 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Friction Models and LuGre Identification via Physics Informed Neural Networks
Apr 16, 2025Accurately modeling friction in robotics remains a core challenge, as robotics simulators like Mujoco and PyBullet use simplified friction models or heuristics to balance computational efficiency with accuracy, where these simplifications and approximations can lead to substantial differences between simulated and physical performance. In this paper, we present a physics-informed friction estimation framework that enables the integration of well-established friction models with learnable components-requiring only minimal, generic measurement data. Our approach enforces physical consistency yet retains the flexibility to adapt to real-world complexities. We demonstrate, on an underactuated and nonlinear system, that the learned friction models, trained solely on small and noisy datasets, accurately simulate dynamic friction properties and reduce the sim-to-real gap. Crucially, we show that our approach enables the learned models to be transferable to systems they are not trained on. This ability to generalize across multiple systems streamlines friction modeling for complex, underactuated tasks, offering a scalable and interpretable path toward bridging the sim-to-real gap in robotics and control.
Direct Random Search for Fine Tuning of Deep Reinforcement Learning Policies
Sep 12, 2021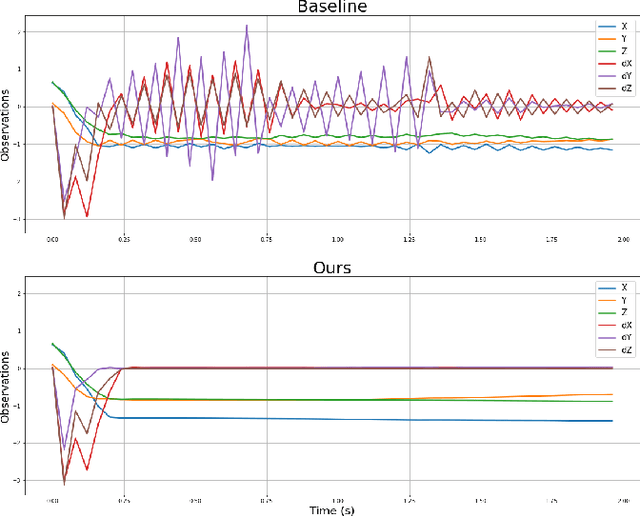
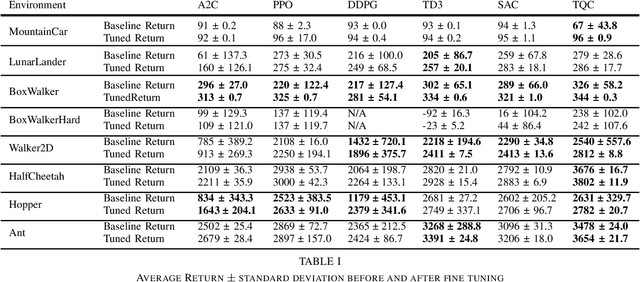
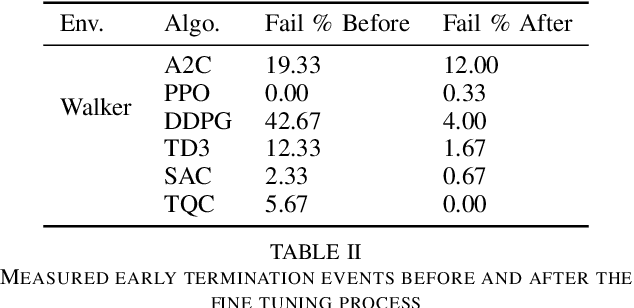
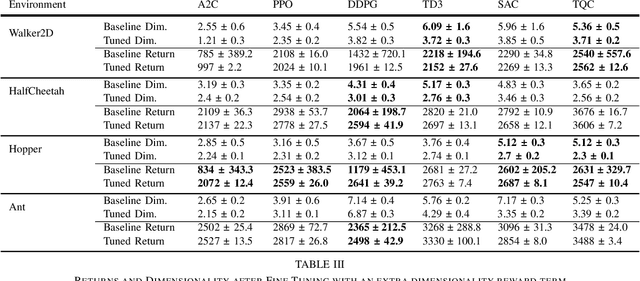
Researchers have demonstrated that Deep Reinforcement Learning (DRL) is a powerful tool for finding policies that perform well on complex robotic systems. However, these policies are often unpredictable and can induce highly variable behavior when evaluated with only slightly different initial conditions. Training considerations constrain DRL algorithm designs in that most algorithms must use stochastic policies during training. The resulting policy used during deployment, however, can and frequently is a deterministic one that uses the Maximum Likelihood Action (MLA) at each step. In this work, we show that a direct random search is very effective at fine-tuning DRL policies by directly optimizing them using deterministic rollouts. We illustrate this across a large collection of reinforcement learning environments, using a wide variety of policies obtained from different algorithms. Our results show that this method yields more consistent and higher performing agents on the environments we tested. Furthermore, we demonstrate how this method can be used to extend our previous work on shrinking the dimensionality of the reachable state space of closed-loop systems run under Deep Neural Network (DNN) policies.