 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2IOSR: Maximal Mutual Information Open Set Recognition
Aug 06, 2021
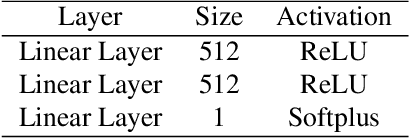
In this work, we aim to address the challenging task of open set recognition (OSR). Many recent OSR methods rely on auto-encoders to extract class-specific features by a reconstruction strategy, requiring the network to restore the input image on pixel-level. This strategy is commonly over-demanding for OSR since class-specific features are generally contained in target objects, not in all pixels. To address this shortcoming, here we discard the pixel-level reconstruction strategy and pay more attention to improving the effectiveness of class-specific feature extraction. We propose a mutual information-based method with a streamlined architecture, Maximal Mutual Information Open Set Recognition (M2IOSR). The proposed M2IOSR only uses an encoder to extract class-specific features by maximizing the mutual information between the given input and its latent features across multiple scales. Meanwhile, to further reduce the open space risk, latent features are constrained to class conditional Gaussian distributions by a KL-divergence loss function. In this way, a strong function is learned to prevent the network from mapping different observations to similar latent features and help the network extract class-specific features with desired statistical characteristics. The proposed method significantly improves the performance of baselines and achieves new state-of-the-art results on several benchmarks consistently.
Open Set Recognition with Conditional Probabilistic Generative Models
Aug 12, 2020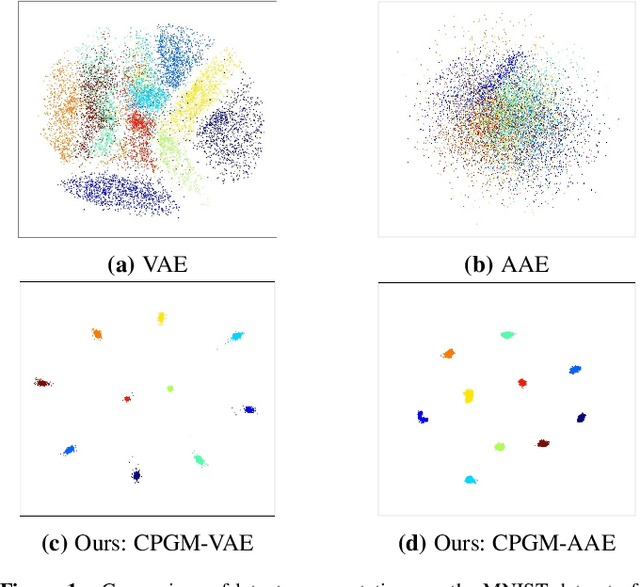
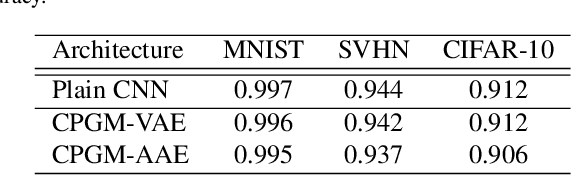
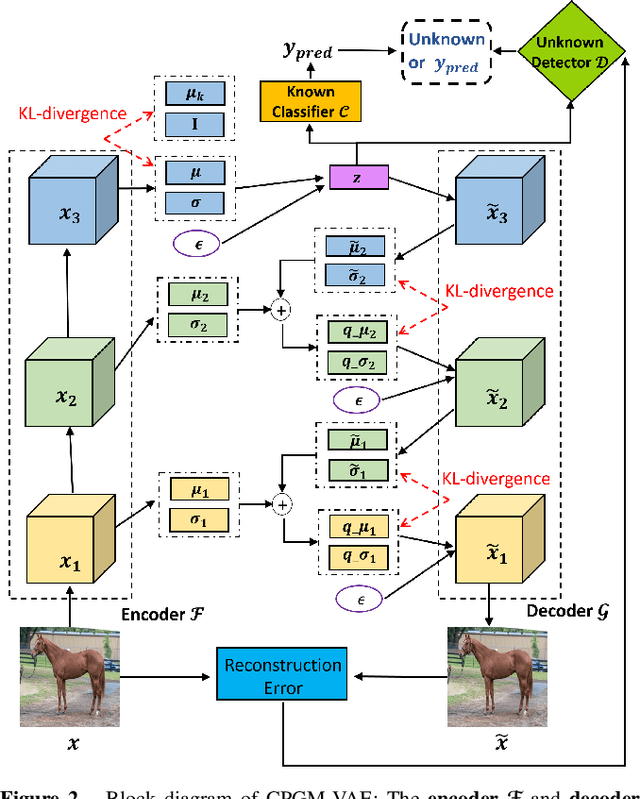
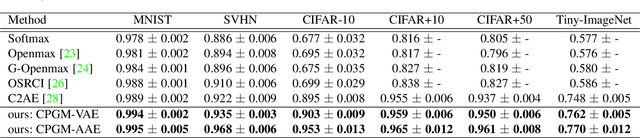
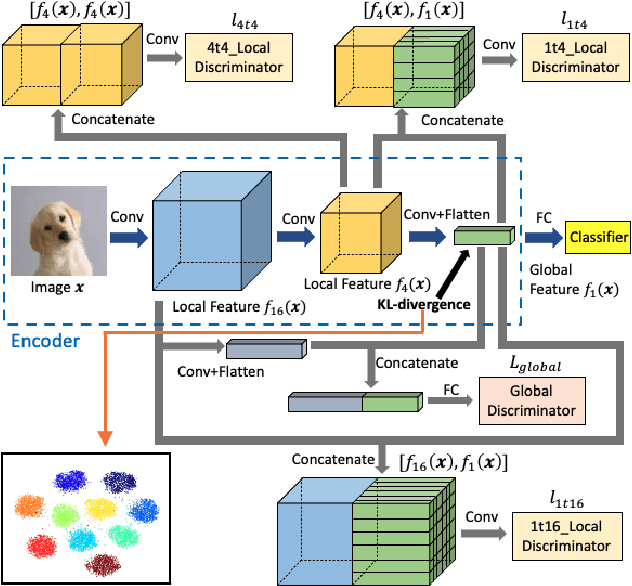
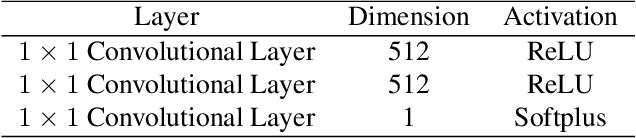
Deep neural networks have made breakthroughs in a wide range of visual understanding tasks. A typical challenge that hinders their real-world applications is that unknown samples may be fed into the system during the testing phase, but traditional deep neural networks will wrongly recognize these unknown samples as one of the known classes. Open set recognition (OSR) is a potential solution to overcome this problem, where the open set classifier should have the flexibility to reject unknown samples and meanwhile maintain high classification accuracy in known classes. Probabilistic generative models, such as Variational Autoencoders (VAE) and Adversarial Autoencoders (AAE), are popular methods to detect unknowns, but they cannot provide discriminative representations for known classification. In this paper, we propose a novel framework, called Conditional Probabilistic Generative Models (CPGM), for open set recognition. The core insight of our work is to add discriminative information into the probabilistic generative models, such that the proposed models can not only detect unknown samples but also classify known classes by forcing different latent features to approximate conditional Gaussian distributions. We discuss many model variants and provide comprehensive experiments to study their characteristics. Experiment results on multiple benchmark datasets reveal that the proposed method significantly outperforms the baselines and achieves new state-of-the-art performance.
Conditional Gaussian Distribution Learning for Open Set Recognition
Apr 17, 2020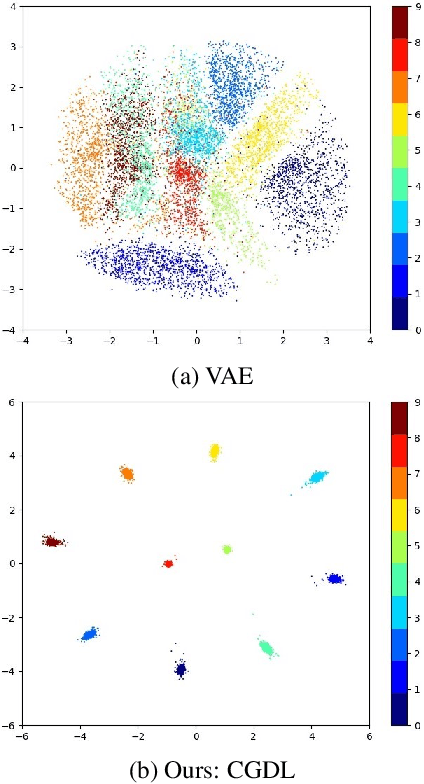
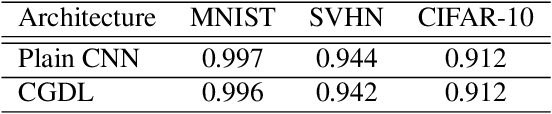
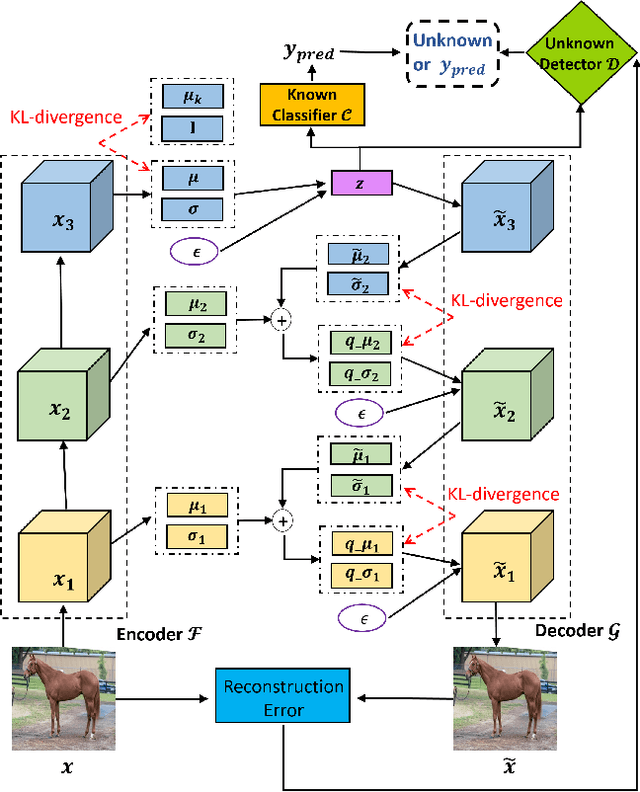

Deep neural networks have achieved state-of-the-art performance in a wide range of recognition/classification tasks. However, when applying deep learning to real-world applications, there are still multiple challenges. A typical challenge is that unknown samples may be fed into the system during the testing phase and traditional deep neural networks will wrongly recognize the unknown sample as one of the known classes. Open set recognition is a potential solution to overcome this problem, where the open set classifier should have the ability to reject unknown samples as well as maintain high classification accuracy on known classes. The variational auto-encoder (VAE) is a popular model to detect unknowns, but it cannot provide discriminative representations for known classification. In this paper, we propose a novel method, Conditional Gaussian Distribution Learning (CGDL), for open set recognition. In addition to detecting unknown samples, this method can also classify known samples by forcing different latent features to approximate different Gaussian models. Meanwhile, to avoid information hidden in the input vanishing in the middle layers, we also adopt the probabilistic ladder architecture to extract high-level abstract features. Experiments on several standard image datasets reveal that the proposed method significantly outperforms the baseline method and achieves new state-of-the-art results.