 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Pruning as Spectrum Preserving Process
Jul 18, 2023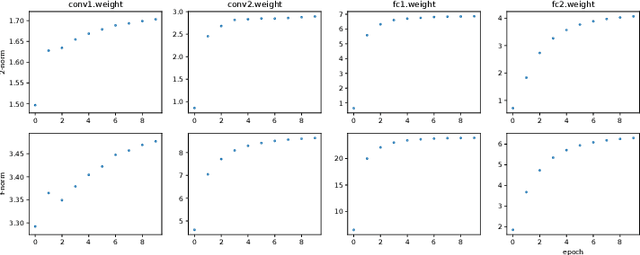
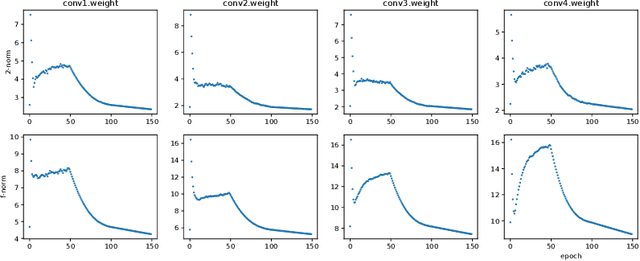
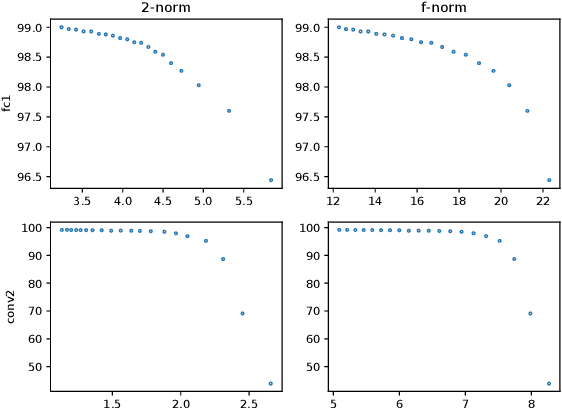
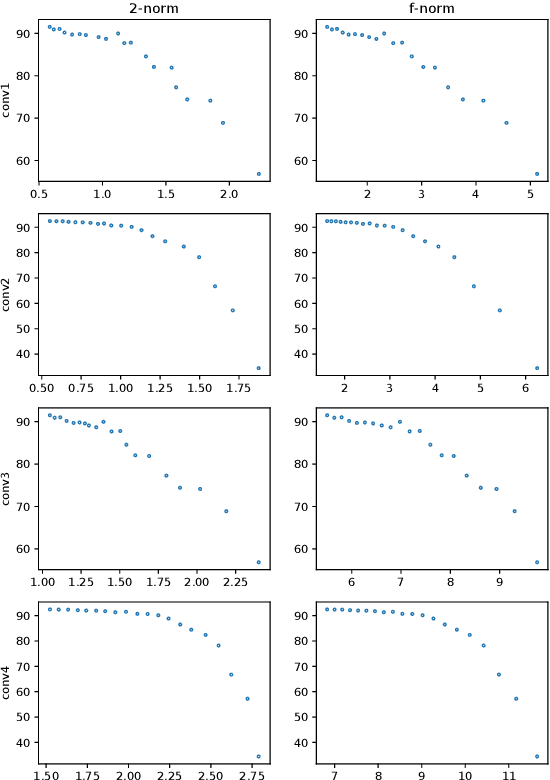
Neural networks have achieved remarkable performance in various application domains. Nevertheless, a large number of weights in pre-trained deep neural networks prohibit them from being deployed on smartphones and embedded systems. It is highly desirable to obtain lightweight versions of neural networks for inference in edge devices. Many cost-effective approaches were proposed to prune dense and convolutional layers that are common in deep neural networks and dominant in the parameter space. However, a unified theoretical foundation for the problem mostly is missing. In this paper, we identify the close connection between matrix spectrum learning and neural network training for dense and convolutional layers and argue that weight pruning is essentially a matrix sparsification process to preserve the spectrum. Based on the analysis, we also propose a matrix sparsification algorithm tailored for neural network pruning that yields better pruning result. We carefully design and conduct experiments to support our arguments. Hence we provide a consolidated viewpoint for neural network pruning and enhance the interpretability of deep neural networks by identifying and preserving the critical neural weights.
Graph Enabled Cross-Domain Knowledge Transfer
Apr 07, 2023To leverage machine learning in any decision-making process, one must convert the given knowledge (for example, natural language, unstructured text) into representation vectors that can be understood and processed by machine learning model in their compatible language and data format. The frequently encountered difficulty is, however, the given knowledge is not rich or reliable enough in the first place. In such cases, one seeks to fuse side information from a separate domain to mitigate the gap between good representation learning and the scarce knowledge in the domain of interest. This approach is named Cross-Domain Knowledge Transfer. It is crucial to study the problem because of the commonality of scarce knowledge in many scenarios, from online healthcare platform analyses to financial market risk quantification, leaving an obstacle in front of us benefiting from automated decision making. From the machine learning perspective, the paradigm of semi-supervised learning takes advantage of large amount of data without ground truth and achieves impressive learning performance improvement. It is adopted in this dissertation for cross-domain knowledge transfer. (to be continued)
Enhancing Domain Word Embedding via Latent Semantic Imputation
May 21, 2019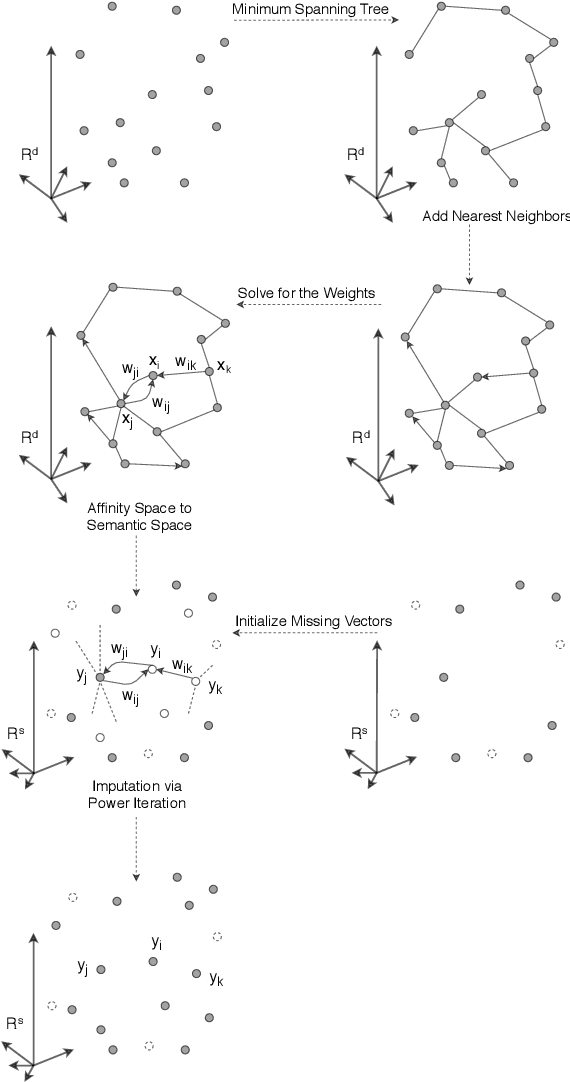
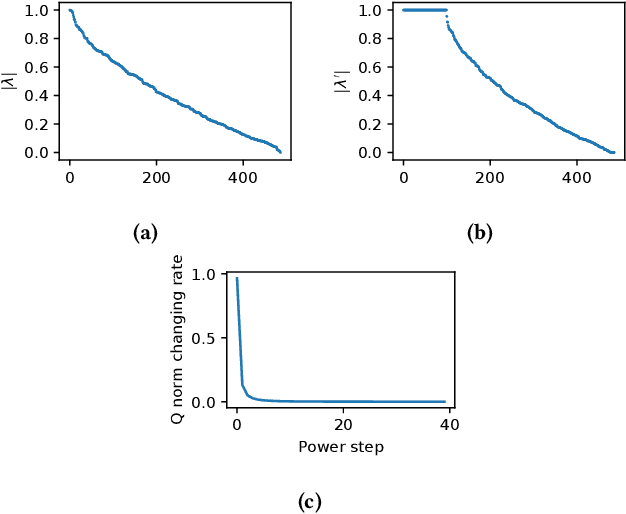
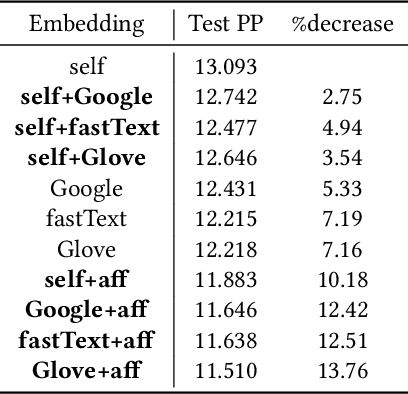
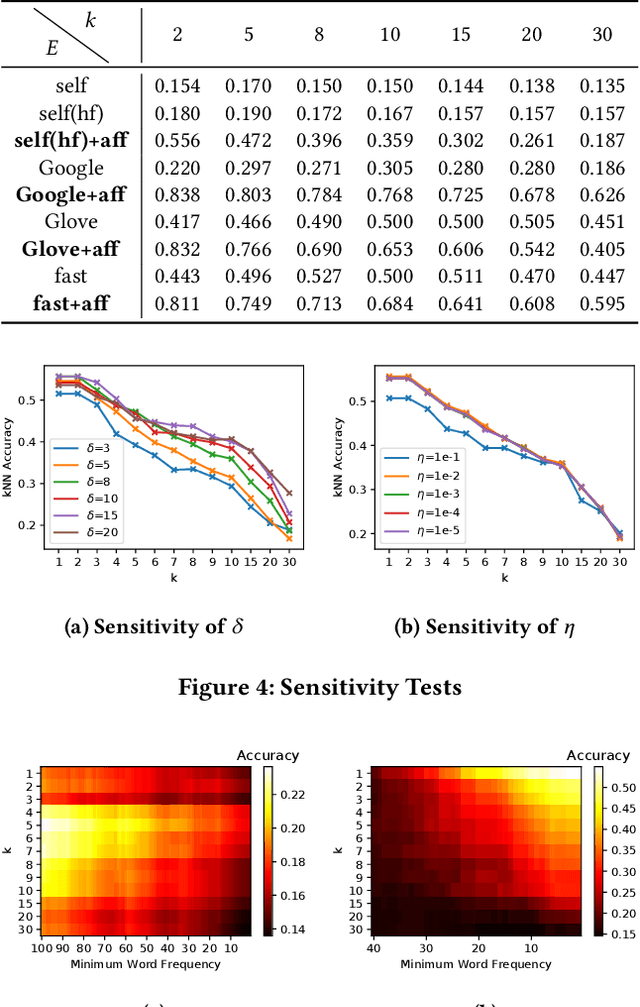
We present a novel method named Latent Semantic Imputation (LSI) to transfer external knowledge into semantic space for enhancing word embedding. The method integrates graph theory to extract the latent manifold structure of the entities in the affinity space and leverages non-negative least squares with standard simplex constraints and power iteration method to derive spectral embeddings. It provides an effective and efficient approach to combining entity representations defined in different Euclidean spaces. Specifically, our approach generates and imputes reliable embedding vectors for low-frequency words in the semantic space and benefits downstream language tasks that depend on word embedding. We conduct comprehensive experiments on a carefully designed classification problem and language modeling and demonstrate the superiority of the enhanced embedding via LSI over several well-known benchmark embeddings. We also confirm the consistency of the results under different parameter settings of our method.