 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXED: A Multilingual Dataset for Sentiment Analysis and Emotion Detection
Nov 06, 2020
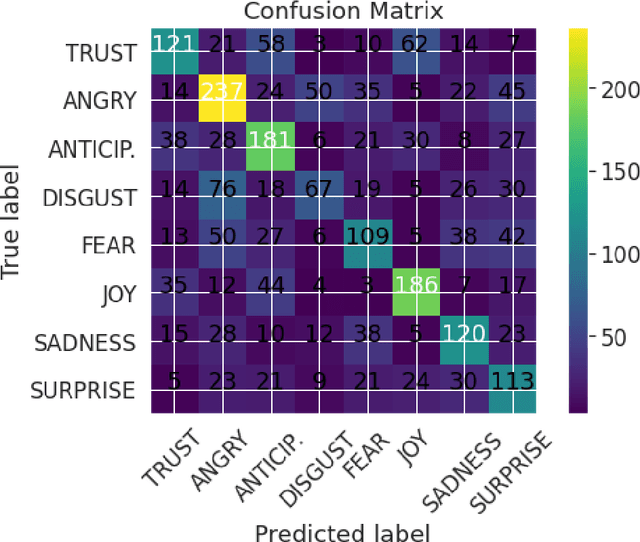
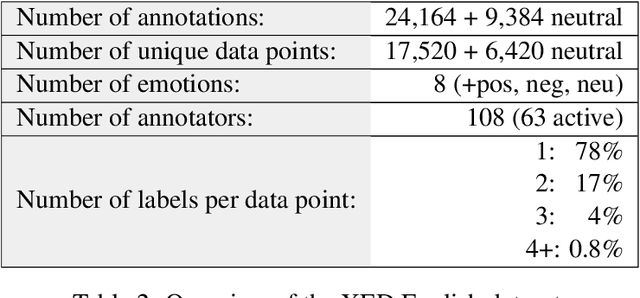
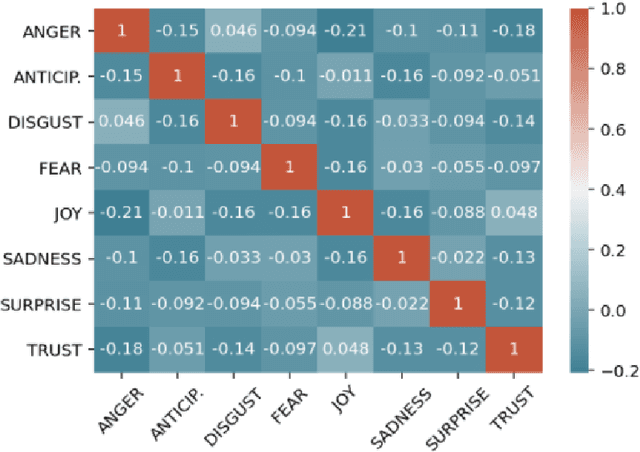
We introduce XED, a multilingual fine-grained emotion dataset. The dataset consists of human-annotated Finnish (25k) and English sentences (30k), as well as projected annotations for 30 additional languages, providing new resources for many low-resource languages. We use Plutchik's core emotions to annotate the dataset with the addition of neutral to create a multilabel multiclass dataset. The dataset is carefully evaluated using language-specific BERT models and SVMs to show that XED performs on par with other similar datasets and is therefore a useful tool for sentiment analysis and emotion detection.
LT@Helsinki at SemEval-2020 Task 12: Multilingual or language-specific BERT?
Aug 03, 2020
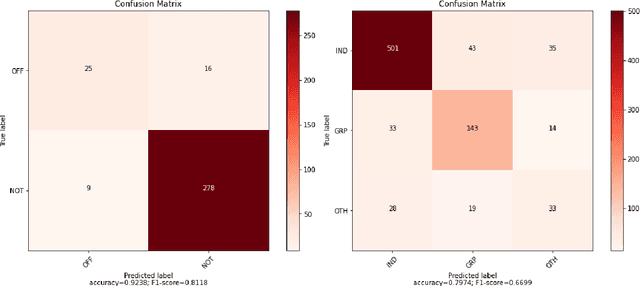
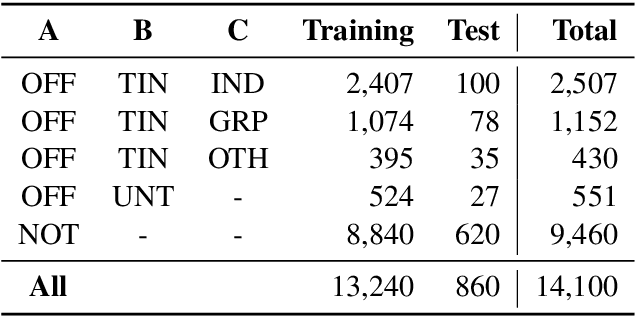

This paper presents the different models submitted by the LT@Helsinki team for the SemEval 2020 Shared Task 12. Our team participated in sub-tasks A and C; titled offensive language identification and offense target identification, respectively. In both cases we used the so-called Bidirectional Encoder Representation from Transformer (BERT), a model pre-trained by Google and fine-tuned by us on the OLID and SOLID datasets. The results show that offensive tweet classification is one of several language-based tasks where BERT can achieve state-of-the-art results.