Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXED: A Multilingual Dataset for Sentiment Analysis and Emotion Detection
Paper and Code
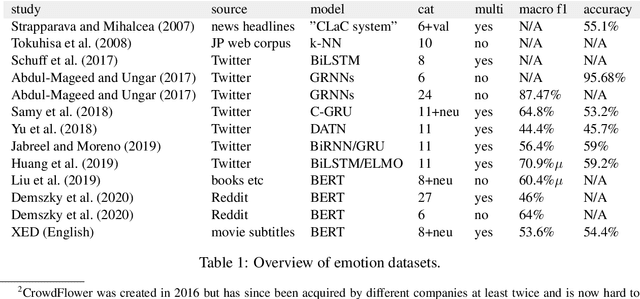
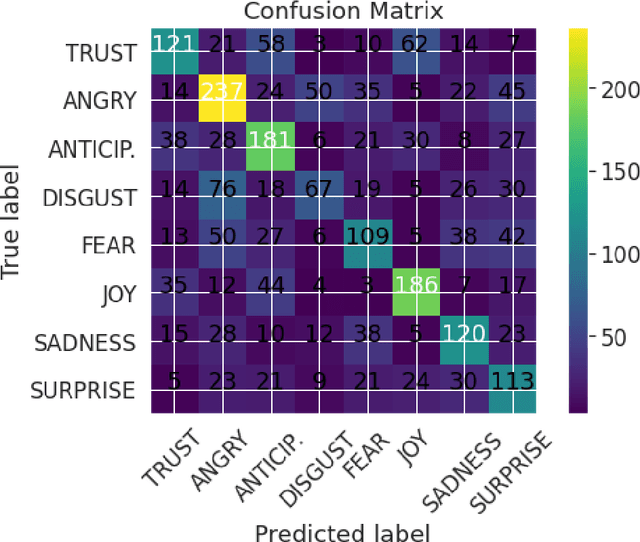
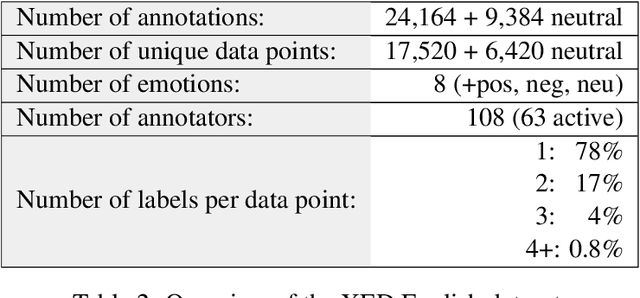
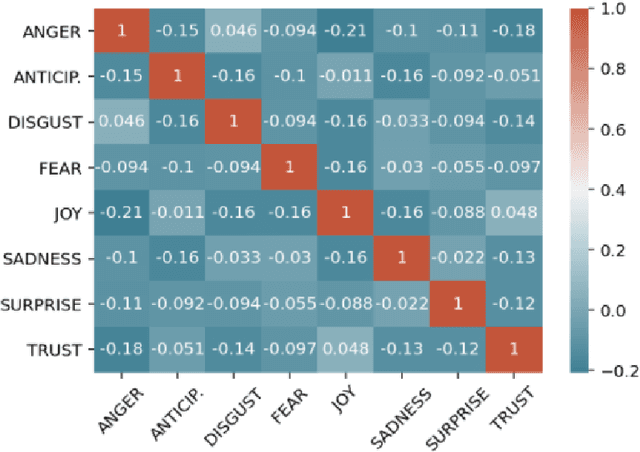
We introduce XED, a multilingual fine-grained emotion dataset. The dataset consists of human-annotated Finnish (25k) and English sentences (30k), as well as projected annotations for 30 additional languages, providing new resources for many low-resource languages. We use Plutchik's core emotions to annotate the dataset with the addition of neutral to create a multilabel multiclass dataset. The dataset is carefully evaluated using language-specific BERT models and SVMs to show that XED performs on par with other similar datasets and is therefore a useful tool for sentiment analysis and emotion detection.
* Accepted at COLING 2020
View paper on