 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy Multi-Task Inverse RL
Apr 27, 2020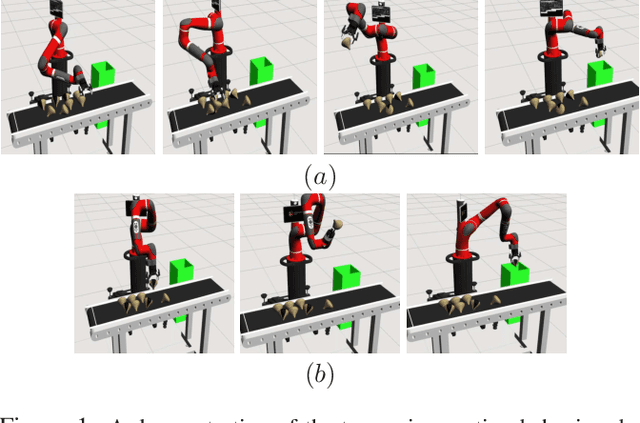
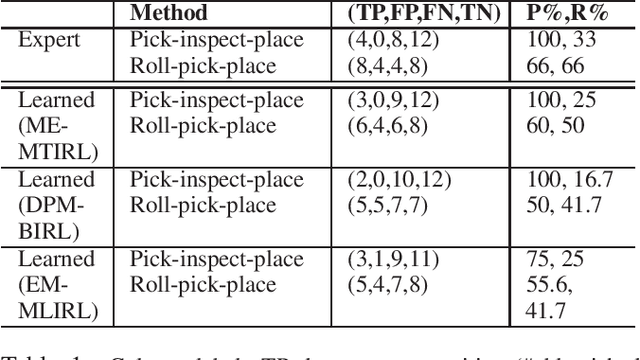
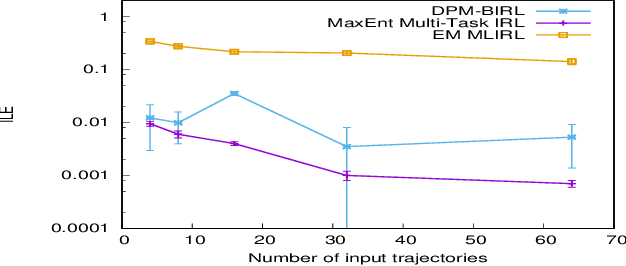
Multi-task IRL allows for the possibility that the expert could be switching between multiple ways of solving the same problem, or interleaving demonstrations of multiple tasks. The learner aims to learn the multiple reward functions that guide these ways of solving the problem. We present a new method for multi-task IRL that generalizes the well-known maximum entropy approach to IRL by combining it with the Dirichlet process based clustering of the observed input. This yields a single nonlinear optimization problem, called MaxEnt Multi-task IRL, which can be solved using the Lagrangian relaxation and gradient descent methods. We evaluate MaxEnt Multi-task IRL in simulation on the robotic task of sorting onions on a processing line where the expert utilizes multiple ways of detecting and removing blemished onions. The method is able to learn the underlying reward functions to a high level of accuracy and it improves on the previous approaches to multi-task IRL.
A Survey of Inverse Reinforcement Learning: Challenges, Methods and Progress
Jun 18, 2018


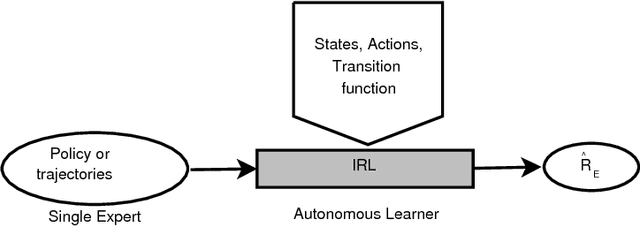
Inverse reinforcement learning is the problem of inferring the reward function of an observed agent, given its policy or behavior. Researchers perceive IRL both as a problem and as a class of methods. By categorically surveying the current literature in IRL, this article serves as a reference for researchers and practitioners in machine learning to understand the challenges of IRL and select the approaches best suited for the problem on hand. The survey formally introduces the IRL problem along with its central challenges which include accurate inference, generalizability, correctness of prior knowledge, and growth in solution complexity with problem size. The article elaborates how the current methods mitigate these challenges. We further discuss the extensions of traditional IRL methods: (i) inaccurate and incomplete perception, (ii) incomplete model, (iii) multiple rewards, and (iv) non-linear reward functions. This discussion concludes with some broad advances in the research area and currently open research questions.
A Framework and Method for Online Inverse Reinforcement Learning
May 21, 2018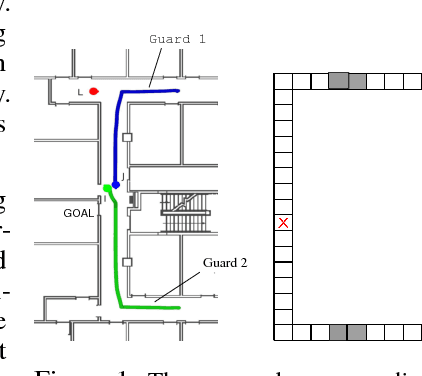
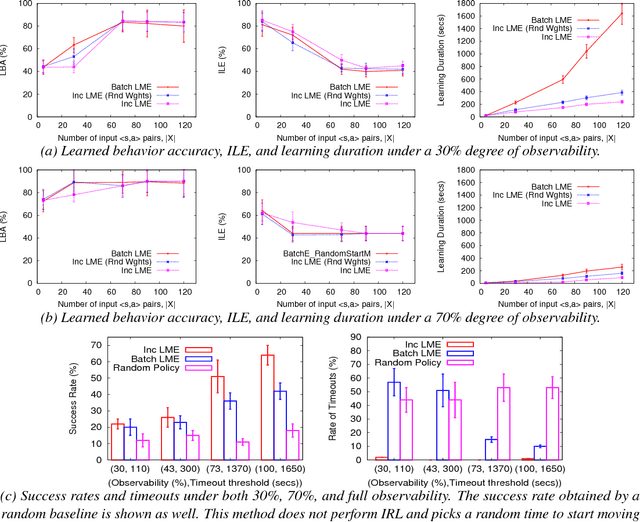
Inverse reinforcement learning (IRL) is the problem of learning the preferences of an agent from the observations of its behavior on a task. While this problem has been well investigated, the related problem of {\em online} IRL---where the observations are incrementally accrued, yet the demands of the application often prohibit a full rerun of an IRL method---has received relatively less attention. We introduce the first formal framework for online IRL, called incremental IRL (I2RL), and a new method that advances maximum entropy IRL with hidden variables, to this setting. Our formal analysis shows that the new method has a monotonically improving performance with more demonstration data, as well as probabilistically bounded error, both under full and partial observability. Experiments in a simulated robotic application of penetrating a continuous patrol under occlusion shows the relatively improved performance and speed up of the new method and validates the utility of online IRL.