 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Error of Invariant Classifiers
Jul 02, 2017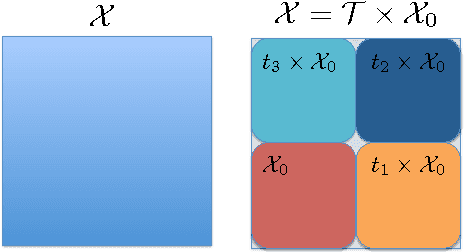
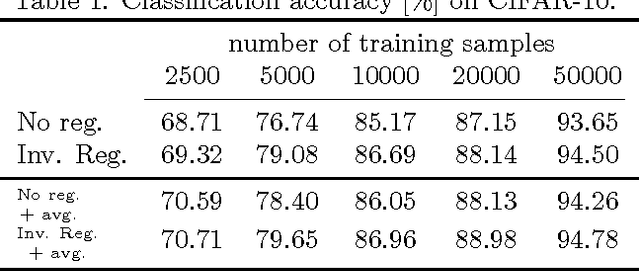
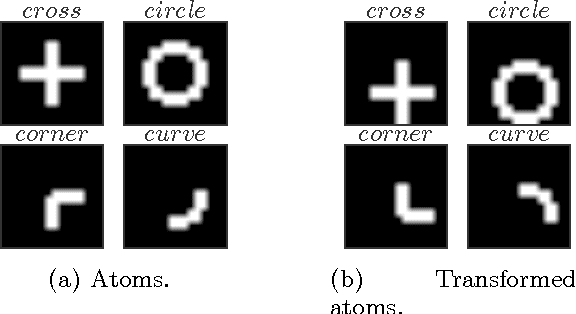
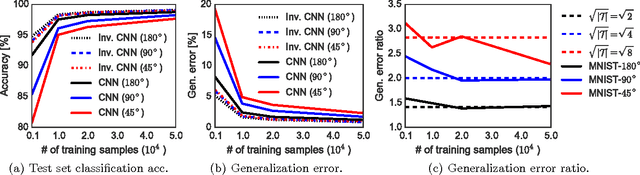
This paper studies the generalization error of invariant classifiers. In particular, we consider the common scenario where the classification task is invariant to certain transformations of the input, and that the classifier is constructed (or learned) to be invariant to these transformations. Our approach relies on factoring the input space into a product of a base space and a set of transformations. We show that whereas the generalization error of a non-invariant classifier is proportional to the complexity of the input space, the generalization error of an invariant classifier is proportional to the complexity of the base space. We also derive a set of sufficient conditions on the geometry of the base space and the set of transformations that ensure that the complexity of the base space is much smaller than the complexity of the input space. Our analysis applies to general classifiers such as convolutional neural networks. We demonstrate the implications of the developed theory for such classifiers with experiments on the MNIST and CIFAR-10 datasets.
* Accepted to AISTATS. This version has updated references
Learning to Succeed while Teaching to Fail: Privacy in Closed Machine Learning Systems
May 23, 2017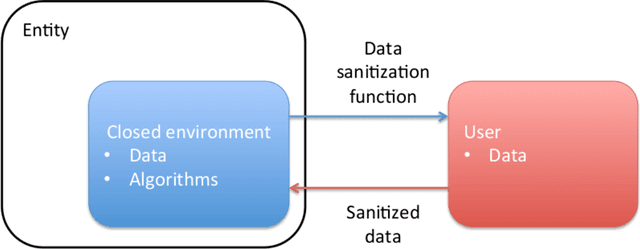



Security, privacy, and fairness have become critical in the era of data science and machine learning. More and more we see that achieving universally secure, private, and fair systems is practically impossible. We have seen for example how generative adversarial networks can be used to learn about the expected private training data; how the exploitation of additional data can reveal private information in the original one; and how what looks like unrelated features can teach us about each other. Confronted with this challenge, in this paper we open a new line of research, where the security, privacy, and fairness is learned and used in a closed environment. The goal is to ensure that a given entity (e.g., the company or the government), trusted to infer certain information with our data, is blocked from inferring protected information from it. For example, a hospital might be allowed to produce diagnosis on the patient (the positive task), without being able to infer the gender of the subject (negative task). Similarly, a company can guarantee that internally it is not using the provided data for any undesired task, an important goal that is not contradicting the virtually impossible challenge of blocking everybody from the undesired task. We design a system that learns to succeed on the positive task while simultaneously fail at the negative one, and illustrate this with challenging cases where the positive task is actually harder than the negative one being blocked. Fairness, to the information in the negative task, is often automatically obtained as a result of this proposed approach. The particular framework and examples open the door to security, privacy, and fairness in very important closed scenarios, ranging from private data accumulation companies like social networks to law-enforcement and hospitals.
Robust Large Margin Deep Neural Networks
May 23, 2017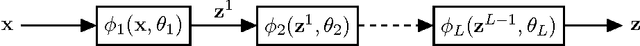
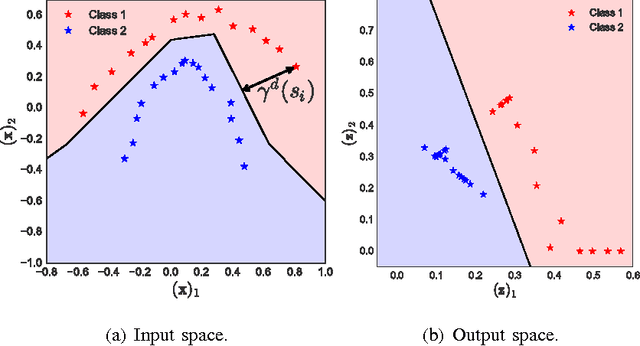
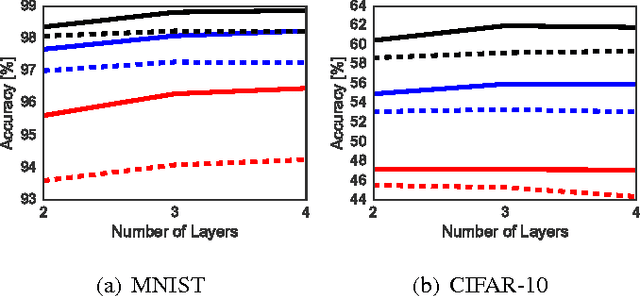
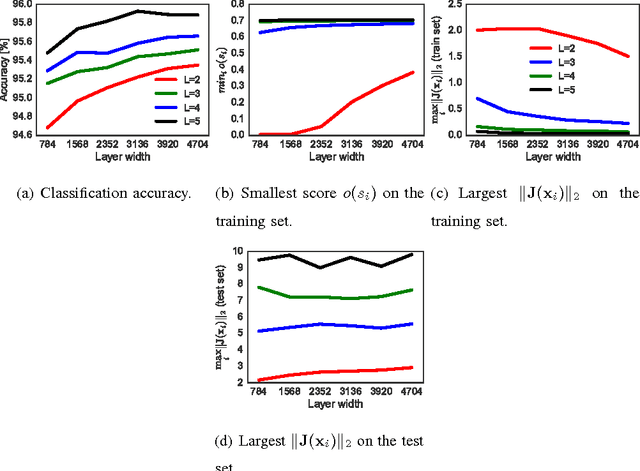
The generalization error of deep neural networks via their classification margin is studied in this work. Our approach is based on the Jacobian matrix of a deep neural network and can be applied to networks with arbitrary non-linearities and pooling layers, and to networks with different architectures such as feed forward networks and residual networks. Our analysis leads to the conclusion that a bounded spectral norm of the network's Jacobian matrix in the neighbourhood of the training samples is crucial for a deep neural network of arbitrary depth and width to generalize well. This is a significant improvement over the current bounds in the literature, which imply that the generalization error grows with either the width or the depth of the network. Moreover, it shows that the recently proposed batch normalization and weight normalization re-parametrizations enjoy good generalization properties, and leads to a novel network regularizer based on the network's Jacobian matrix. The analysis is supported with experimental results on the MNIST, CIFAR-10, LaRED and ImageNet datasets.
Mismatch in the Classification of Linear Subspaces: Sufficient Conditions for Reliable Classification
Feb 18, 2016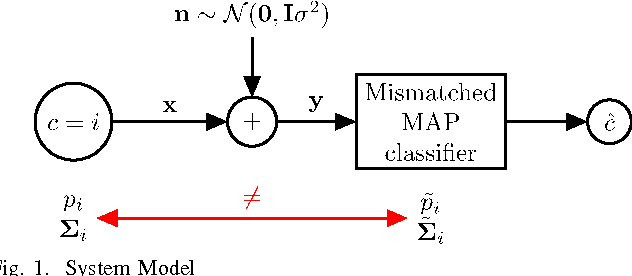
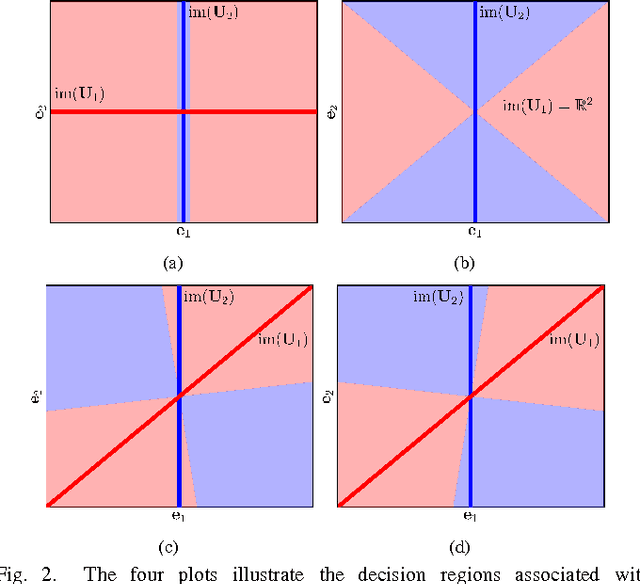
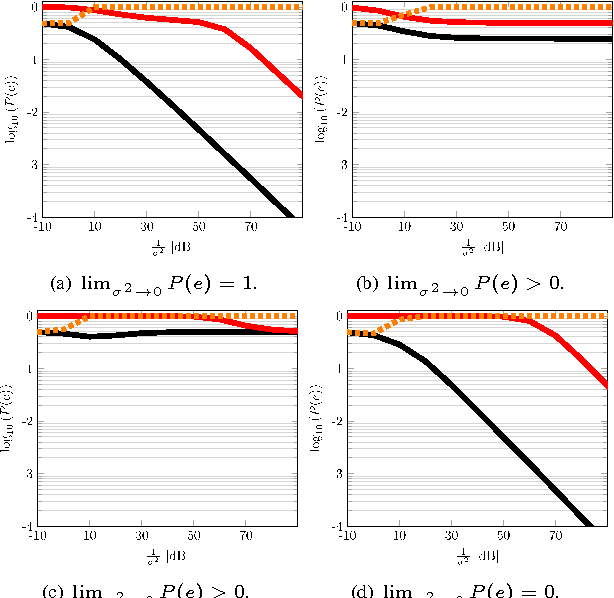
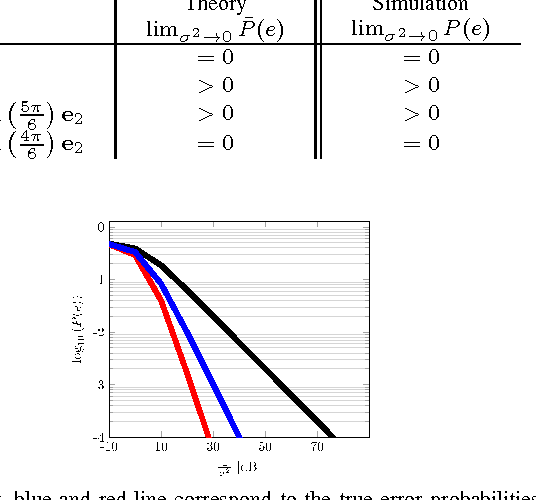
This paper considers the classification of linear subspaces with mismatched classifiers. In particular, we assume a model where one observes signals in the presence of isotropic Gaussian noise and the distribution of the signals conditioned on a given class is Gaussian with a zero mean and a low-rank covariance matrix. We also assume that the classifier knows only a mismatched version of the parameters of input distribution in lieu of the true parameters. By constructing an asymptotic low-noise expansion of an upper bound to the error probability of such a mismatched classifier, we provide sufficient conditions for reliable classification in the low-noise regime that are able to sharply predict the absence of a classification error floor. Such conditions are a function of the geometry of the true signal distribution, the geometry of the mismatched signal distributions as well as the interplay between such geometries, namely, the principal angles and the overlap between the true and the mismatched signal subspaces. Numerical results demonstrate that our conditions for reliable classification can sharply predict the behavior of a mismatched classifier both with synthetic data and in a motion segmentation and a hand-written digit classification applications.