 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerational Replacement and Learning for High-Performing and Diverse Populations in Evolvable Robots
Jan 07, 2026Evolutionary Robotics offers the possibility to design robots to solve a specific task automatically by optimizing their morphology and control together. However, this co-optimization of body and control is challenging, because controllers need some time to adapt to the evolving morphology - which may make it difficult for new and promising designs to enter the evolving population. A solution to this is to add intra-life learning, defined as an additional controller optimization loop, to each individual in the evolving population. A related problem is the lack of diversity often seen in evolving populations as evolution narrows the search down to a few promising designs too quickly. This problem can be mitigated by implementing full generational replacement, where offspring robots replace the whole population. This solution for increasing diversity usually comes at the cost of lower performance compared to using elitism. In this work, we show that combining such generational replacement with intra-life learning can increase diversity while retaining performance. We also highlight the importance of performance metrics when studying learning in morphologically evolving robots, showing that evaluating according to function evaluations versus according to generations of evolution can give different conclusions.
Integrating Sample Inheritance into Bayesian Optimization for Evolutionary Robotics
Jan 07, 2026In evolutionary robotics, robot morphologies are designed automatically using evolutionary algorithms. This creates a body-brain optimization problem, where both morphology and control must be optimized together. A common approach is to include controller optimization for each morphology, but starting from scratch for every new body may require a high controller learning budget. We address this by using Bayesian optimization for controller optimization, exploiting its sample efficiency and strong exploration capabilities, and using sample inheritance as a form of Lamarckian inheritance. Under a deliberately low controller learning budget for each morphology, we investigate two types of sample inheritance: (1) transferring all the parent's samples to the offspring to be used as prior without evaluating them, and (2) reevaluating the parent's best samples on the offspring. Both are compared to a baseline without inheritance. Our results show that reevaluation performs best, with prior-based inheritance also outperforming no inheritance. Analysis reveals that while the learning budget is too low for a single morphology, generational inheritance compensates for this by accumulating learned adaptations across generations. Furthermore, inheritance mainly benefits offspring morphologies that are similar to their parents. Finally, we demonstrate the critical role of the environment, with more challenging environments resulting in more stable walking gaits. Our findings highlight that inheritance mechanisms can boost performance in evolutionary robotics without needing large learning budgets, offering an efficient path toward more capable robot design.
More complex environments may be required to discover benefits of lifetime learning in evolving robots
Dec 11, 2024It is well known that intra-life learning, defined as an additional controller optimization loop, is beneficial for evolving robot morphologies for locomotion. In this work, we investigate this further by comparing it in two different environments: an easy flat environment and a more challenging hills environment. We show that learning is significantly more beneficial in a hilly environment than in a flat environment and that it might be needed to evaluate robots in a more challenging environment to see the benefits of learning.
Offline Skill Generalization via Task and Motion Planning
Nov 24, 2023



This paper presents a novel approach to generalizing robot manipulation skills by combining a sampling-based task-and-motion planner with an offline reinforcement learning algorithm. Starting with a small library of scripted primitive skills (e.g. Push) and object-centric symbolic predicates (e.g. On(block, plate)), the planner autonomously generates a demonstration dataset of manipulation skills in the context of a long-horizon task. An offline reinforcement learning algorithm then extracts a policy from the dataset without further interactions with the environment and replaces the scripted skill in the existing library. Refining the skill library improves the robustness of the planner, which in turn facilitates data collection for more complex manipulation skills. We validate our approach in simulation, on a block-pushing task. We show that the proposed method requires less training data than conventional reinforcement learning methods. Furthermore, interaction with the environment is collision-free because of the use of planner demonstrations, making the approach more amenable to persistent robot learning in the real world.
Open-ended search for environments and adapted agents using MAP-Elites
May 02, 2023Creatures in the real world constantly encounter new and diverse challenges they have never seen before. They will often need to adapt to some of these tasks and solve them in order to survive. This almost endless world of novel challenges is not as common in virtual environments, where artificially evolving agents often have a limited set of tasks to solve. An exception to this is the field of open-endedness where the goal is to create unbounded exploration of interesting artefacts. We want to move one step closer to creating simulated environments similar to the diverse real world, where agents can both find solvable tasks, and adapt to them. Through the use of MAP-Elites we create a structured repertoire, a map, of terrains and virtual creatures that locomote through them. By using novelty as a dimension in the grid, the map can continuously develop to encourage exploration of new environments. The agents must adapt to the environments found, but can also search for environments within each cell of the grid to find the one that best fits their set of skills. Our approach combines the structure of MAP-Elites, which can allow the virtual creatures to use adjacent cells as stepping stones to solve increasingly difficult environments, with open-ended innovation. This leads to a search that is unbounded, but still has a clear structure. We find that while handcrafted bounded dimensions for the map lead to quicker exploration of a large set of environments, both the bounded and unbounded approach manage to solve a diverse set of terrains.
Evolution of linkages for prototyping of linkage based robots
May 02, 2023Prototyping robotic systems is a time consuming process. Computer aided design, however, might speed up the process significantly. Quality-diversity evolutionary approaches optimise for novelty as well as performance, and can be used to generate a repertoire of diverse designs. This design repertoire could be used as a tool to guide a designer and kick-start the rapid prototyping process. This paper explores this idea in the context of mechanical linkage based robots. These robots can be a good test-bed for rapid prototyping, as they can be modified quickly for swift iterations in design. We compare three evolutionary algorithms for optimising 2D mechanical linkages: 1) a standard evolutionary algorithm, 2) the multi-objective algorithm NSGA-II, and 3) the quality-diversity algorithm MAP-Elites. Some of the found linkages are then realized on a physical hexapod robot through a prototyping process, and tested on two different floors. We find that all the tested approaches, except the standard evolutionary algorithm, are capable of finding mechanical linkages that creates a path similar to a specified desired path. However, the quality-diversity approaches that had the length of the linkage as a behaviour descriptor were the most useful when prototyping. This was due to the quality-diversity approaches having a larger variety of similar designs to choose from, and because the search could be constrained by the behaviour descriptors to make linkages that were viable for construction on our hexapod platform.
Co-optimising Robot Morphology and Controller in a Simulated Open-Ended Environment
Apr 07, 2021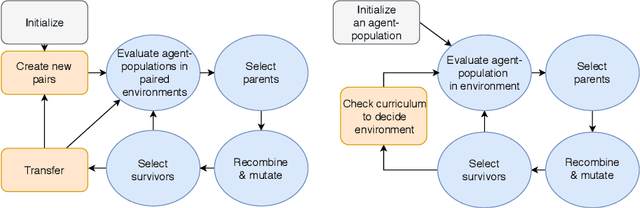


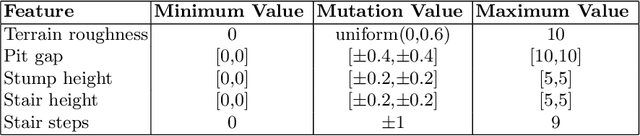
Designing robots by hand can be costly and time consuming, especially if the robots have to be created with novel materials, or be robust to internal or external changes. In order to create robots automatically, without the need for human intervention, it is necessary to optimise both the behaviour and the body design of the robot. However, when co-optimising the morphology and controller of a locomoting agent the morphology tends to converge prematurely, reaching a local optimum. Approaches such as explicit protection of morphological innovation have been used to reduce this problem, but it might also be possible to increase exploration of morphologies using a more indirect approach. We explore how changing the environment, where the agent locomotes, affects the convergence of morphologies. The agents' morphologies and controllers are co-optimised, while the environments the agents locomote in are evolved open-endedly with the Paired Open-Ended Trailblazer (POET). We compare the diversity, fitness and robustness of agents evolving in environments generated by POET to agents evolved in handcrafted curricula of environments. Our agents each contain of a population of individuals being evolved with a genetic algorithm. This population is called the agent-population. We show that agent-populations evolving in open-endedly evolving environments exhibit larger morphological diversity than agent-populations evolving in hand crafted curricula of environments. POET proved capable of creating a curriculum of environments which encouraged both diversity and quality in the populations. This suggests that POET may be capable of reducing premature convergence in co-optimisation of morphology and controllers.
MAP-Elites enables Powerful Stepping Stones and Diversity for Modular Robotics
Dec 08, 2020

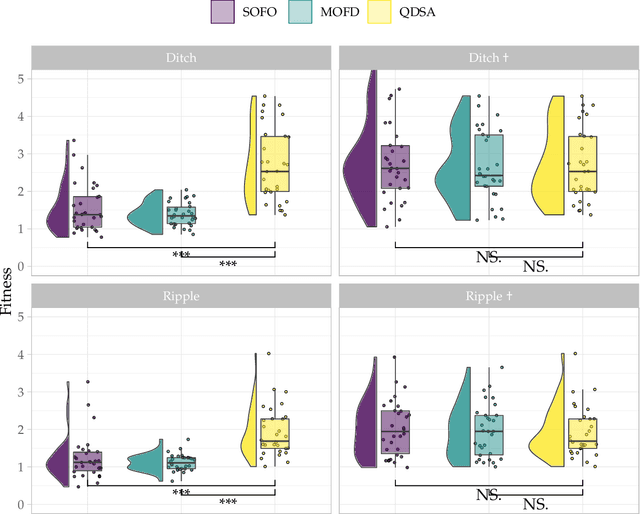

In modular robotics, modules can be reconfigured to change the morphology of the robot, making it able to adapt for specific tasks. However, optimizing both the body and control is a difficult challenge due to the intricate relationship between fine-tuning control and morphological changes that can invalidate such optimizations. To solve this challenge we compare three different Evolutionary Algorithms on their capacity to optimize morphologies in modular robotics. We compare two objective-based search algorithms, with MAP-Elites. To understand the benefit of diversity we transition the evolved populations into two difficult environments to see if diversity can have an impact on solving complex environments. In addition, we analyse the genealogical ancestry to shed light on the notion of stepping stones as key to enable high performance. The results show that MAP-Elites is capable of evolving the highest performing solutions in addition to generating the largest morphological diversity. For the transition between environments the results show that MAP-Elites is better at regaining performance by promoting morphological diversity. With the analysis of genealogical ancestry we show that MAP-Elites produces more diverse and higher performing stepping stones than the other objective-based search algorithms. Transitioning the populations to more difficult environments show the utility of morphological diversity, while the analysis of stepping stones show a strong correlation between diversity of ancestry and maximum performance on the locomotion task. The paper shows the advantage of promoting diversity for solving a locomotion task in different environments for modular robotics. By showing that the quality and diversity of stepping stones in Evolutionary Algorithms is an important factor for overall performance we have opened up a new area of analysis and results.
Quality and Diversity in Evolutionary Modular Robotics
Aug 05, 2020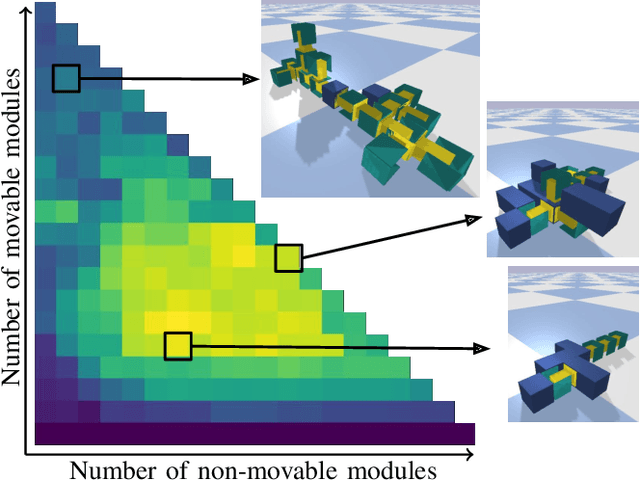
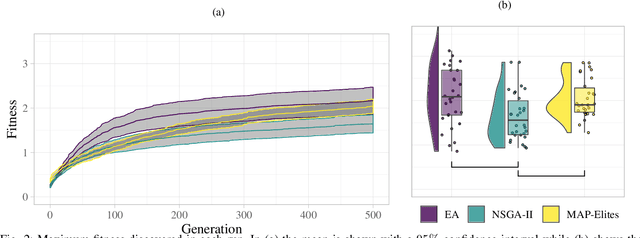
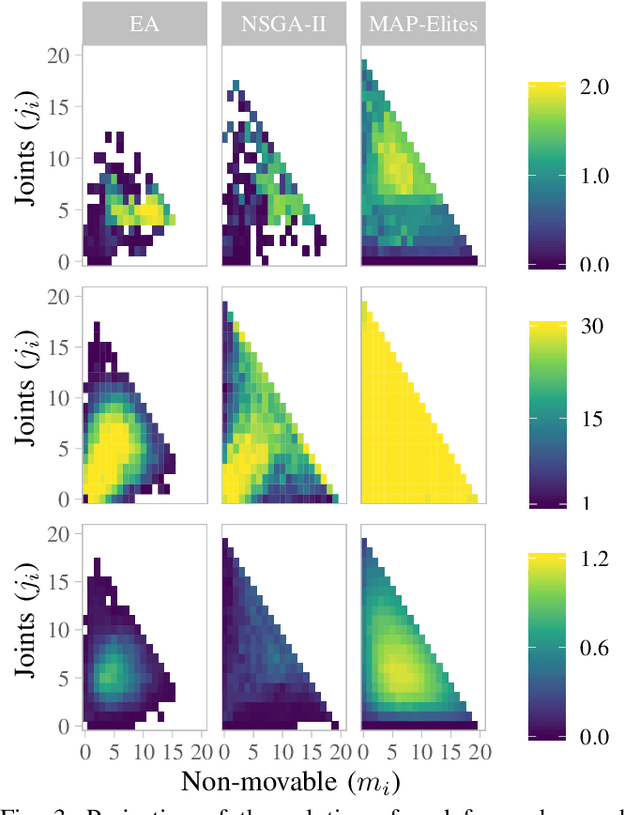
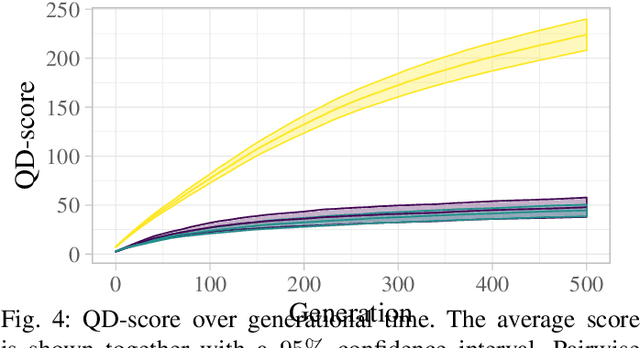
In Evolutionary Robotics a population of solutions is evolved to optimize robots that solve a given task. However, in traditional Evolutionary Algorithms, the population of solutions tends to converge to local optima when the problem is complex or the search space is large, a problem known as premature convergence. Quality Diversity algorithms try to overcome premature convergence by introducing additional measures that reward solutions for being different while not necessarily performing better. In this paper we compare a single objective Evolutionary Algorithm with two diversity promoting search algorithms; a Multi-Objective Evolutionary Algorithm and MAP-Elites a Quality Diversity algorithm, for the difficult problem of evolving control and morphology in modular robotics. We compare their ability to produce high performing solutions, in addition to analyze the evolved morphological diversity. The results show that all three search algorithms are capable of evolving high performing individuals. However, the Quality Diversity algorithm is better adept at filling all niches with high-performing solutions. This confirms that Quality Diversity algorithms are well suited for evolving modular robots and can be an important means of generating repertoires of high performing solutions that can be exploited both at design- and runtime.
Self-Adapting Goals Allow Transfer of Predictive Models to New Tasks
May 15, 2019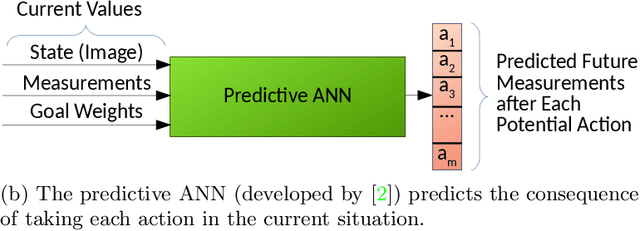

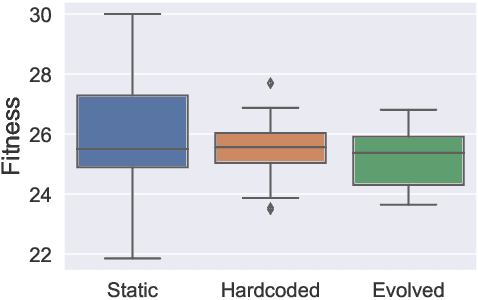
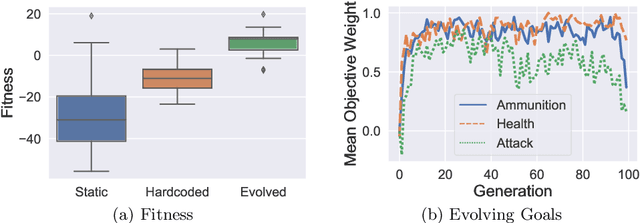
A long-standing challenge in Reinforcement Learning is enabling agents to learn a model of their environment which can be transferred to solve other problems in a world with the same underlying rules. One reason this is difficult is the challenge of learning accurate models of an environment. If such a model is inaccurate, the agent's plans and actions will likely be sub-optimal, and likely lead to the wrong outcomes. Recent progress in model-based reinforcement learning has improved the ability for agents to learn and use predictive models. In this paper, we extend a recent deep learning architecture which learns a predictive model of the environment that aims to predict only the value of a few key measurements, which are be indicative of an agent's performance. Predicting only a few measurements rather than the entire future state of an environment makes it more feasible to learn a valuable predictive model. We extend this predictive model with a small, evolving neural network that suggests the best goals to pursue in the current state. We demonstrate that this allows the predictive model to transfer to new scenarios where goals are different, and that the adaptive goals can even adjust agent behavior on-line, changing its strategy to fit the current context.