 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Aggregating Stochastic Gradient Descent for Parallel Deep Learning
Paper and Code
Apr 07, 2020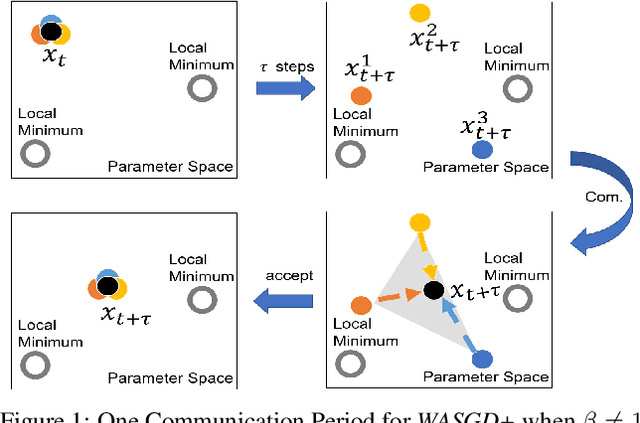

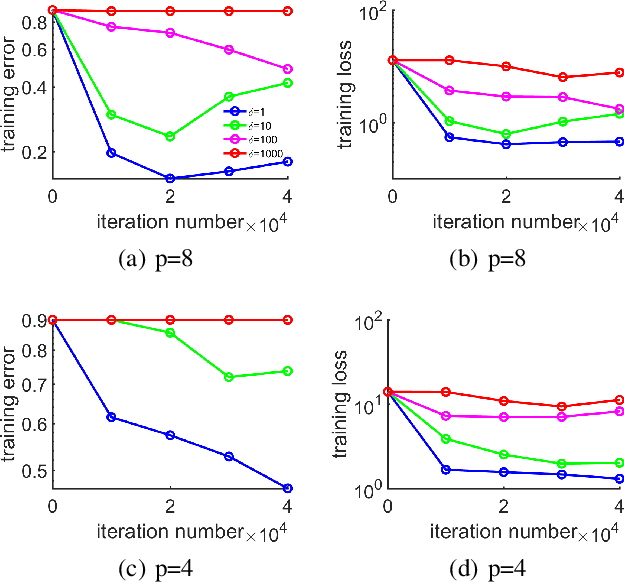

This paper investigates the stochastic optimization problem with a focus on developing scalable parallel algorithms for deep learning tasks. Our solution involves a reformation of the objective function for stochastic optimization in neural network models, along with a novel parallel strategy, coined weighted aggregating stochastic gradient descent (WASGD). Following a theoretical analysis on the characteristics of the new objective function, WASGD introduces a decentralized weighted aggregating scheme based on the performance of local workers. Without any center variable, the new method automatically assesses the importance of local workers and accepts them according to their contributions. Furthermore, we have developed an enhanced version of the method, WASGD+, by (1) considering a designed sample order and (2) applying a more advanced weight evaluating function. To validate the new method, we benchmark our schemes against several popular algorithms including the state-of-the-art techniques (e.g., elastic averaging SGD) in training deep neural networks for classification tasks. Comprehensive experiments have been conducted on four classic datasets, including the CIFAR-100, CIFAR-10, Fashion-MNIST, and MNIST. The subsequent results suggest the superiority of the WASGD scheme in accelerating the training of deep architecture. Better still, the enhanced version, WASGD+, has been shown to be a significant improvement over its basic version.