Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLT@Helsinki at SemEval-2020 Task 12: Multilingual or language-specific BERT?
Paper and Code
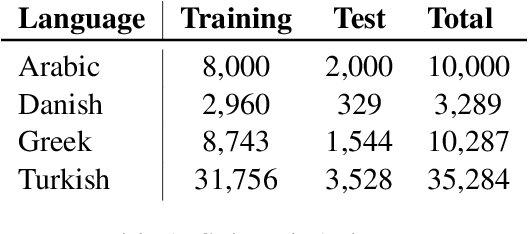
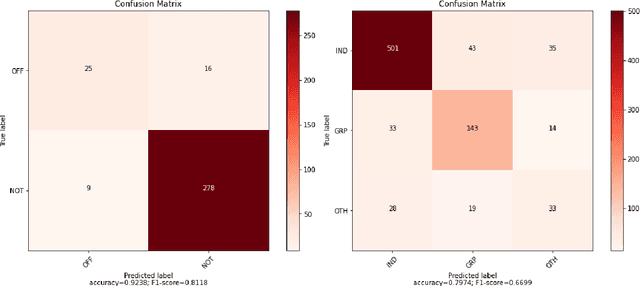
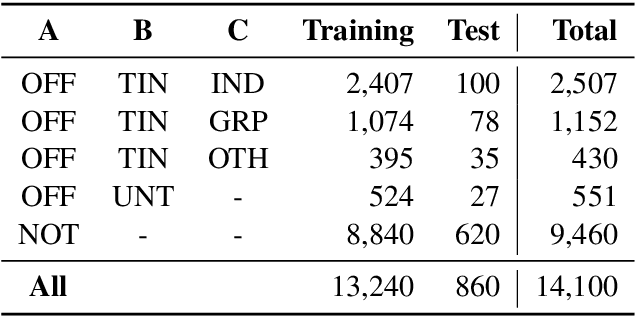

This paper presents the different models submitted by the LT@Helsinki team for the SemEval 2020 Shared Task 12. Our team participated in sub-tasks A and C; titled offensive language identification and offense target identification, respectively. In both cases we used the so-called Bidirectional Encoder Representation from Transformer (BERT), a model pre-trained by Google and fine-tuned by us on the OLID and SOLID datasets. The results show that offensive tweet classification is one of several language-based tasks where BERT can achieve state-of-the-art results.
* Accepted at SemEval-2020 Task 12. Identical to camera-ready version
except where adjustments to fit arXiv requirements were necessary
View paper on