 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Attention for Weakly Supervised Object Localization
Paper and Code
Apr 11, 2021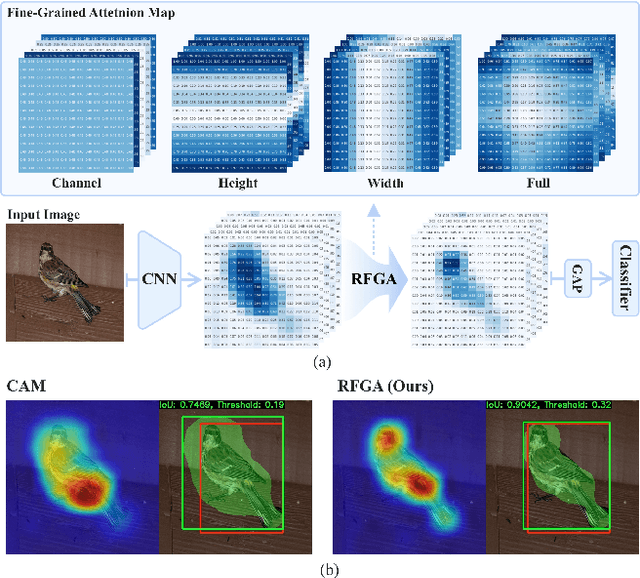
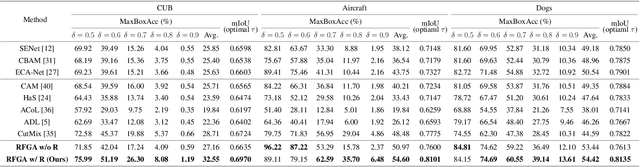
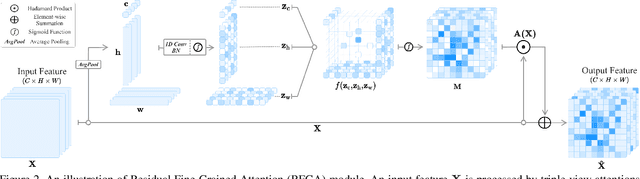
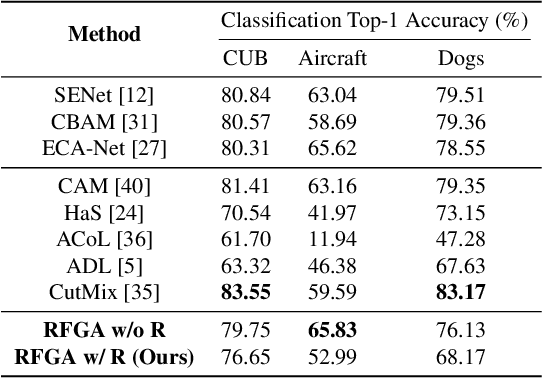
Although recent advances in deep learning accelerated an improvement in a weakly supervised object localization (WSOL) task, there are still challenges to identify the entire body of an object, rather than only discriminative parts. In this paper, we propose a novel residual fine-grained attention (RFGA) module that autonomously excites the less activated regions of an object by utilizing information distributed over channels and locations within feature maps in combination with a residual operation. To be specific, we devise a series of mechanisms of triple-view attention representation, attention expansion, and feature calibration. Unlike other attention-based WSOL methods that learn a coarse attention map, having the same values across elements in feature maps, our proposed RFGA learns fine-grained values in an attention map by assigning different attention values for each of the elements. We validated the superiority of our proposed RFGA module by comparing it with the recent methods in the literature over three datasets. Further, we analyzed the effect of each mechanism in our RFGA and visualized attention maps to get insights.