 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEGAP: Dual Event-Guided Adaptive Prefixes for Templated-Based Event Argument Extraction Model with Slot Querying
May 22, 2024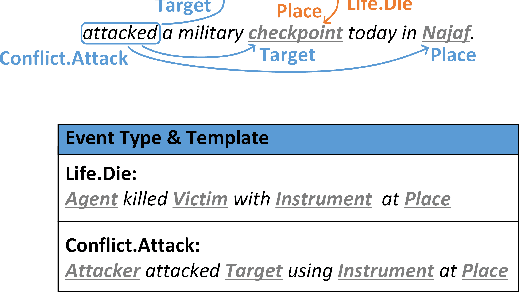
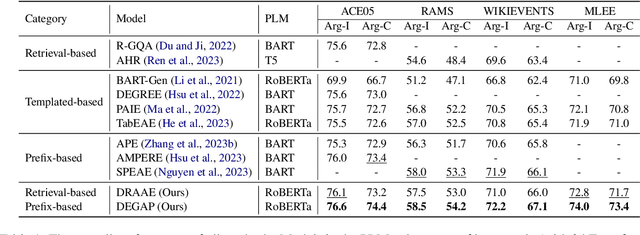
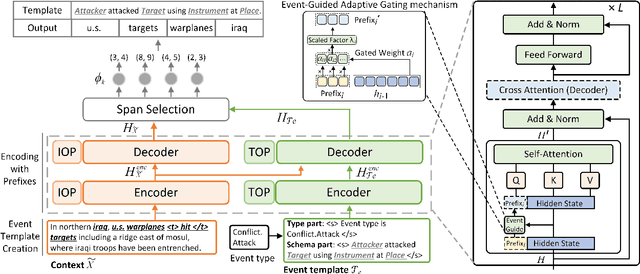
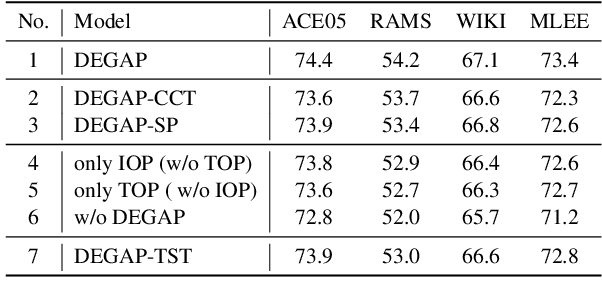
Recent advancements in event argument extraction (EAE) involve incorporating beneficial auxiliary information into models during training and inference, such as retrieved instances and event templates. Additionally, some studies introduce learnable prefix vectors to models. These methods face three challenges: (1) insufficient utilization of relevant event instances due to deficiencies in retrieval; (2) neglect of important information provided by relevant event templates; (3) the advantages of prefixes are constrained due to their inability to meet the specific informational needs of EAE. In this work, we propose DEGAP, which addresses the above challenges through two simple yet effective components: (1) dual prefixes, where the instance-oriented prefix and template-oriented prefix are trained to learn information from different event instances and templates, respectively, and then provide relevant information as cues to EAE model without retrieval; (2) event-guided adaptive gating mechanism, which guides the prefixes based on the target event to fully leverage their advantages. Extensive experiments demonstrate that our method achieves new state-of-the-art performance on four datasets (ACE05, RAMS, WIKIEVENTS, and MLEE). Further analysis verifies the importance of the proposed design and the effectiveness of the main components.
EPI-SQL: Enhancing Text-to-SQL Translation with Error-Prevention Instructions
Apr 21, 2024



The conversion of natural language queries into SQL queries, known as Text-to-SQL, is a critical yet challenging task. This paper introduces EPI-SQL, a novel methodological framework leveraging Large Language Models (LLMs) to enhance the performance of Text-to-SQL tasks. EPI-SQL operates through a four-step process. Initially, the method involves gathering instances from the Spider dataset on which LLMs are prone to failure. These instances are then utilized to generate general error-prevention instructions (EPIs). Subsequently, LLMs craft contextualized EPIs tailored to the specific context of the current task. Finally, these context-specific EPIs are incorporated into the prompt used for SQL generation. EPI-SQL is distinguished in that it provides task-specific guidance, enabling the model to circumvent potential errors for the task at hand. Notably, the methodology rivals the performance of advanced few-shot methods despite being a zero-shot approach. An empirical assessment using the Spider benchmark reveals that EPI-SQL achieves an execution accuracy of 85.1\%, underscoring its effectiveness in generating accurate SQL queries through LLMs. The findings indicate a promising direction for future research, i.e. enhancing instructions with task-specific and contextualized rules, for boosting LLMs' performance in NLP tasks.
Token-Event-Role Structure-based Multi-Channel Document-Level Event Extraction
Jun 30, 2023



Document-level event extraction is a long-standing challenging information retrieval problem involving a sequence of sub-tasks: entity extraction, event type judgment, and event type-specific multi-event extraction. However, addressing the problem as multiple learning tasks leads to increased model complexity. Also, existing methods insufficiently utilize the correlation of entities crossing different events, resulting in limited event extraction performance. This paper introduces a novel framework for document-level event extraction, incorporating a new data structure called token-event-role and a multi-channel argument role prediction module. The proposed data structure enables our model to uncover the primary role of tokens in multiple events, facilitating a more comprehensive understanding of event relationships. By leveraging the multi-channel prediction module, we transform entity and multi-event extraction into a single task of predicting token-event pairs, thereby reducing the overall parameter size and enhancing model efficiency. The results demonstrate that our approach outperforms the state-of-the-art method by 9.5 percentage points in terms of the F1 score, highlighting its superior performance in event extraction. Furthermore, an ablation study confirms the significant value of the proposed data structure in improving event extraction tasks, further validating its importance in enhancing the overall performance of the framework.
Divide and Prompt: Chain of Thought Prompting for Text-to-SQL
Apr 23, 2023Chain-of-thought (CoT) prompting combined with large language models (LLMs) have achieved encouraging results on complex reasoning tasks. Text-to-SQL is a critical semantic parsing task that converts natural language questions into SQL statements, involving a complex reasoning process. However, there is little work about using CoT prompting to activate LLM's reasoning capabilities on Text-to-SQL tasks. In this work, we propose a new paradigm for prompting Text-to-SQL tasks, called Divide-and-Prompt, which first divides the task into subtasks, and then approach each subtask through CoT. We present 3 prompting-based methods to enhance the Text-to-SQL ability of LLMs. Experiments show that these prompts guide LLMs to generate Text-to-SQL with higher execution accuracy.