 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Friction Models and LuGre Identification via Physics Informed Neural Networks
Apr 16, 2025Accurately modeling friction in robotics remains a core challenge, as robotics simulators like Mujoco and PyBullet use simplified friction models or heuristics to balance computational efficiency with accuracy, where these simplifications and approximations can lead to substantial differences between simulated and physical performance. In this paper, we present a physics-informed friction estimation framework that enables the integration of well-established friction models with learnable components-requiring only minimal, generic measurement data. Our approach enforces physical consistency yet retains the flexibility to adapt to real-world complexities. We demonstrate, on an underactuated and nonlinear system, that the learned friction models, trained solely on small and noisy datasets, accurately simulate dynamic friction properties and reduce the sim-to-real gap. Crucially, we show that our approach enables the learned models to be transferable to systems they are not trained on. This ability to generalize across multiple systems streamlines friction modeling for complex, underactuated tasks, offering a scalable and interpretable path toward bridging the sim-to-real gap in robotics and control.
Leveraging Reward Gradients For Reinforcement Learning in Differentiable Physics Simulations
Mar 06, 2022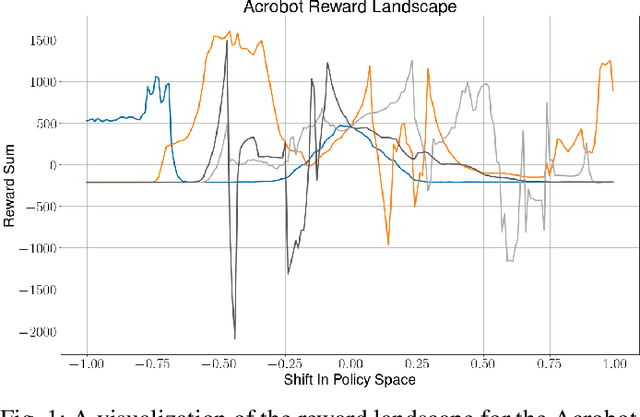
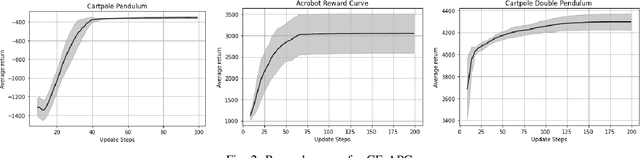
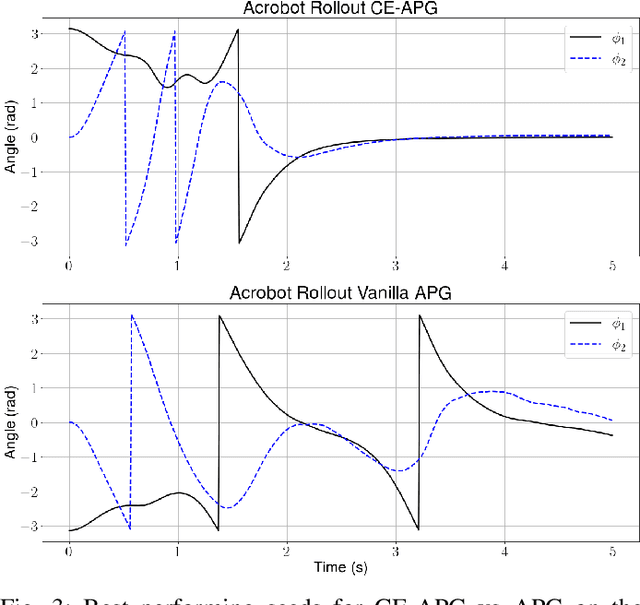
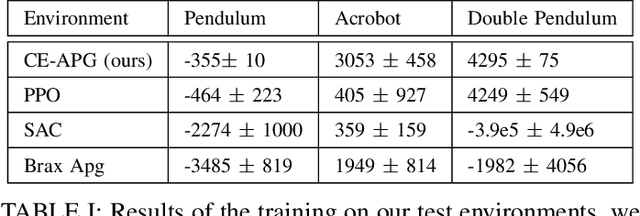
In recent years, fully differentiable rigid body physics simulators have been developed, which can be used to simulate a wide range of robotic systems. In the context of reinforcement learning for control, these simulators theoretically allow algorithms to be applied directly to analytic gradients of the reward function. However, to date, these gradients have proved extremely challenging to use, and are outclassed by algorithms using no gradient information at all. In this work we present a novel algorithm, cross entropy analytic policy gradients, that is able to leverage these gradients to outperform state of art deep reinforcement learning on a set of challenging nonlinear control problems.
Direct Random Search for Fine Tuning of Deep Reinforcement Learning Policies
Sep 12, 2021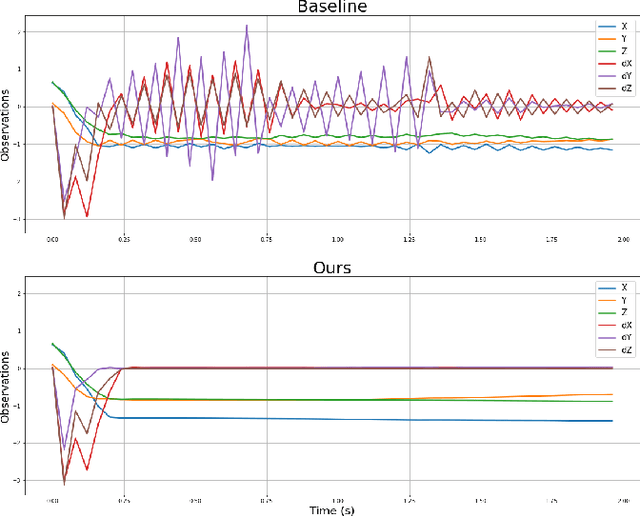
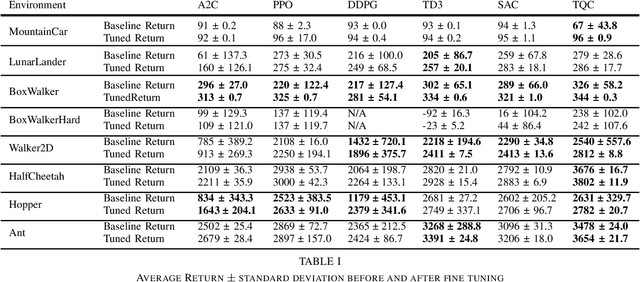
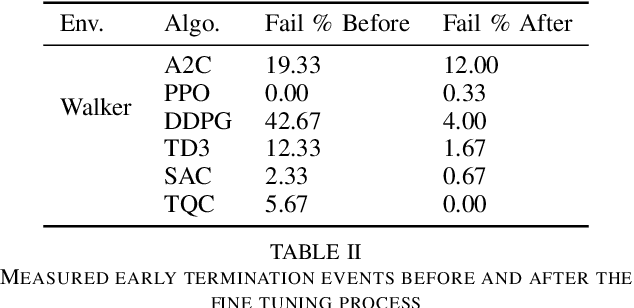
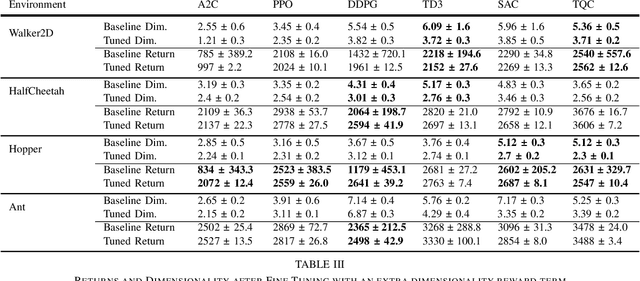
Researchers have demonstrated that Deep Reinforcement Learning (DRL) is a powerful tool for finding policies that perform well on complex robotic systems. However, these policies are often unpredictable and can induce highly variable behavior when evaluated with only slightly different initial conditions. Training considerations constrain DRL algorithm designs in that most algorithms must use stochastic policies during training. The resulting policy used during deployment, however, can and frequently is a deterministic one that uses the Maximum Likelihood Action (MLA) at each step. In this work, we show that a direct random search is very effective at fine-tuning DRL policies by directly optimizing them using deterministic rollouts. We illustrate this across a large collection of reinforcement learning environments, using a wide variety of policies obtained from different algorithms. Our results show that this method yields more consistent and higher performing agents on the environments we tested. Furthermore, we demonstrate how this method can be used to extend our previous work on shrinking the dimensionality of the reachable state space of closed-loop systems run under Deep Neural Network (DNN) policies.
Mesh Based Analysis of Low Fractal Dimension ReinforcementLearning Policies
Dec 24, 2020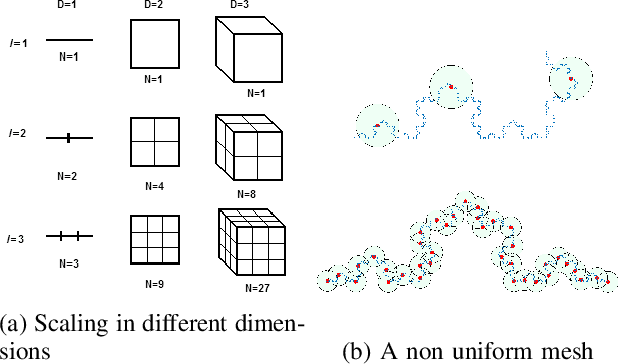

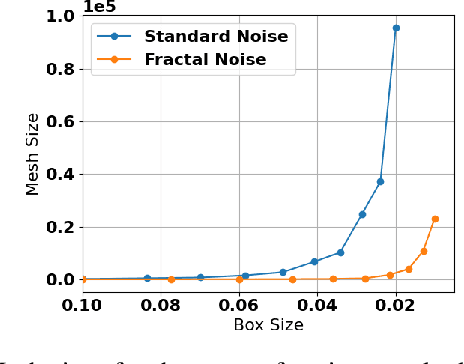
In previous work, using a process we call meshing, the reachable state spaces for various continuous and hybrid systems were approximated as a discrete set of states which can then be synthesized into a Markov chain. One of the applications for this approach has been to analyze locomotion policies obtained by reinforcement learning, in a step towards making empirical guarantees about the stability properties of the resulting system. In a separate line of research, we introduced a modified reward function for on-policy reinforcement learning algorithms that utilizes a "fractal dimension" of rollout trajectories. This reward was shown to encourage policies that induce individual trajectories which can be more compactly represented as a discrete mesh. In this work we combine these two threads of research by building meshes of the reachable state space of a system subject to disturbances and controlled by policies obtained with the modified reward. Our analysis shows that the modified policies do produce much smaller reachable meshes. This shows that agents trained with the fractal dimension reward transfer their desirable quality of having a more compact state space to a setting with external disturbances. The results also suggest that the previous work using mesh based tools to analyze RL policies may be extended to higher dimensional systems or to higher resolution meshes than would have otherwise been possible.
Combining Deep Reinforcement Learning And Local Control For The Acrobot Swing-up And Balance Task
Dec 21, 2020



In this work we present a novel extension of soft actor critic, a state of the art deep reinforcement algorithm. Our method allows us to combine traditional controllers with learned neural network policies. This combination allows us to leverage both our own domain knowledge and some of the advantages of model free reinforcement learning. We demonstrate our algorithm by combining a hand designed linear quadratic regulator with a learned controller for the acrobot problem. We show that our technique outperforms other state of the art reinforcement learning algorithms in this setting.
Explicitly Encouraging Low Fractional Dimensional Trajectories Via Reinforcement Learning
Dec 21, 2020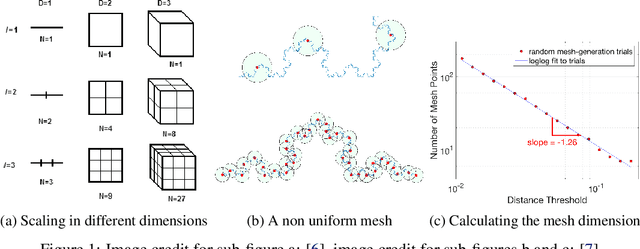
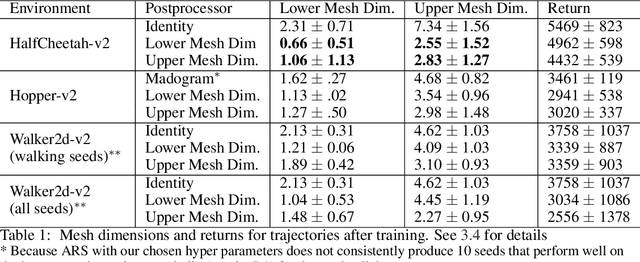
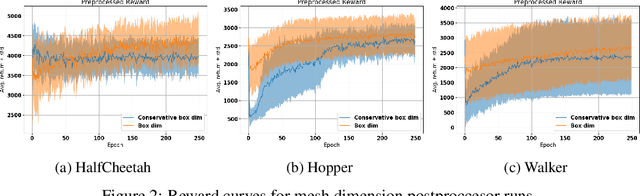
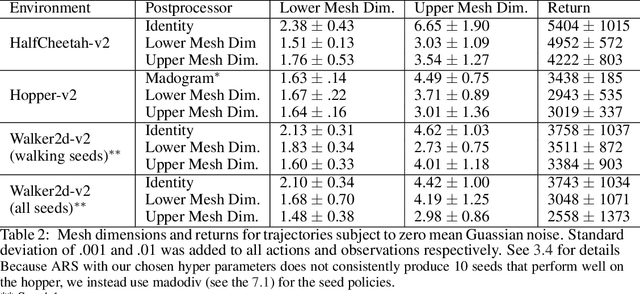
A key limitation in using various modern methods of machine learning in developing feedback control policies is the lack of appropriate methodologies to analyze their long-term dynamics, in terms of making any sort of guarantees (even statistically) about robustness. The central reasons for this are largely due to the so-called curse of dimensionality, combined with the black-box nature of the resulting control policies themselves. This paper aims at the first of these issues. Although the full state space of a system may be quite large in dimensionality, it is a common feature of most model-based control methods that the resulting closed-loop systems demonstrate dominant dynamics that are rapidly driven to some lower-dimensional sub-space within. In this work we argue that the dimensionality of this subspace is captured by tools from fractal geometry, namely various notions of a fractional dimension. We then show that the dimensionality of trajectories induced by model free reinforcement learning agents can be influenced adding a post processing function to the agents reward signal. We verify that the dimensionality reduction is robust to noise being added to the system and show that that the modified agents are more actually more robust to noise and push disturbances in general for the systems we examined.
Combining Benefits from Trajectory Optimization and Deep Reinforcement Learning
Oct 21, 2019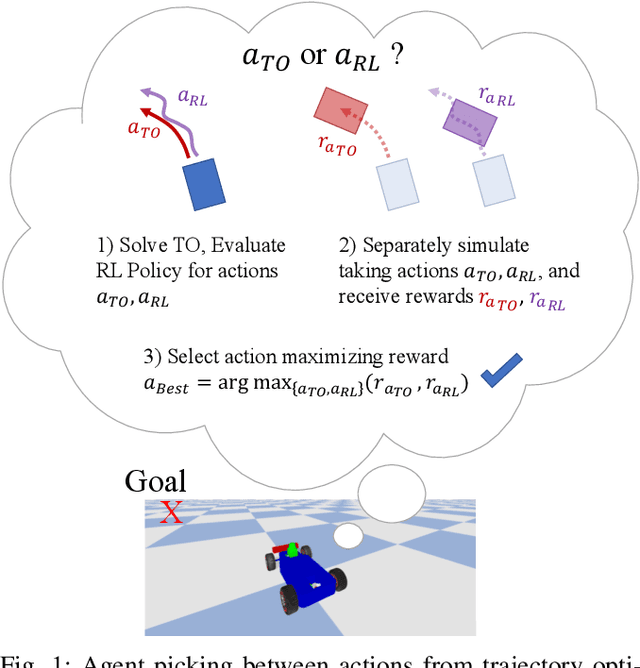
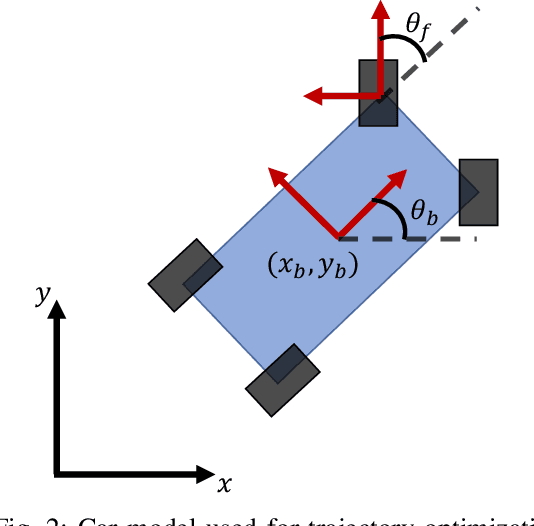
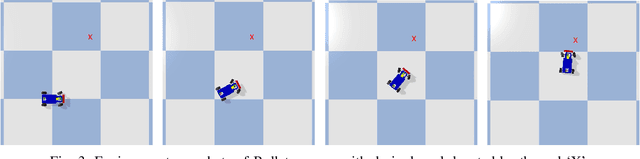
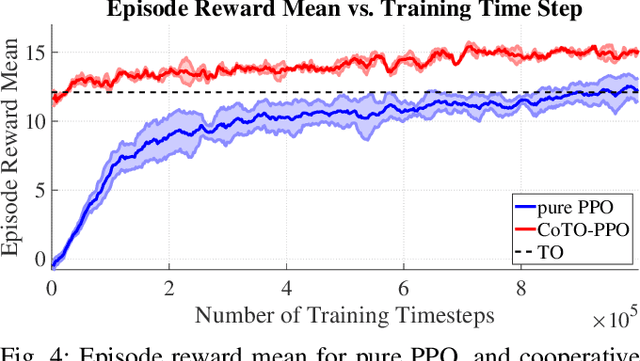
Recent breakthroughs both in reinforcement learning and trajectory optimization have made significant advances towards real world robotic system deployment. Reinforcement learning (RL) can be applied to many problems without needing any modeling or intuition about the system, at the cost of high sample complexity and the inability to prove any metrics about the learned policies. Trajectory optimization (TO) on the other hand allows for stability and robustness analyses on generated motions and trajectories, but is only as good as the often over-simplified derived model, and may have prohibitively expensive computation times for real-time control. This paper seeks to combine the benefits from these two areas while mitigating their drawbacks by (1) decreasing RL sample complexity by using existing knowledge of the problem with optimal control, and (2) providing an upper bound estimate on the time-to-arrival of the combined learned-optimized policy, allowing online policy deployment at any point in the training process by using the TO as a worst-case scenario action. This method is evaluated for a car model, with applicability to any mobile robotic system. A video showing policy execution comparisons can be found at https://youtu.be/mv2xw83NyWU .
Mesh-based Tools to Analyze Deep Reinforcement Learning Policies for Underactuated Biped Locomotion
Mar 29, 2019

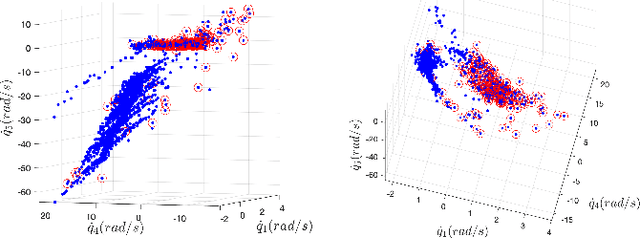

In this paper, we present a mesh-based approach to analyze stability and robustness of the policies obtained via deep reinforcement learning for various biped gaits of a five-link planar model. Intuitively, one would expect that including perturbations and/or other types of noise during training would likely result in more robustness of the resulting control policy. However, one would like to have a quantitative and computationally-efficient means of evaluating the degree to which this might be so. Rather than relying on Monte Carlo simulations, our goal is to provide more sophisticated tools to assess robustness properties of such policies. Our work is motivated by the twin hypotheses that contraction of dynamics, when achievable, can simplify control and that control policies obtained via deep learning may therefore exhibit tendency to contract to lower-dimensional manifolds within the full state space, as a result. The tractability of our mesh-based tools in this work provides some evidence that this may be so.
Training in Task Space to Speed Up and Guide Reinforcement Learning
Mar 06, 2019

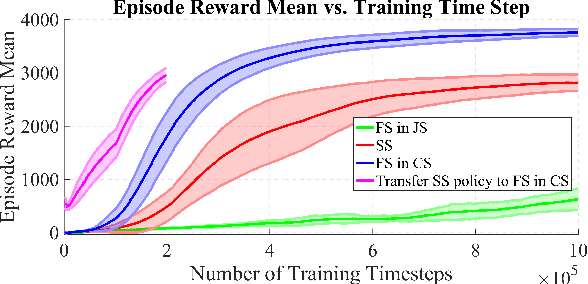
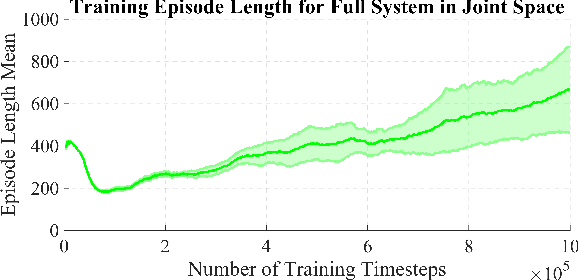
Recent breakthroughs in the reinforcement learning (RL) community have made significant advances towards learning and deploying policies on real world robotic systems. However, even with the current state-of-the-art algorithms and computational resources, these algorithms are still plagued with high sample complexity, and thus long training times, especially for high degree of freedom (DOF) systems. There are also concerns arising from lack of perceived stability or robustness guarantees from emerging policies. This paper aims at mitigating these drawbacks by: (1) modeling a complex, high DOF system with a representative simple one, (2) making explicit use of forward and inverse kinematics without forcing the RL algorithm to "learn" them on its own, and (3) learning locomotion policies in Cartesian space instead of joint space. In this paper these methods are applied to JPL's Robosimian, but can be readily used on any system with a base and end effector(s). These locomotion policies can be produced in just a few minutes, trained on a single laptop. We compare the robustness of the resulting learned policies to those of other control methods. An accompanying video for this paper can be found at https://youtu.be/xDxxSw5ahnc .
Toward Efficient and Robust Biped Walking Optimization
Jul 26, 2018Practical bipedal robot locomotion needs to be both energy efficient and robust to variability and uncertainty. In this paper, we build upon recent works in trajectory optimization for robot locomotion with two primary goals. First, we wish to demonstrate the importance of (a) considering and quantifying not only energy efficiency but also robustness of gaits, and (b) optimization not only of nominal motion trajectories but also of robot design parameters and feedback control policies. As a second, complementary focus, we present results from optimization studies on a 5-link planar walking model, to provide preliminary data on particular trade-offs and general trends in improving efficiency versus robustness. In addressing important, open challenges, we focus in particular on discussions of the effects of choices made (a) in formulating what is always, necessarily only an approximate optimization, in choosing metrics for performance, and (b) in structuring and tuning feedback control.