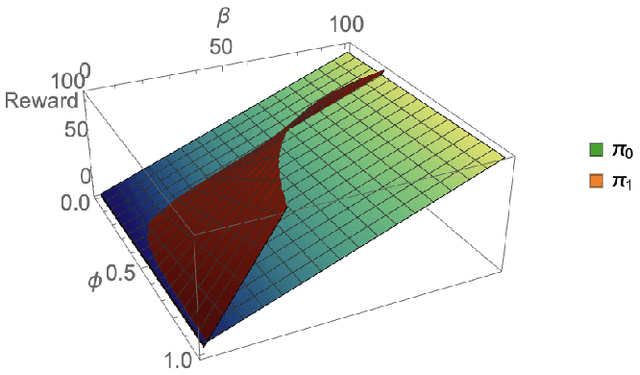
We introduce reinforcement learning for heterogeneous teams in which rewards for an agent are additively factored into local costs, stimuli unique to each agent, and global rewards, those shared by all agents in the domain. Motivating domains include coordination of varied robotic platforms, which incur different costs for the same action, but share an overall goal. We present two templates for learning in this setting with factored rewards: a generalization of Perkins' Monte Carlo exploring starts for POMDPs to canonical MPOMDPs, with a single policy mapping joint observations of all agents to joint actions (MCES-MP); and another with each agent individually mapping joint observations to their own action (MCES-FMP). We use probably approximately local optimal (PALO) bounds to analyze sample complexity, instantiating these templates to PALO learning. We promote sample efficiency by including a policy space pruning technique, and evaluate the approaches on three domains of heterogeneous agents demonstrating that MCES-FMP yields improved policies in less samples compared to MCES-MP and a previous benchmark.