 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Event-Role Structure-based Multi-Channel Document-Level Event Extraction
Jun 30, 2023



Document-level event extraction is a long-standing challenging information retrieval problem involving a sequence of sub-tasks: entity extraction, event type judgment, and event type-specific multi-event extraction. However, addressing the problem as multiple learning tasks leads to increased model complexity. Also, existing methods insufficiently utilize the correlation of entities crossing different events, resulting in limited event extraction performance. This paper introduces a novel framework for document-level event extraction, incorporating a new data structure called token-event-role and a multi-channel argument role prediction module. The proposed data structure enables our model to uncover the primary role of tokens in multiple events, facilitating a more comprehensive understanding of event relationships. By leveraging the multi-channel prediction module, we transform entity and multi-event extraction into a single task of predicting token-event pairs, thereby reducing the overall parameter size and enhancing model efficiency. The results demonstrate that our approach outperforms the state-of-the-art method by 9.5 percentage points in terms of the F1 score, highlighting its superior performance in event extraction. Furthermore, an ablation study confirms the significant value of the proposed data structure in improving event extraction tasks, further validating its importance in enhancing the overall performance of the framework.
Route Optimization via Environment-Aware Deep Network and Reinforcement Learning
Nov 16, 2021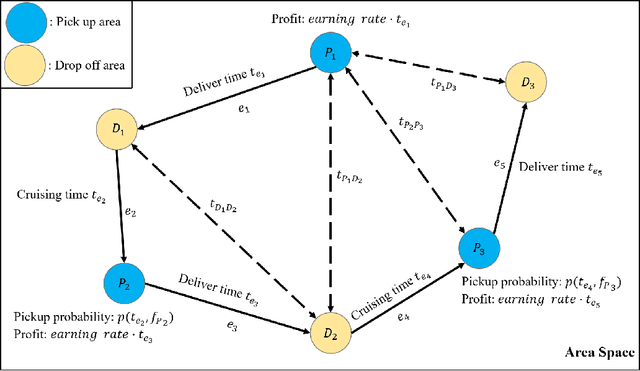
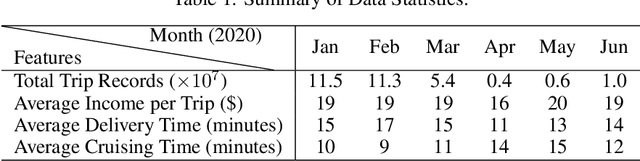
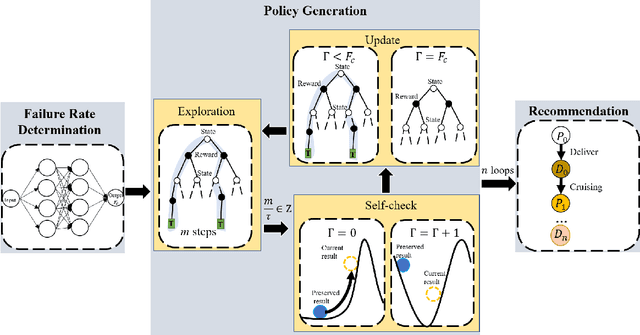
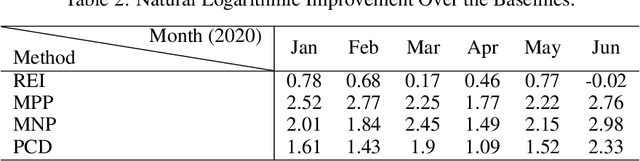
Vehicle mobility optimization in urban areas is a long-standing problem in smart city and spatial data analysis. Given the complex urban scenario and unpredictable social events, our work focuses on developing a mobile sequential recommendation system to maximize the profitability of vehicle service providers (e.g., taxi drivers). In particular, we treat the dynamic route optimization problem as a long-term sequential decision-making task. A reinforcement-learning framework is proposed to tackle this problem, by integrating a self-check mechanism and a deep neural network for customer pick-up point monitoring. To account for unexpected situations (e.g., the COVID-19 outbreak), our method is designed to be capable of handling related environment changes with a self-adaptive parameter determination mechanism. Based on the yellow taxi data in New York City and vicinity before and after the COVID-19 outbreak, we have conducted comprehensive experiments to evaluate the effectiveness of our method. The results show consistently excellent performance, from hourly to weekly measures, to support the superiority of our method over the state-of-the-art methods (i.e., with more than 98% improvement in terms of the profitability for taxi drivers).
Weighted Aggregating Stochastic Gradient Descent for Parallel Deep Learning
Apr 07, 2020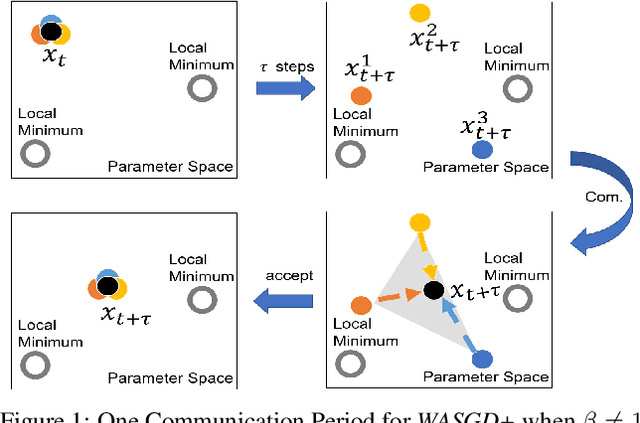

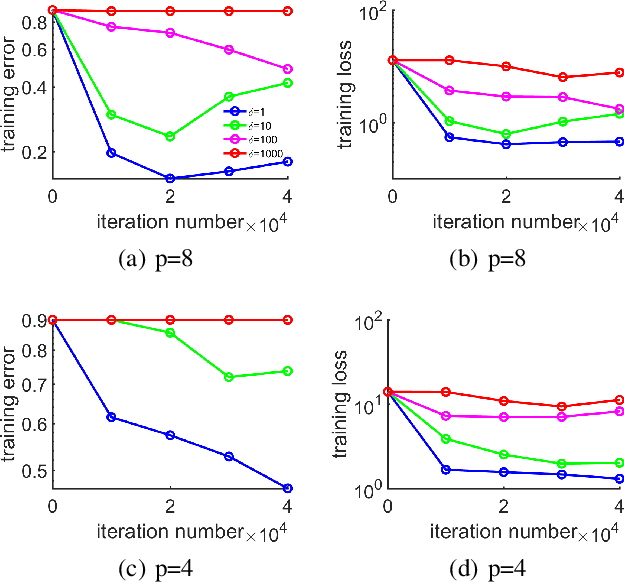

This paper investigates the stochastic optimization problem with a focus on developing scalable parallel algorithms for deep learning tasks. Our solution involves a reformation of the objective function for stochastic optimization in neural network models, along with a novel parallel strategy, coined weighted aggregating stochastic gradient descent (WASGD). Following a theoretical analysis on the characteristics of the new objective function, WASGD introduces a decentralized weighted aggregating scheme based on the performance of local workers. Without any center variable, the new method automatically assesses the importance of local workers and accepts them according to their contributions. Furthermore, we have developed an enhanced version of the method, WASGD+, by (1) considering a designed sample order and (2) applying a more advanced weight evaluating function. To validate the new method, we benchmark our schemes against several popular algorithms including the state-of-the-art techniques (e.g., elastic averaging SGD) in training deep neural networks for classification tasks. Comprehensive experiments have been conducted on four classic datasets, including the CIFAR-100, CIFAR-10, Fashion-MNIST, and MNIST. The subsequent results suggest the superiority of the WASGD scheme in accelerating the training of deep architecture. Better still, the enhanced version, WASGD+, has been shown to be a significant improvement over its basic version.
Enhancing Domain Word Embedding via Latent Semantic Imputation
May 21, 2019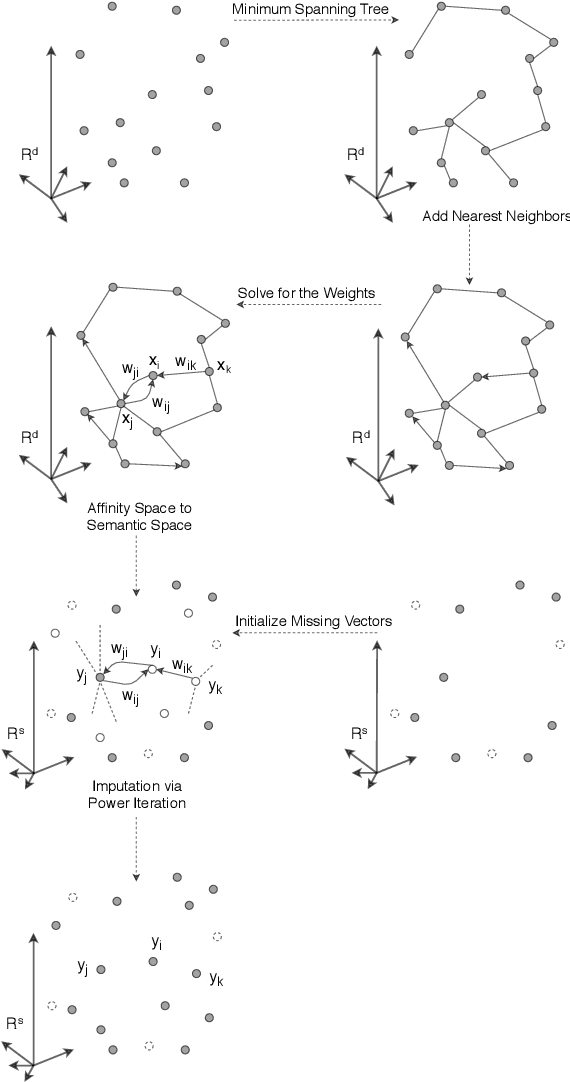
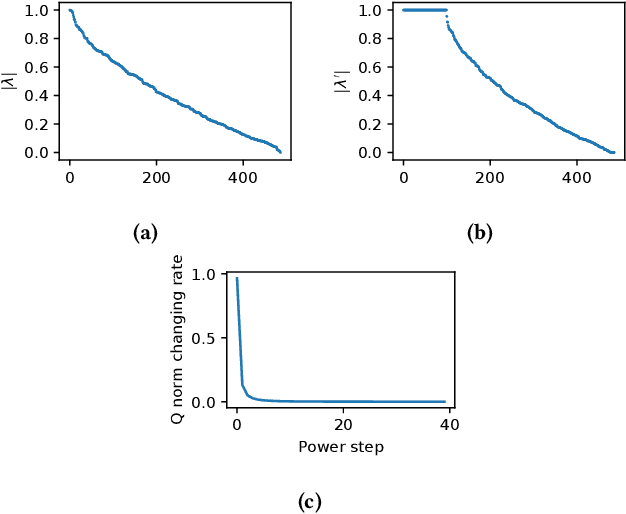
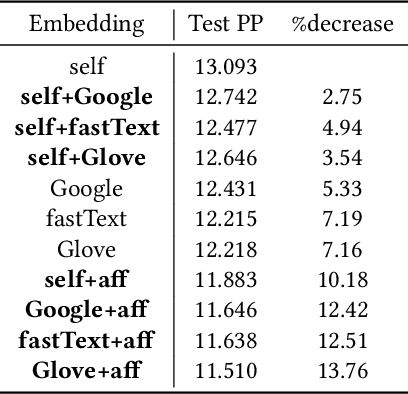
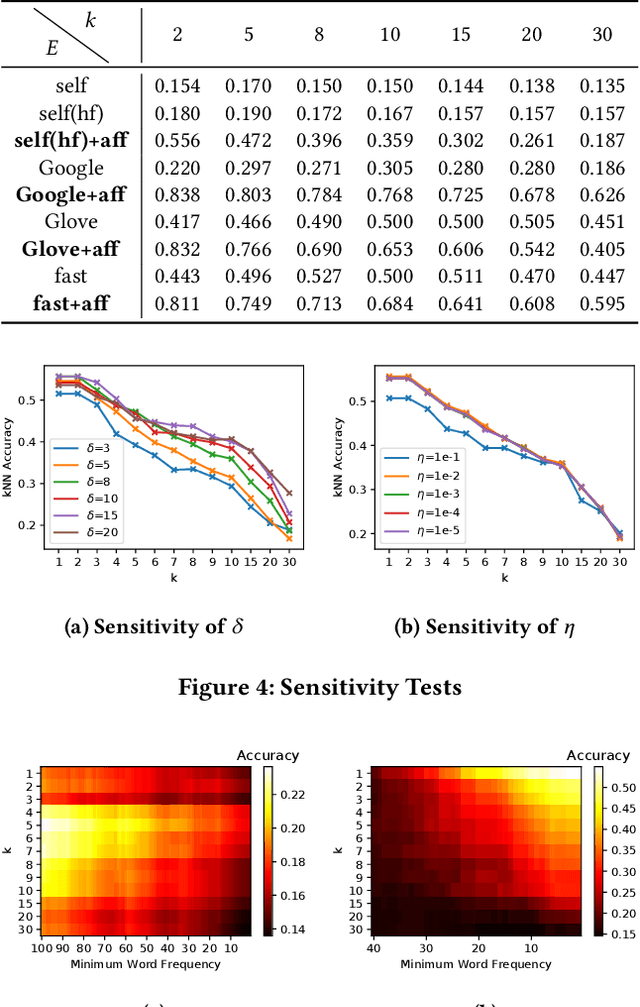
We present a novel method named Latent Semantic Imputation (LSI) to transfer external knowledge into semantic space for enhancing word embedding. The method integrates graph theory to extract the latent manifold structure of the entities in the affinity space and leverages non-negative least squares with standard simplex constraints and power iteration method to derive spectral embeddings. It provides an effective and efficient approach to combining entity representations defined in different Euclidean spaces. Specifically, our approach generates and imputes reliable embedding vectors for low-frequency words in the semantic space and benefits downstream language tasks that depend on word embedding. We conduct comprehensive experiments on a carefully designed classification problem and language modeling and demonstrate the superiority of the enhanced embedding via LSI over several well-known benchmark embeddings. We also confirm the consistency of the results under different parameter settings of our method.