 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Geometric Learning with Monotonicity Constraints for Alzheimer's Disease Progression
Oct 05, 2023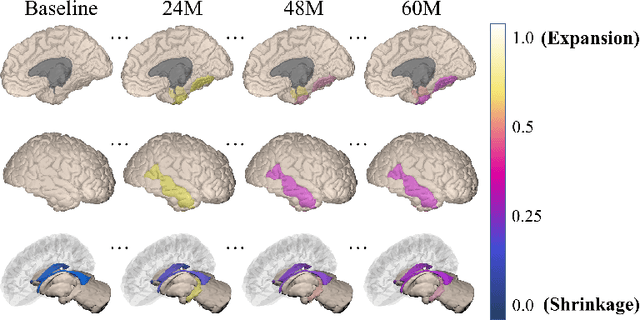
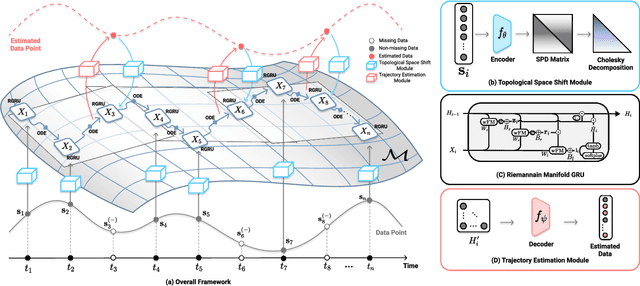
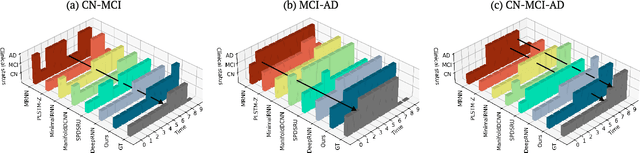
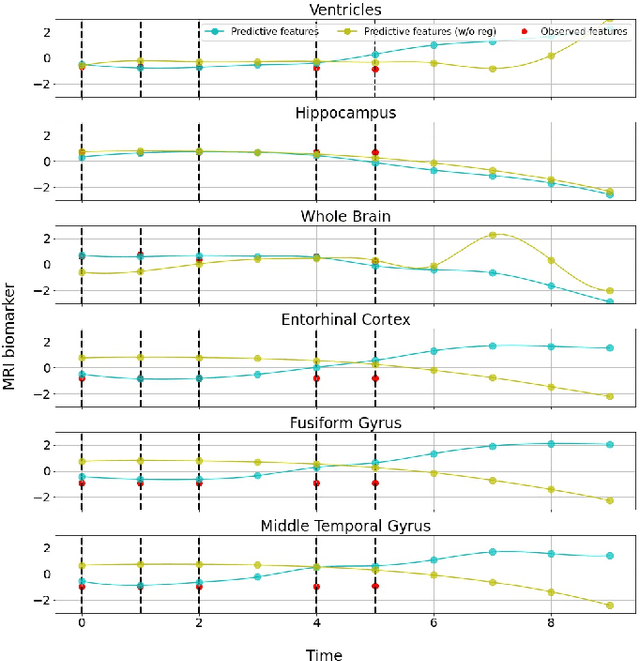
Alzheimer's disease (AD) is a devastating neurodegenerative condition that precedes progressive and irreversible dementia; thus, predicting its progression over time is vital for clinical diagnosis and treatment. Numerous studies have implemented structural magnetic resonance imaging (MRI) to model AD progression, focusing on three integral aspects: (i) temporal variability, (ii) incomplete observations, and (iii) temporal geometric characteristics. However, deep learning-based approaches regarding data variability and sparsity have yet to consider inherent geometrical properties sufficiently. The ordinary differential equation-based geometric modeling method (ODE-RGRU) has recently emerged as a promising strategy for modeling time-series data by intertwining a recurrent neural network and an ODE in Riemannian space. Despite its achievements, ODE-RGRU encounters limitations when extrapolating positive definite symmetric metrics from incomplete samples, leading to feature reverse occurrences that are particularly problematic, especially within the clinical facet. Therefore, this study proposes a novel geometric learning approach that models longitudinal MRI biomarkers and cognitive scores by combining three modules: topological space shift, ODE-RGRU, and trajectory estimation. We have also developed a training algorithm that integrates manifold mapping with monotonicity constraints to reflect measurement transition irreversibility. We verify our proposed method's efficacy by predicting clinical labels and cognitive scores over time in regular and irregular settings. Furthermore, we thoroughly analyze our proposed framework through an ablation study.
Fine-Grained Attention for Weakly Supervised Object Localization
Apr 11, 2021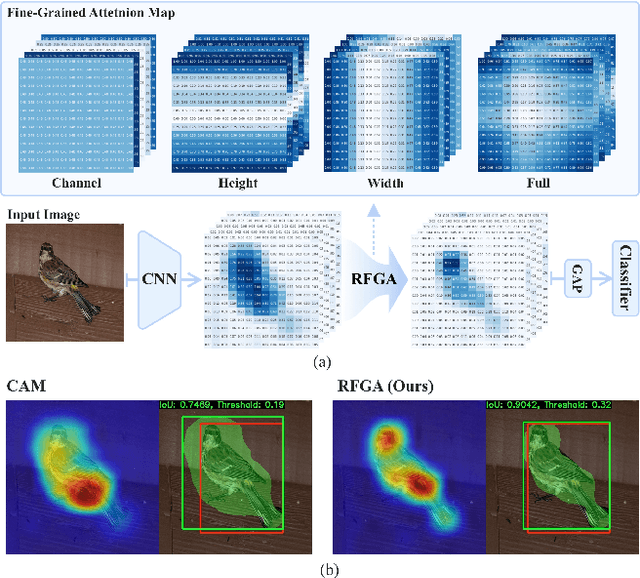
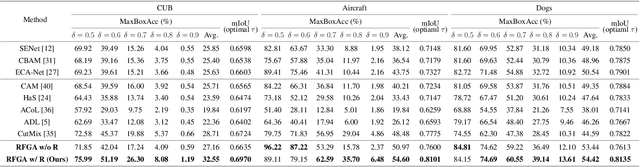
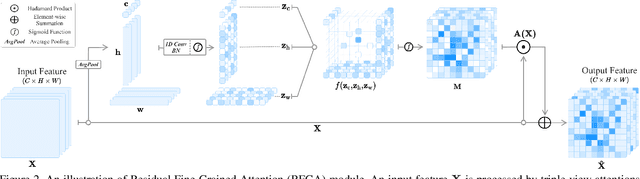
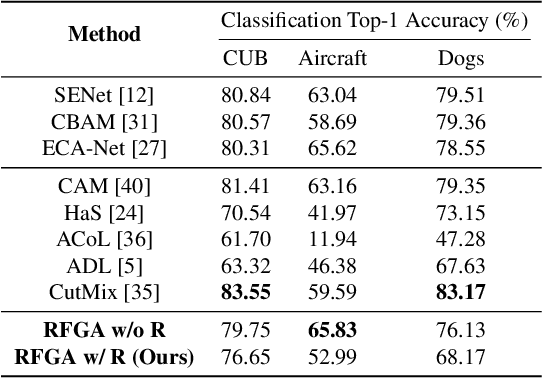
Although recent advances in deep learning accelerated an improvement in a weakly supervised object localization (WSOL) task, there are still challenges to identify the entire body of an object, rather than only discriminative parts. In this paper, we propose a novel residual fine-grained attention (RFGA) module that autonomously excites the less activated regions of an object by utilizing information distributed over channels and locations within feature maps in combination with a residual operation. To be specific, we devise a series of mechanisms of triple-view attention representation, attention expansion, and feature calibration. Unlike other attention-based WSOL methods that learn a coarse attention map, having the same values across elements in feature maps, our proposed RFGA learns fine-grained values in an attention map by assigning different attention values for each of the elements. We validated the superiority of our proposed RFGA module by comparing it with the recent methods in the literature over three datasets. Further, we analyzed the effect of each mechanism in our RFGA and visualized attention maps to get insights.