 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasimetric Value Functions with Dense Rewards
Sep 13, 2024
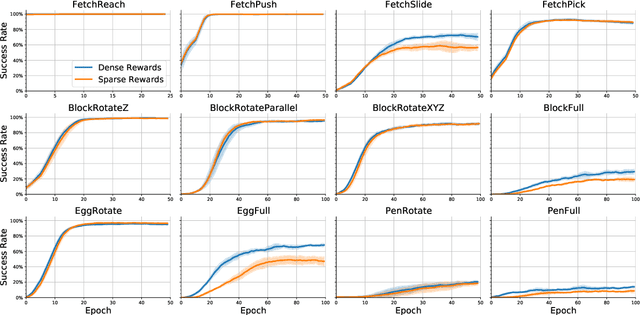
As a generalization of reinforcement learning (RL) to parametrizable goals, goal conditioned RL (GCRL) has a broad range of applications, particularly in challenging tasks in robotics. Recent work has established that the optimal value function of GCRL $Q^\ast(s,a,g)$ has a quasimetric structure, leading to targetted neural architectures that respect such structure. However, the relevant analyses assume a sparse reward setting -- a known aggravating factor to sample complexity. We show that the key property underpinning a quasimetric, viz., the triangle inequality, is preserved under a dense reward setting as well. Contrary to earlier findings where dense rewards were shown to be detrimental to GCRL, we identify the key condition necessary for triangle inequality. Dense reward functions that satisfy this condition can only improve, never worsen, sample complexity. This opens up opportunities to train efficient neural architectures with dense rewards, compounding their benefits to sample complexity. We evaluate this proposal in 12 standard benchmark environments in GCRL featuring challenging continuous control tasks. Our empirical results confirm that training a quasimetric value function in our dense reward setting indeed outperforms training with sparse rewards.
Latent Interactive A2C for Improved RL in Open Many-Agent Systems
May 09, 2023There is a prevalence of multiagent reinforcement learning (MARL) methods that engage in centralized training. But, these methods involve obtaining various types of information from the other agents, which may not be feasible in competitive or adversarial settings. A recent method, the interactive advantage actor critic (IA2C), engages in decentralized training coupled with decentralized execution, aiming to predict the other agents' actions from possibly noisy observations. In this paper, we present the latent IA2C that utilizes an encoder-decoder architecture to learn a latent representation of the hidden state and other agents' actions. Our experiments in two domains -- each populated by many agents -- reveal that the latent IA2C significantly improves sample efficiency by reducing variance and converging faster. Additionally, we introduce open versions of these domains where the agent population may change over time, and evaluate on these instances as well.
Many Agent Reinforcement Learning Under Partial Observability
Jun 17, 2021
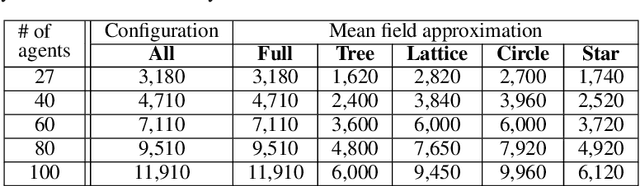
Recent renewed interest in multi-agent reinforcement learning (MARL) has generated an impressive array of techniques that leverage deep reinforcement learning, primarily actor-critic architectures, and can be applied to a limited range of settings in terms of observability and communication. However, a continuing limitation of much of this work is the curse of dimensionality when it comes to representations based on joint actions, which grow exponentially with the number of agents. In this paper, we squarely focus on this challenge of scalability. We apply the key insight of action anonymity, which leads to permutation invariance of joint actions, to two recently presented deep MARL algorithms, MADDPG and IA2C, and compare these instantiations to another recent technique that leverages action anonymity, viz., mean-field MARL. We show that our instantiations can learn the optimal behavior in a broader class of agent networks than the mean-field method, using a recently introduced pragmatic domain.
Cooperative-Competitive Reinforcement Learning with History-Dependent Rewards
Oct 15, 2020

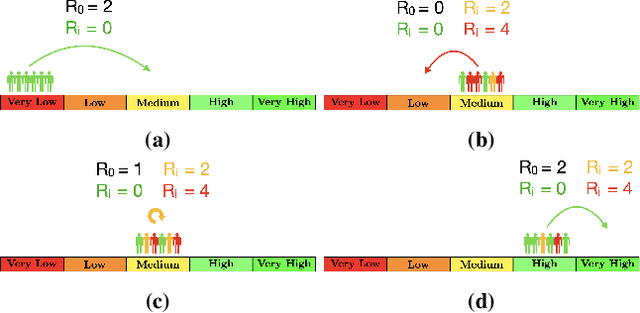
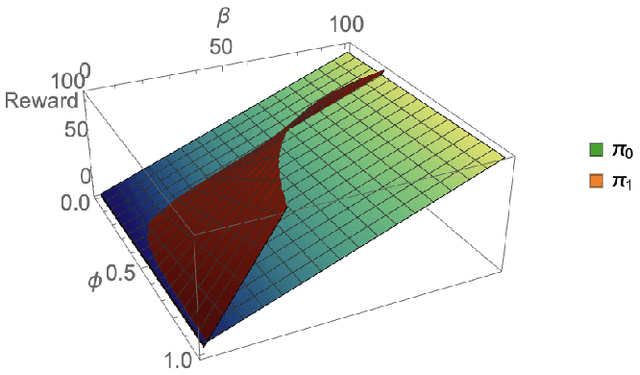
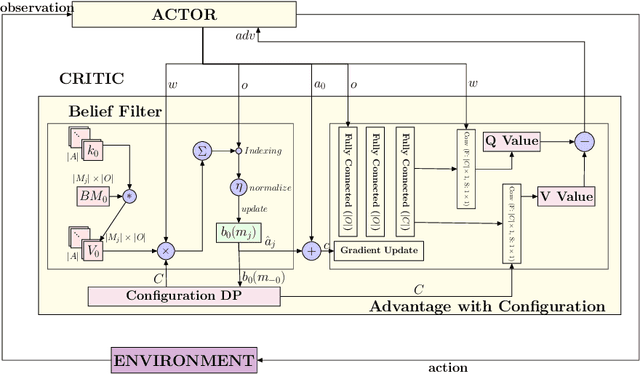
Consider a typical organization whose worker agents seek to collectively cooperate for its general betterment. However, each individual agent simultaneously seeks to act to secure a larger chunk than its co-workers of the annual increment in compensation, which usually comes from a {\em fixed} pot. As such, the individual agent in the organization must cooperate and compete. Another feature of many organizations is that a worker receives a bonus, which is often a fraction of previous year's total profit. As such, the agent derives a reward that is also partly dependent on historical performance. How should the individual agent decide to act in this context? Few methods for the mixed cooperative-competitive setting have been presented in recent years, but these are challenged by problem domains whose reward functions do not depend on the current state and action only. Recent deep multi-agent reinforcement learning (MARL) methods using long short-term memory (LSTM) may be used, but these adopt a joint perspective to the interaction or require explicit exchange of information among the agents to promote cooperation, which may not be possible under competition. In this paper, we first show that the agent's decision-making problem can be modeled as an interactive partially observable Markov decision process (I-POMDP) that captures the dynamic of a history-dependent reward. We present an interactive advantage actor-critic method (IA2C$^+$), which combines the independent advantage actor-critic network with a belief filter that maintains a belief distribution over other agents' models. Empirical results show that IA2C$^+$ learns the optimal policy faster and more robustly than several other baselines including one that uses a LSTM, even when attributed models are incorrect.
Maximum Entropy Multi-Task Inverse RL
Apr 27, 2020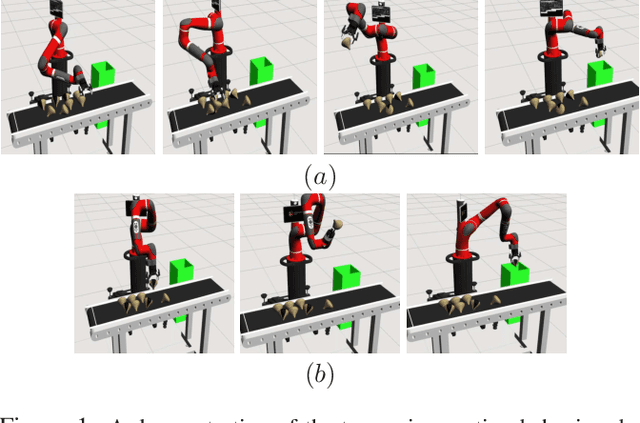
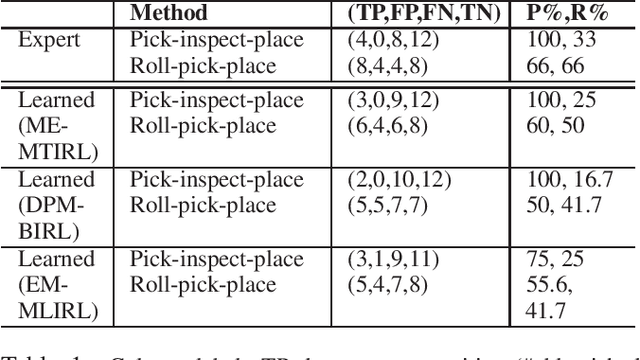
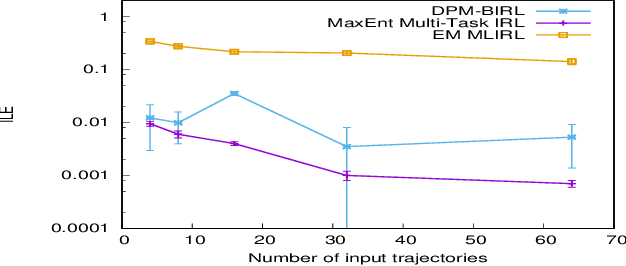
Multi-task IRL allows for the possibility that the expert could be switching between multiple ways of solving the same problem, or interleaving demonstrations of multiple tasks. The learner aims to learn the multiple reward functions that guide these ways of solving the problem. We present a new method for multi-task IRL that generalizes the well-known maximum entropy approach to IRL by combining it with the Dirichlet process based clustering of the observed input. This yields a single nonlinear optimization problem, called MaxEnt Multi-task IRL, which can be solved using the Lagrangian relaxation and gradient descent methods. We evaluate MaxEnt Multi-task IRL in simulation on the robotic task of sorting onions on a processing line where the expert utilizes multiple ways of detecting and removing blemished onions. The method is able to learn the underlying reward functions to a high level of accuracy and it improves on the previous approaches to multi-task IRL.
A Framework and Method for Online Inverse Reinforcement Learning
May 21, 2018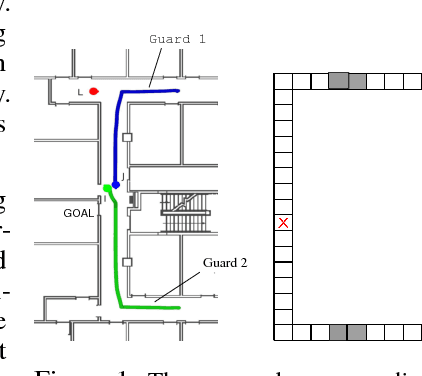
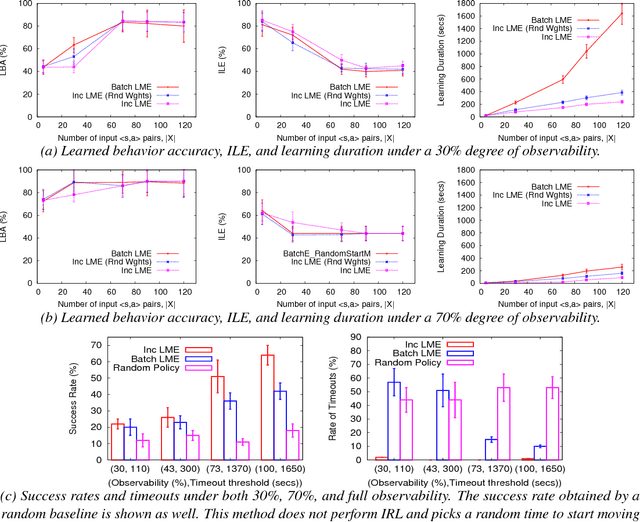
Inverse reinforcement learning (IRL) is the problem of learning the preferences of an agent from the observations of its behavior on a task. While this problem has been well investigated, the related problem of {\em online} IRL---where the observations are incrementally accrued, yet the demands of the application often prohibit a full rerun of an IRL method---has received relatively less attention. We introduce the first formal framework for online IRL, called incremental IRL (I2RL), and a new method that advances maximum entropy IRL with hidden variables, to this setting. Our formal analysis shows that the new method has a monotonically improving performance with more demonstration data, as well as probabilistically bounded error, both under full and partial observability. Experiments in a simulated robotic application of penetrating a continuous patrol under occlusion shows the relatively improved performance and speed up of the new method and validates the utility of online IRL.