 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Lightweight Methods for Vehicle Dynamics-Based Driver Drowsiness Detection
Jun 08, 2025Driver drowsiness detection (DDD) prevents road accidents caused by driver fatigue. Vehicle dynamics-based DDD has been proposed as a method that is both economical and high performance. However, there are concerns about the reliability of performance metrics and the reproducibility of many of the existing methods. For instance, some previous studies seem to have a data leakage issue among training and test datasets, and many do not openly provide the datasets they used. To this end, this paper aims to compare the performance of representative vehicle dynamics-based DDD methods under a transparent and fair framework that uses a public dataset. We first develop a framework for extracting features from an open dataset by Aygun et al. and performing DDD with lightweight ML models; the framework is carefully designed to support a variety of onfigurations. Second, we implement three existing representative methods and a concise random forest (RF)-based method in the framework. Finally, we report the results of experiments to verify the reproducibility and clarify the performance of DDD based on common metrics. Among the evaluated methods, the RF-based method achieved the highest accuracy of 88 %. Our findings imply the issues inherent in DDD methods developed in a non-standard manner, and demonstrate a high performance method implemented appropriately.
Graph Energy-based Model for Substructure Preserving Molecular Design
Feb 09, 2021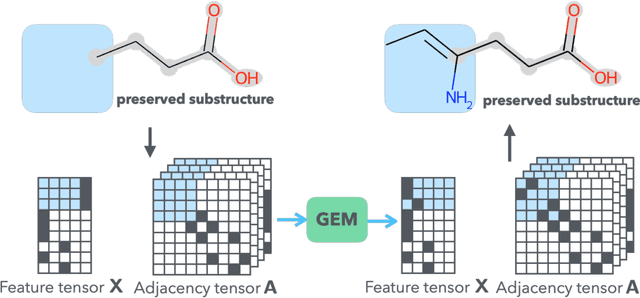
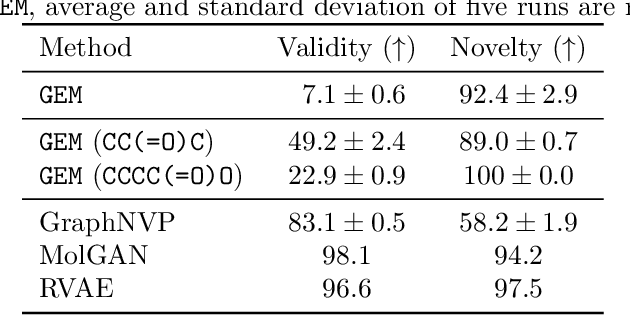
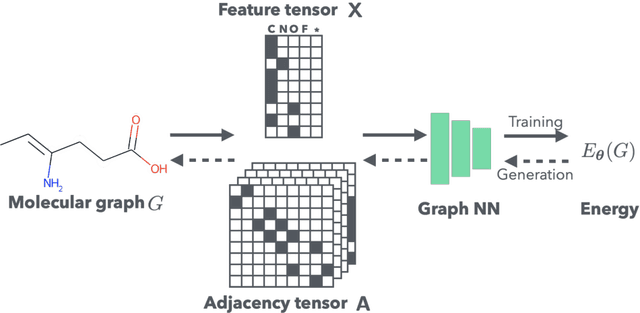
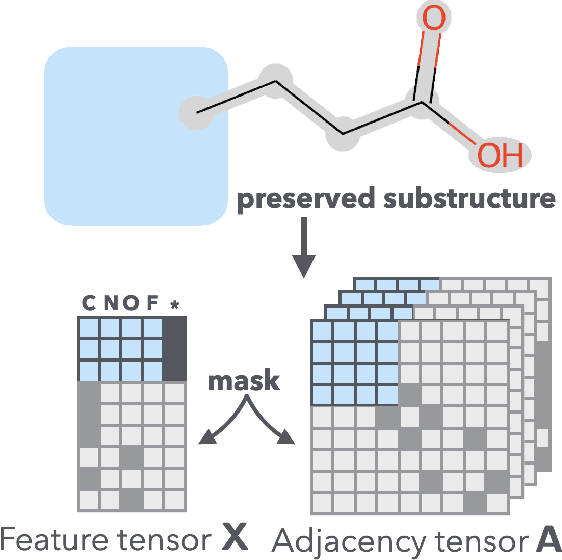
It is common practice for chemists to search chemical databases based on substructures of compounds for finding molecules with desired properties. The purpose of de novo molecular generation is to generate instead of search. Existing machine learning based molecular design methods have no or limited ability in generating novel molecules that preserves a target substructure. Our Graph Energy-based Model, or GEM, can fix substructures and generate the rest. The experimental results show that the GEMs trained from chemistry datasets successfully generate novel molecules while preserving the target substructures. This method would provide a new way of incorporating the domain knowledge of chemists in molecular design.
Practical Large-Scale Distributed Parallel Monte-Carlo Tree Search Applied to Molecular Design
Jun 18, 2020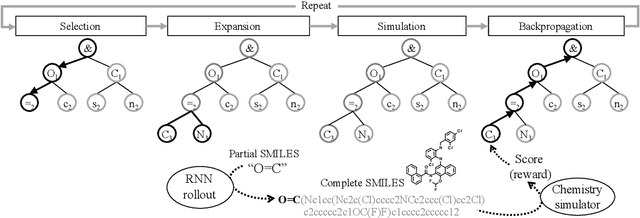

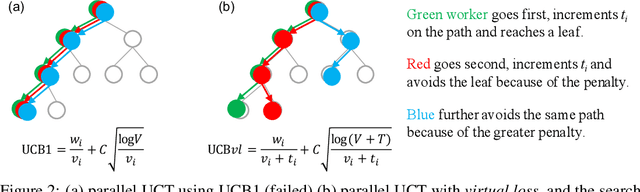
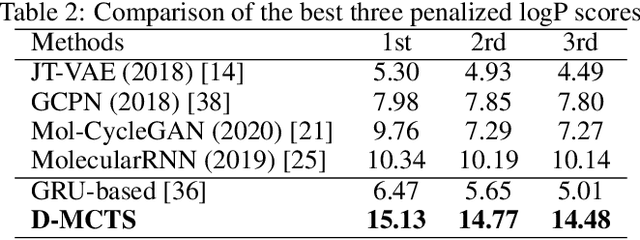
It is common practice to use large computational resources to train neural networks, as is known from many examples, such as reinforcement learning applications. However, while massively parallel computing is often used for training models, it is rarely used for searching solutions for combinatorial optimization problems. In this paper, we propose to apply a hash function based distributed parallel Monte-Carlo Tree Search (MCTS) to a real-world problem of molecular design. By running our massively parallel MCTS combined with a simple RNN on 1024 CPU cores for 10 minutes, we achieved a score on a molecular design problem that significantly outperforms existing work. Whereas existing studies on massively scalable parallel MCTS only compare the number of rollouts, we prove the practicality of the algorithm by comparing the quality of the solutions obtained in practice. This method is generic and is expected to speed up other applications of MCTS.
Meta Approach to Data Augmentation Optimization
Jun 14, 2020


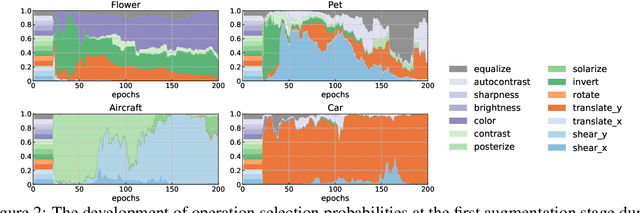
Data augmentation policies drastically improve the performance of image recognition tasks, especially when the policies are optimized for the target data and tasks. In this paper, we propose to optimize image recognition models and data augmentation policies simultaneously to improve the performance using gradient descent. Unlike prior methods, our approach avoids using proxy tasks or reducing search space, and can directly improve the validation performance. Our method achieves efficient and scalable training by approximating the gradient of policies by implicit gradient with Neumann series approximation. We demonstrate that our approach can improve the performance of various image classification tasks, including ImageNet classification and fine-grained recognition, without using dataset-specific hyperparameter tuning.
Faster AutoAugment: Learning Augmentation Strategies using Backpropagation
Nov 16, 2019
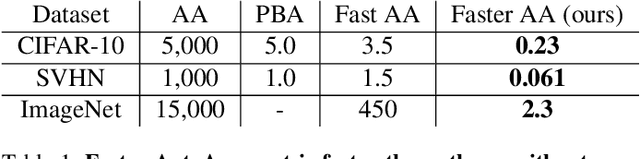

Data augmentation methods are indispensable heuristics to boost the performance of deep neural networks, especially in image recognition tasks. Recently, several studies have shown that augmentation strategies found by search algorithms outperform hand-made strategies. Such methods employ black-box search algorithms over image transformations with continuous or discrete parameters and require a long time to obtain better strategies. In this paper, we propose a differentiable policy search pipeline for data augmentation, which is much faster than previous methods. We introduce approximate gradients for several transformation operations with discrete parameters as well as the differentiable mechanism for selecting operations. As the objective of training, we minimize the distance between the distributions of augmented data and the original data, which can be differentiated. We show that our method, Faster AutoAugment, achieves significantly faster searching than prior work without a performance drop.
Redesigning pattern mining algorithms for supercomputers
Oct 27, 2015
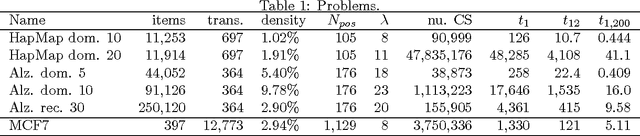
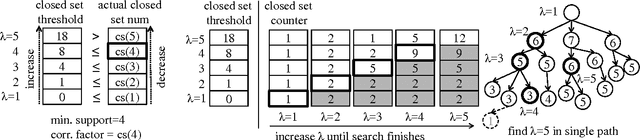
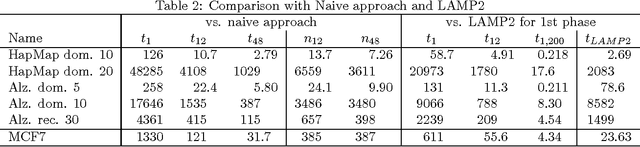
Upcoming many core processors are expected to employ a distributed memory architecture similar to currently available supercomputers, but parallel pattern mining algorithms amenable to the architecture are not comprehensively studied. We present a novel closed pattern mining algorithm with a well-engineered communication protocol, and generalize it to find statistically significant patterns from personal genome data. For distributing communication evenly, it employs global load balancing with multiple stacks distributed on a set of cores organized as a hypercube with random edges. Our algorithm achieved up to 1175-fold speedup by using 1200 cores for solving a problem with 11,914 items and 697 transactions, while the naive approach of separating the search space failed completely.
Scalable Parallel Numerical Constraint Solver Using Global Load Balancing
May 18, 2015We present a scalable parallel solver for numerical constraint satisfaction problems (NCSPs). Our parallelization scheme consists of homogeneous worker solvers, each of which runs on an available core and communicates with others via the global load balancing (GLB) method. The parallel solver is implemented with X10 that provides an implementation of GLB as a library. In experiments, several NCSPs from the literature were solved and attained up to 516-fold speedup using 600 cores of the TSUBAME2.5 supercomputer.
Scalable Parallel Numerical CSP Solver
Nov 06, 2014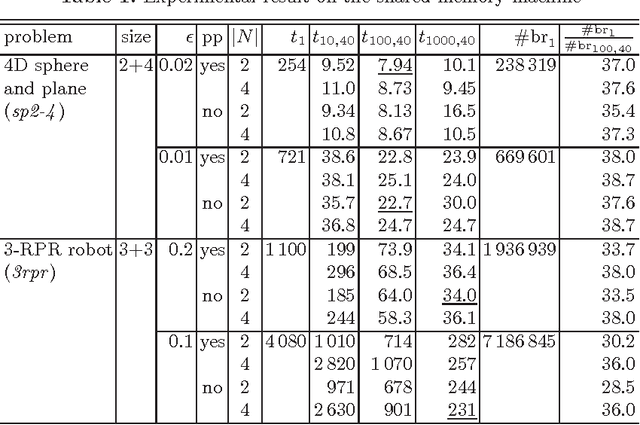
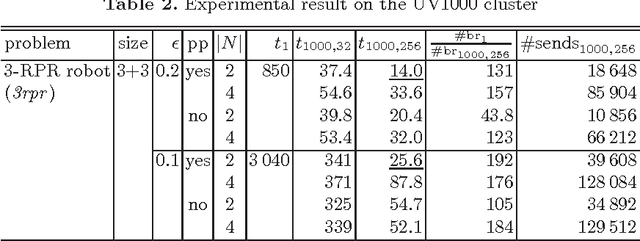
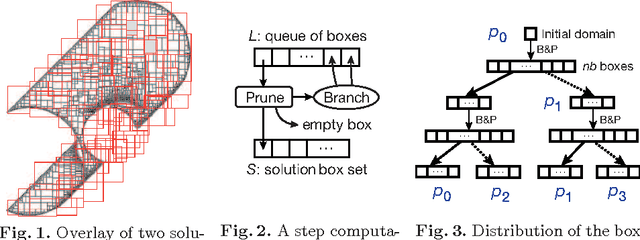
We present a parallel solver for numerical constraint satisfaction problems (NCSPs) that can scale on a number of cores. Our proposed method runs worker solvers on the available cores and simultaneously the workers cooperate for the search space distribution and balancing. In the experiments, we attained up to 119-fold speedup using 256 cores of a parallel computer.